《深入浅出Greenplum内核》系列直播已经顺利完结啦!全部十场的视频内容可以前往Greenplum中文社区B站频道观看相关视频,相关PPT均已上传Greenplum中文社区网站(cn.greenplum.org)的下载页面,欢迎获取!现在让我们来回顾一下完结场活动《揭秘Greenplum恢复(Recovery)系统》的精华内容。
视频如和文字部分有出入,请以文字为准
https://www.bilibili.com/video/BV1Ft4y1B74e
今天我们将给大家详细解析Greenplum恢复系统。恢复系统对于一个数据库系统是必不可少的一部分。本文将围绕4个部分进行讲述,本文内容如非特殊声明,均基于Greenplum 6。
- 恢复系统概述
- 预写式日志简介
- 单节点系统恢复
- 分布式系统恢复
首先我们会对恢复系统相关概念和预写式日志进行介绍,接着会介绍单点式的恢复系统,Greenplum在这一点上与PostgreSQL很接近,但由于Greenplum是个分布式数据库系统,因此在例如两阶段恢复等地方和PostgreSQL会有不同之处。最后我们会介绍分布式系统恢复,Greenplum作为分布式数据库系统,除了单个节点的恢复,也需要保证整个集群的一致性,本文将着重介绍这一部分。
一、系统恢复概述
在现实生活中,数据库系统可能会遇到各种各样的故障。常见的故障大致可以被分为三类:
- 硬件故障。例如异常断电、磁盘访问出现故障,网卡出问题等,此时,就需要针对具体情况进行恢复。
- 系统故障。即软件故障,这里和数据库没有太大关系,原因有多种,有可能是内核崩溃,依赖库bug等情况导致的。这一块也不是我们今天重点要介绍的内容。
- Postgres进程异常退出。例如OOM,bug,保护性PANIC等。这将是本文着重介绍的故障类型。在遇到这种故障时,如果是除postmaster之外的单点进程退出,整个单点Postgres会进行重启。
PostgreSQL和Greenplum的恢复系统都是基于WAL,即预写式日志。所谓预写式日志是指事务提交先写日志,事务引起的数据修改通常可以滞后,Greenplum的segment上事务提交时日志同步到从节点后才认为成功。一些表数据的页面修改可以稍后完成,从而保证了较好的性能。
在单节点上,恢复系统通常是从Checkpoint日志中redo值所代表的的位置开始重放日志。通常情况下会读取最新的checkpoint中的日志,但在某些情况下会需要读取上次的checkpoint中的日志。
Greenplum作为一个分布式数据库系统,需要分布式事务管理器和分布式恢复,而Master节点充当了这两个角色,保证整个集群的数据全局一致性。在数据恢复系统中某些场景下,需要进行人工干预:例如一些产品bug中,startup进程出现异常等情况,但这种场景较少见。如果出现需要人工干预的场景,商业用户可以寻求原厂的支持。
二、预写式日志简介
首先我们来看一个简单Insert的预写式日志的例子。
postgres=# insert into t1 select generate_series(1,10);
INSERT 0 10上面的Insert语句中,写入了十个tuple,被分布到各个节点上,这是一个典型的两阶段事务。我们以某一个Primary为例,以完成时间顺序看这个两阶段事务日志写入情况(下为pg_xlogdump解析日志输出结果)。
- 第一个Primary节点(其余 Primary节点类似)
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F02A0, prev 0/0C0F0238, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/6
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F02E0, prev 0/0C0F02A0, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/7
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F0320, prev 0/0C0F02E0, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/8
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F0360, prev 0/0C0F0320, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/9
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F03A0, prev 0/0C0F0360, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/10
rmgr: Transaction len (rec/tot): 376/ 408, tx: 721, lsn: 0/0C0F03E0, prev 0/0C0F03A0, bkp: 0000, desc: prepare- Master节点
rmgr: Transaction len (rec/tot): 84/ 116, tx: 0, lsn: 0/0C0FC9C8, prev 0/0C0FC988, bkp: 0000, desc: distributed commit 2021-01-12 16:29:12.085955 CST gid = 4129264608-0000032766 gid = 1610432654-0000000012, gxid = 12
- 第一个Primary节点(其余priamry节点类似)
rmgr: Transaction len (rec/tot): 72/ 104, tx: 0, lsn: 0/0C0F0578, prev 0/0C0F03E0, bkp: 0000, desc: commit prepared 721: 2021-01-12 16:29:12.086621 CST gid = 139787424-0000000000 gid = 1610432654-0000000012 gxid = 12- Master 节点
rmgr: Transaction len (rec/tot): 28/ 60, tx: 0, lsn: 0/0C0FCA40, prev 0/0C0FC9C8, bkp: 0000, desc: distributed forget gid = 1610432654-0000000012, gxid = 12两阶段事务的参与者prepare后,协调器会发commit prepare给所有的节点。Master的节点接收到所有节点的prepare信息后,如果其中一个节点prepare不成功,就会给所有的节点发prepare回滚的指令。如果所有的节点prepare成功,Master会在本地写一个distributed commit日志,所有的primary节点才会发起两阶段提交,因此在上面的例子中,我们会看到 Primary节点上会有一个commit prepared的日志。最后master节点上会写一个distributed forget的日志。
虽然整个流程较为简单,但有很多细节需要考量。这里我们可以思考三个问题:
问题1:为什么master先做distributed commit再发起segment上两阶段提交?
