7月24日,Greenplum原厂内核研发马洪旭和大家直播分享了《深入浅出Greenplum内核》系列直播的第四期《Greenplum内核揭秘之B树索引》。相关视频已上传至Greenplum中文社区B站频道,点击文章底部“阅读原文”即可观看。本文概括了文章的精华内容,欢迎大家加入技术讨论群和我们交流。
索引是数据库中的重要组件,而B树则是最常见的索引数据结构,同时它也是Greenplum中的默认索引类型。今天我将给大家详细介绍B树索引。本文将涵盖B树的基础知识、B树的存储结构、操作算法、并发控制,相关系统表等知识。
B树的基本知识首先和大家介绍一下B树的基础知识。大家一般在大学的数据结构课程中都学过B树,如今回忆起来,很多人都会问,为什么数据库索引经常会选用b树来实现数据库索引呢?Greenplum的B树索引和我们大学课程中介绍的是否完全一样呢?它的数据结构和算法是不是和课程中介绍的完全一样呢?大家可以思考一下这几个问题,看完这篇文章就能知晓答案。
索引
在开始介绍B树索引之前,先给大家简单介绍一下索引。大家在网上看到的定义往往太过复杂,我自己给他下了一个简单的定义:索引就是能加速一个常规操作的数据结构。为了方便大家的理解,这里我给大家举了一个简单的例子,在用字典时,当我们想查某个词的时候,我们可以选择从这字典从头到尾逐页翻查,可想而知,这样的查询速度非常慢,如果我们使用这本字典附录中的索引,查询速度就会大幅提高。

索引包括本文即将详细介绍的B树索引,另外还有哈希索引和倒排索引。其中哈希索引比较常见,比如一个很简单的程序,里边会执行一个数据查询,查询到的结果都存储到哈希表里,下次再访问的时候,会先到哈希表里,判断数据是否已经存在,如果已经存在,就没有必要再运行这个查询,这就是哈希索引。
倒排索引往往用于全文检索中,大家平时在用百度或者谷歌搜索的时候,就会用到全文检索,其背后的索引是倒排索引。
B树
介绍完索引,我们再来了解一下B树。大家需要注意的是,B树实际上是一个很大的家族,因此大家在技术文章或者博客的时候,需要留意他所提及的B树具体是哪种B树。B树可以细分多个子类别,对比我们大学的数据结构课程,课里提及的一个结构容易与B树混淆。即二叉树。二叉树和B树都是平衡树,但二叉树它的每个节点里只能存储一个键值,而B树中的每个节点都存储了大量键值,因此树不会太高。
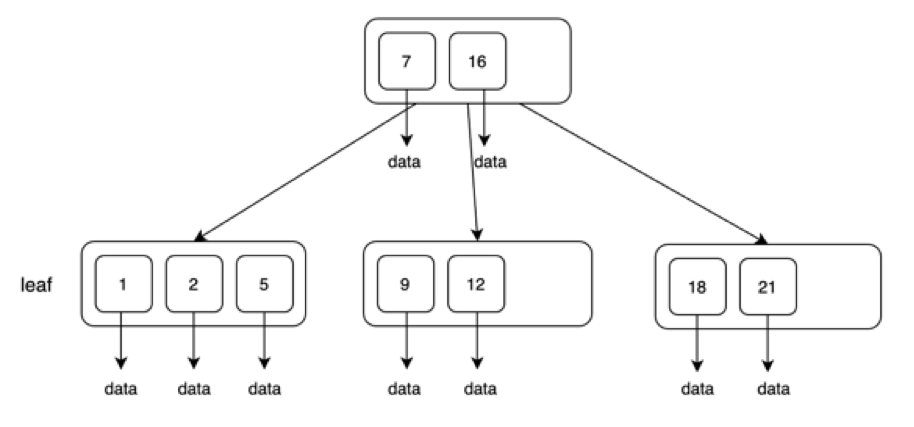
具体大家看上图这个典型的B树,它的节点里存储了很多键值,这些键值也是有序排列,比如图中的1,2,5,7,9,12,16,18,21。每个键值都会指向目标数据。
B+树是B树最常见的一个子类别,下图就是一个典型的B+树。B+树的特点是叶子层节点存储了全部键值,这些键值再指向目标数据,比如图中的1,2,5,9,12,18,21。内部节点中重复存储部分键值,但不含数据指针。叶子节点层有一个正向的遍历列表。
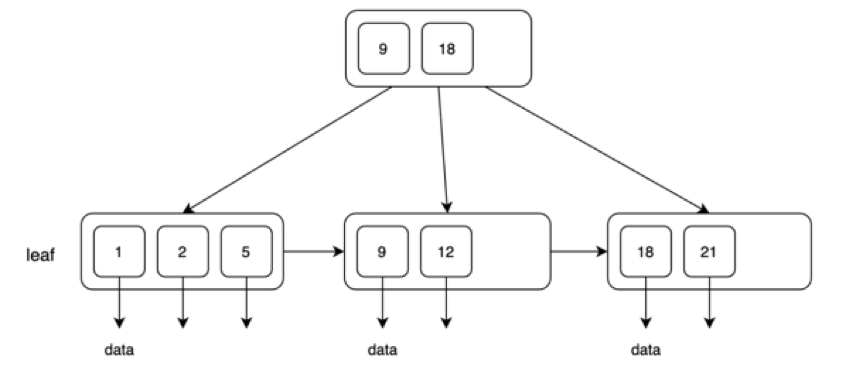
这里我们就会解答开始时让大家思考的第一个问题:为什么经常使用B树来作为数据库的索引结构?实际上是B+树。B+树非常适用于数据库中的索引结构,它的最主要的目的就是减少磁盘lO,每个节点对应磁盘中的一个页,访问节点对应一次磁盘IO。因此我们会希望树非常扁,即树的高度非常少,因为树的高度就是访问磁盘IO的次数。