问题2:PREPARE日志需要同步到从端才告诉master PREPARE成功吗?
问题3:为什么有一个distributed forget日志? 需要吗?
大家可以带着问题看文章,这三个问题将在后面的内容中进行解答。
1. 预写式日志
预写式日志通常是指在事务提交之前写日志,提交时候刷盘日志,根据主从设置来规范提交完成。Greenplum较为严格,要求远端刷新,例如在事务提交时,必须要求mirror刷盘成功才认为事务成功。当然这样或多或少会影响一些性能,但是很好保证了数据的可靠性。
Greenplum基于redo日志。日志会一直增长,但系统会自动删除回收一些无用的日志文件,这一操作主要发生在checkpoint的时候。checkpoint一般有两种情况,一种是主动的,主动运行checkpoint的命令,一种是被动的,checkpoint进程会每隔一段时间自动运行checkpoint。
WAL主要应用于单机恢复以及流式复制。流式复制主要用于主从方案高可用,相关内容在上一次活动中已详细介绍,从内部来看流失复制也可以被看作是一种archive recovery。
Greenplum的日志文件大小为64兆, PostgreSQL缺省是16兆,每个文件内部以32K大小为一个日志页面,这里需要注意不要和Buffer页面大小混淆。日志位置以LSN(Log Sequence Number)记录位置,例如:0/57920DE8 实际是一个64bit数。日志文件内容除了日志还包含一些元数据,例如日志页面头信息等。
2.预写式日志格式
下图为一个典型的预写式日志格式。
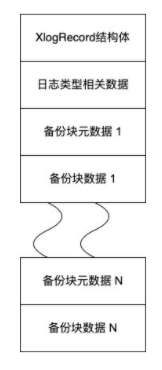
其中备份块数据与Full Page Write相关,这一点我们会在后文中介绍。
- 日志头信息
首先我们看一下日志头信息。具体可以看下面的表格,下面信息可以用于进行日志正确性的检查。

- 预写式日志文件
我们现在进入Greenplum的任何一个节点,例如Segment或Master节点,再进入pg_xlog目录来看一下有哪些文件。下图大小64M的是日志文件。
drwx------ 2 pguo 6 Mar 15 22:30 archive_status
-rw------- 1 pguo 67108864 Mar 15 22:35 000000010000000000000002
-rw------- 1 pguo 67108864 Mar 15 22:35 000000010000000000000003
-rw------- 1 pguo 41 Mar 15 22:35 00000002.history
-rw------- 1 pguo 67108864 Mar 15 22:36 000000020000000000000003
-rw------- 1 pguo 83 Mar 15 22:37 00000003.history
-rw------- 1 pguo 67108864 Mar 15 22:44 000000030000000000000003
-rw------- 1 pguo 67108864 Mar 15 22:45 000000030000000000000004日志文件名格式:
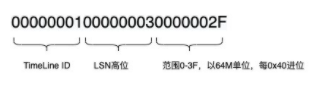
Greenplum上记录了每次TimeLine ID切换时候的LSN信息。TimeLine ID记录的各种“分叉”,比如主从切换的时候。长数字串文件名的是日志文件。
- Greenplum支持的资源管理列表
Greenplum支持的资源管理列表如下:
PG_RMGR(RM_XLOG_ID, "XLOG", xlog_redo, xlog_desc, NULL, NULL)
PG_RMGR(RM_XACT_ID, "Transaction", xact_redo, xact_desc, NULL, NULL)
PG_RMGR(RM_SMGR_ID, "Storage", smgr_redo, smgr_desc, NULL, NULL)
PG_RMGR(RM_CLOG_ID, "CLOG", clog_redo, clog_desc, NULL, NULL)
PG_RMGR(RM_DBASE_ID, "Database", dbase_redo, dbase_desc, NULL, NULL)
PG_RMGR(RM_TBLSPC_ID, "Tablespace", tblspc_redo, tblspc_desc, NULL, NULL)
PG_RMGR(RM_MULTIXACT_ID, "MultiXact", multixact_redo, multixact_desc, NULL, NULL)
PG_RMGR(RM_RELMAP_ID, "RelMap", relmap_redo, relmap_desc, NULL, NULL)
PG_RMGR(RM_STANDBY_ID, "Standby", standby_redo, standby_desc, NULL, NULL)
PG_RMGR(RM_HEAP2_ID, "Heap2", heap2_redo, heap2_desc, NULL, NULL)
PG_RMGR(RM_HEAP_ID, "Heap", heap_redo, heap_desc, NULL, NULL)
PG_RMGR(RM_BTREE_ID, "Btree", btree_redo, btree_desc, NULL, NULL)
PG_RMGR(RM_HASH_ID, "Hash", hash_redo, hash_desc, NULL, NULL)
PG_RMGR(RM_GIN_ID, "Gin", gin_redo, gin_desc, gin_xlog_startup, gin_xlog_cleanup)
PG_RMGR(RM_GIST_ID, "Gist", gist_redo, gist_desc, gist_xlog_startup, gist_xlog_cleanup)
PG_RMGR(RM_SEQ_ID, "Sequence", seq_redo, seq_desc, NULL, NULL)
PG_RMGR(RM_SPGIST_ID, "SPGist", spg_redo, spg_desc, spg_xlog_startup, spg_xlog_cleanup)
PG_RMGR(RM_BITMAP_ID, "Bitmap", bitmap_redo, bitmap_desc, NULL, NULL)
PG_RMGR(RM_DISTRIBUTEDLOG_ID, "DistributedLog", DistributedLog_redo, DistributedLog_desc, NULL, NULL)
PG_RMGR(RM_APPEND_ONLY_ID, "Appendonly", appendonly_redo, appendonly_desc, NULL, NULL)三、单节点系统恢复
1.单节点恢复(Postgres进程异常退出)
接下来我们看一下单节点系统恢复。上文中我们提到了它是由startup进程完成的,主要目的是确保恢复之后整个单机的数据正确工作,即数据的一致性可以得到保证。在Greenplum上事务提交或者回滚的事务修改需要确保落地,而不影响数据的一致性。
- Postmaster退出:外部组件重新启动单点服务。比如FTS自动标记节点为’d’后通过gprecoverseg完成。
- Postgres后端进程异常退出,Postmaster自动重启后端, segment上如果重启足够快FTS不会标记这个节点为’d’。否则gprecoverseg恢复。
- 不论如何,postgres重启后,恢复系统会尽力先启动以确保数据库在正确状态,方便gprecoverseg增量恢复。
- 增量恢复失败(不一定是产品bug)可以改用全量恢复(gprecoverseg –F,慢,但是基本不会失败)
- 全量恢复失败:仔细看清原因,修复,绕过,重试,必要时候找对应的商业支持(硬件、OS、数据库)
2. Master/Standby
说完了segment上的恢复机制,现在我们来看一下Master/Standby上恢复机制。
- gpdb 7开始支持master (master改叫coordinator)节点自动切换。
- gpdb6或者以前版本用外部工具管理切换和激活standby。
- 也可以用相关工具重建一个新的standby。
3. 单节点恢复过程实现
前文已经提到Startup进程是恢复进程。Postmaster最早启动(除了logger进程)startup进程,不允许libpq连接(正常或者utility mode)。恢复时是依赖pg_control文件和日志文件,其中pg_control是Greenplum和PostgreSQL最核心的恢复系统文件,它记录了很多日志文件系统的元数据。
核心函数是StartupXLOG():
- 基本原理是从一个日志起点循环读取日志和重放。
较为典型的是读取pg_control文件中的checkpoint LSN,在根据这个值在日志中读取checkpoint日志的redo值作为重放起点。
- 循环什么时候退出?
对主(Master/Primary)节点来说做完所有日志重放就可以结束循环最后startup进程退出。
对从节点循环不会退出,一直等待主节点的日志流数据传输,除非被promote(主从切换)或者出错。
- 整个函数还有大量各种细节分支
比如:unlogged表truncate,replication slot处理等。这里将不做不赘述,感兴趣的小伙伴可以给我们留言,我们可以在后续的公开课中细讲。
- 函数中包含Greenplum特有的分布式相关日志的处理。
- Startup进程如果出错,一般会比较复杂,需要小心处理。
如果其对应的主或对应的从节点数据库没问题,即使这个节点有问题也可以gprecoverseg恢复。
- 慎用pg_resetxlog工具。
社群里有看到社区的小伙伴使用这个工具,需要提醒大家慎用。使用此工具可能会造成数据不一致,因此我们不推荐使用。一般在Segment和Master节点均出现问题,数据库已经无法恢复时,才会考虑使用这个工具。
4. 单节点恢复过程实现(续)
在上一小节中,我们了解了单节点恢复过程实现的一些细节,那我们如何定义重放循环结束呢?一般在以下几种情景下:
- 日志格式检查发现已无合法日志(参见日志头数据结构),比如在主节点
- 如果日志来源是在进行中的流复制,循环一直不结束,比如从节点。直到出错或者从主切换,跳出循环,从变成主。
那如何定义mirror节点呢?
在Greenplum 6版本中,在Mirror的Data目录下,我们可以看到名为recovery.conf的文件,记录了如何连接主节点的信息。这一方式仅针对Greenplum 6, 在Greenplum 7中会有所改动。
$ cat recovery.conf
standby_mode = 'on'
primary_conninfo = 'user=pguo host=host67 port=6002 sslmode=prefer sslcompression=1 krbsrvname=postgres application_name=gp_walreceiver'
primary_slot_name = 'internal_wal_replication_slot'5. Full Page Write
下面我们来介绍一下Full Page Write,前面在介绍日志的时候,我们有提到备份块。在机器断电的时候,存在一个背景进程,会持续不断将数据页面刷到文件中。磁盘具有原子单位,例如很久以前老的磁盘,512字节就是一个原子单位,背景进程在刷数据时可能会出现只刷了一部分数据的情况。此时,如果出现机器断电,数据页面checksum不对页面装载失败,数据的正确性就无法得到保证。
针对这种情况,如果一个日志是Checkpoint.redo后第一次修改了某个页面的日志,可以先把老的整个页面存一份在日志中,确保checkpoint.redo位置开始的重放一定能基于正确的数据页面。
相关判断逻辑:
page = BufferGetPage(rdata->buffer);
/*
* We assume page LSN is first data on *every* page that can be passed to
* XLogInsert, whether it has the standard page layout or not. We don't
* need to take the buffer header lock for PageGetLSN if we hold an
* exclusive lock on the page and/or the relation.
*/
if (holdsExclusiveLock)
*lsn = PageGetLSN(page);
else
*lsn = BufferGetLSNAtomic(rdata->buffer);
if (*lsn <= RedoRecPtr)
{
/* 页面需要被backup */6. 日记的回收和删除
前文我们提到checkpoint会回收删除老旧的日志文件,哪哪些文件不删呢?保留日志文件原则如下:
- 不能删除Checkpoint.redo LSN后的日志。因为这些日志相关数据有可能还未刷盘。
- 最老的Prepared但是还没有Commit/Abort的位置开始的日志不能删。这一点仅限于GP6,在Greenplum7中,在这种场景下,会将prepare日志写入文件中。
- Replication Slot上记录的日志最新同步位置之后的日志不能删。Replication Slot是用于记录主从之间的同步的进度。
- guc wal_keep_segments条件要满足。
- Guc max_slot_wal_keep_size 要满足(6.10.0及以上才有,缺省值不影响)。
老旧的日志文件处理会由checkpoint进程自动完成,应此建议大家尽量不要使用pg_resetxlog工具。
7. gprecoverseg
gprecoveryseg是一个很重要的工具。在需要做主从节点切换,或者需要rebalance回来,都需要使用这个工具。gprecoveryseg有两种模式,一种是增量一种是全量。
这是一个python应用用于集群节点自动恢复。它用于并发多节点的恢复。增量恢复基于pg_rewind工具,全量恢复基于pg_basebackup工具。
如果增量恢复失败就可以改用全量恢复,前提是 primary或者mirror中有一个是正常工作的,如果两个都故障了,那无法进行恢复了。此外问题节点需要完善,如果出现例如节点的文件系统损坏的情况,也无法进行恢复。
四、分布式系统恢复
1. 分布式恢复
分布式数据库需要分布式事务保证全局可见性。在进行查询时,可能会被dispatch到不同的节点上,Query在不同节点上事务启动顺序可能不同,一个全局的顺序才能保证事务看到的顺序是一致的。
Greenplum使用的是经典的两阶段提交的协议,
- 第一阶段完成事务写后发起PREPARE请求并完成,代表如果事务最后如果提交肯定和必须得成功。
- PREPARE完成:日志落盘并同步到从节点(否则发生failover后master发起PREPARE提交会失败。)
- 第二阶段提交:有一个节点提交失败,其他节点提交成功。如果不干预,对可见性影响。
- 比如不能insert 1000个数据报告客户端成功,但是最后查询只能返回900个数据。
在Greenplum 6版本上加入了一种新的被称为一阶段提交的优化,这里将不做赘述,相关细节可以参考相关文章。
分布式恢复主要指master(负责全局分布式事务管理)的dtx recovery进程,确保两阶段提交或者回滚能在所有受影响节点“落地”。做分布式恢复的前提是所有primary节点都能够正常连接访问。
Greenplum不支持显示的PREPARE等Postgres上两阶段相关的Query命令,虽然内部实现还是使用了其相关代码。这些代码在utility mode是可以运行的,但如果不非常熟悉原理,建议不要这么操作。
2. Greenplum 分布式事务相关日志处理
和PostgreSQL有所不同的是,在Greenplum中,Checkpoint日志本身会记录还没有处理(日志重放)完毕的分布式事务相关的元数据,包括master和segment节点上的相关日志。
Greenplum 6早期版本有一些bug会导致某些场景下各种问题,例如
- 因为orphaned事务导致日志文件累积无法被自动删除或者回收
- requested WAL segment *** has already been removed
- Primary的startup进程hang
- Standby报overflow的PANIC
这些问题均已被修复。大家在使用Greenplum过程中如果遇到这些问题,请至少升级到Greenplum 6.12.1或者更高版本。建议大家多关注新版本的release note来获得版本更新资讯。
3. Greenplum 分布式事务相关恢复
Primary如果在两阶段提交 /回滚的阶段时候无法完成, master会重试两阶段提交/回滚事务,等候Primary节点恢复或者主从切换,如果重试超过一定次数:
- 如果是两阶段提交,会PANIC。
- 如果是两阶段回滚,会转交dtx recovery进程继续尝试(避免了PANIC)
那么为什么两阶段回滚不需要PANIC? 这一块早期实现其实是会直接PANIC。PANIC不友好,会导致所有连接断开,单机恢复也需要时间影响服务可用性。两阶段回滚失败不处理也会占用两阶段PREPARE后的资源,例如锁等,但不影响数据全局一致性。因此会转交Dtx recovery process继续回滚。
现在我们再来复习一下前面提到的两阶段提交日志类型。
postgres=# insert into t1 select generate_series(1,10);
INSERT 0 10
第一个Primary节点 (其他Primary节点类似)
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F02A0, prev 0/0C0F0238, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/6
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F02E0, prev 0/0C0F02A0, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/7
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F0320, prev 0/0C0F02E0, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/8
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F0360, prev 0/0C0F0320, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/9
rmgr: Heap len (rec/tot): 31/ 63, tx: 721, lsn: 0/0C0F03A0, prev 0/0C0F0360, bkp: 0000, desc: insert: rel 1663/12812/16391; tid 0/10
rmgr: Transaction len (rec/tot): 376/ 408, tx: 721, lsn: 0/0C0F03E0, prev 0/0C0F03A0, bkp: 0000, desc: prepare
Master节点
rmgr: Transaction len (rec/tot): 84/ 116, tx: 0, lsn: 0/0C0FC9C8, prev 0/0C0FC988, bkp: 0000, desc: distributed commit 2021-01-12 16:29:12.085955 CST gid = 4129264608-0000032766 gid = 1610432654-0000000012, gxid = 12
第一个Primary节点(其他Primary节点类似)
rmgr: Transaction len (rec/tot): 72/ 104, tx: 0, lsn: 0/0C0F0578, prev 0/0C0F03E0, bkp: 0000, desc: commit prepared 721: 2021-01-12 16:29:12.086621 CST gid = 139787424-0000000000 gid = 1610432654-0000000012 gxid = 12
Master 节点
rmgr: Transaction len (rec/tot): 28/ 60, tx: 0, lsn: 0/0C0FCA40, prev 0/0C0FC9C8, bkp: 0000, desc: distributed forget gid = 1610432654-0000000012, gxid = 12前文中我们解释了整个流程,并提出了几个问题,现在让我们来解答一下这几个问题:
问题1:为什么master先做distributed commit再发起segment上两阶段提交?
如果在prepare完成后,直接做commit prepare,此时,如果master postgres进程 PANIC了,重启后prepare进程是abort 还是commit呢?如果没有distributed commit进程就需要确认两阶段进程的状态,这样显然不友好,会对性能产生影响。因此这里需要先写一个本地提交,再做两阶段提交。另外master上不prepare,如果两阶段是会务有master上的写,也需要本地先事务提交。
问题2:PREPARE日志需要同步到从端才告诉master PREPARE成功吗?
防止segment上主从切换后也能完成两阶段事务。PREPARE完成代表如果master发起提交一定要成功。
问题3:为什么有一个distributed forget日志? 需要吗?
如果看到distributed forget日志,就会知道两阶段提交已经成功。如果没有看到,有可能出现segment 上的commit prepare未完成,或未发送到,就需要重新发送两阶段commit prepare的命令
4. Master dtx recovery进程
Master启动会先启动自身单节点恢复过程(startup process),其后启动dtx recovery进程,其功能如下:
- 如果检测到master上有两阶段事务只是DISTRIBUTED_COMMIT但是还没有DISTRIBUTED_FORGET,在segment上发起两阶段提交请求。
- 为什么master先提交本地DISTRIBUTED_COMMIT事务再在segment上发起两阶段提交,作用之一在于此。
- 写入DISTRIBUTED_FORGET日志作用也在于此,这个日志写入时候不立刻刷盘(想想为什么?)所以代价不大。
- 如果在segment上 (Dispatch相关的UDF)检测到还有Prepared的事务但是还没有commit/abort的(所谓orphaned的 两阶段事务),对这种事务发起两阶段回滚请求。
这些步骤完成后master才会接受新的客户端连接。因为这种残留事务影响大比如日志文件累积无法删除,占用资源,Greenplum6上对上述第二种场景会进一步周期性的检查。
orphaned两阶段事务发生的场景主要包括以下几种情况:
- master/standby切换或者master异常重启可能会有(虽然发生概率不那么高)。
- 前面提到的两阶段回滚(Abort Prepared)重试失败了,dtx recovery需要继续尝试回滚这些orphaned事务。
- 产品bug。但现在大部分bug已经被修复,具体可以参考release note。
Dtx recovery进程会一直存在,不会退出。
随着本文的结束,《深入浅出Greenplum内核》系列直播也正式完结啦!我们将在年后为大家带来更多精彩的活动和内容,记得关注我们哦!
《深入浅出Greenplum内核》往期回顾
2. 揭秘!Greenplum并行执行引擎到底是如何工作的?
5. Greenplum MVCC并发控制:严格的一致性与极致的性能
6. 助你掌握数据库排序算法