为什么使用B+树?因为B+树在节点不用存储数据或数据指针,因此每个节点里能存储的键值要比B树多,存储的键值多,B树就会变得非常扁,高度会非常低,磁盘lO就更少。因此我们选用的经常是B+树。
还有一个原因是我们经常需要范围查找,比如上图中如果要找到有2~9的数据,我们把2的数据找到后,沿着右侧方向就能把5和9也找到,因为在页的节点层有右上指针,因此我们不再需要从根出发,而是直接向右移动就能找到。
B+树也是Greenplum中的默认索引类型。Greenplum是基于Postgresql并在其之上做了很多改进。因为Postgresql也是个传统数据库,因此它选用的也是B+树。比如下面的例子中,我们在一个大表中查找了一个ID等于1万数据,共花了20秒的时间。接着我们建立了一个索引,需要留意的是,这里并没有指明索引的类型,这样的话,默认就是B树的。然后我们再查一次,这次花了200毫秒,提升了100倍。大家可以看到,使用索引可以很好地提升查询的性能。
demo=# select * from big where id=10000;…Time: 19490.566 msdemo=# create index on big(id);CREATE INDEXdemo=# analyze big;ANALYZEdemo=# select * from big where id=10000;…Time: 210.594 ms
Blink树
在了解完B树和B+树后,大家现在可能会有一个疑问:Greenplum中用的到底是不是B+树呢?答案是既是也不是。Greenplum中用的B+树叫Blink树。
在具体介绍Blink树之前,先补充一点,我们在大学课程中讲的B树或者B+树 ,有两个方面基本没有提及。第一个方面就是B树需要支持故障恢复,当数据库宕机了,大家肯定不希望所有数据在宕机之后就无法恢复了。如果数据库突然重启了,重启之后发现索引坏了,大家肯定会非常头疼。实际上WAL(重做日志)中会记录节点页面和树结构(如页面分裂)的变化,因此我们通过重做WAL日志就可以恢复。关于恢复的相关内容,大家可以关注我们内核直播系列 的后续课程。
第二个方面是B树需要提供一个高性能的并发控制,因为生产环境中的数据库,同时要为大量并发访问所服务,因此就需要提供高性能的并发控制。
出于这两点考虑,Greenplum采用的是Blink树。Blink树来自于Lehman和Yao于1981年的论文《Efficient locking for concurrent operations on B-trees》。Greenplum中的实现就参考了该论文并进行了稍许改进,该论文中在B+树的基础上,在结构中引入了右兄弟指针和高键。右兄弟指针使得内部节点同层间可以向右移动。除了叶子节点层,在中间节点层也有右兄弟指针的存在,比如下图的中间层。而高键是指当前节点和以当前节点为根的子数中的最大键值。
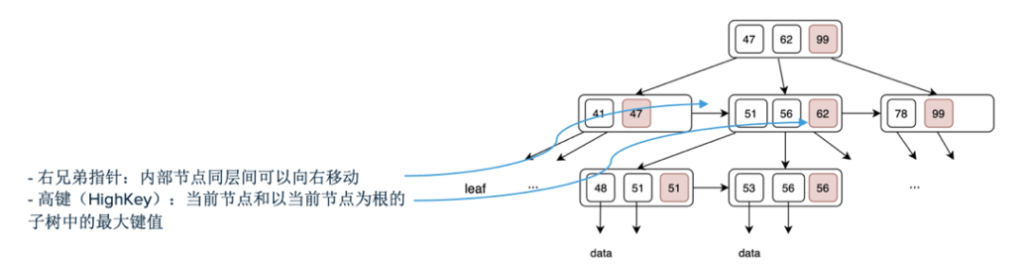
现在我们已经了解了B树的基础知识,在接下来的内容里,我们称呼上不再细分B树的类型,提到的B树特指Greenplum中的B树,也就是Blink树。接下来让我们看看B树的存储结构。
存储结构
物理存储
在这里,我们先介绍一下就是粗粒度的索引存储,Greenplum中的索引都是二级索引,简单来说就是在物理存储上是独立的文件,独立于表中的数据文件。索引是按分片存在在每个segment上其索引内容对应segment上的数据分配。
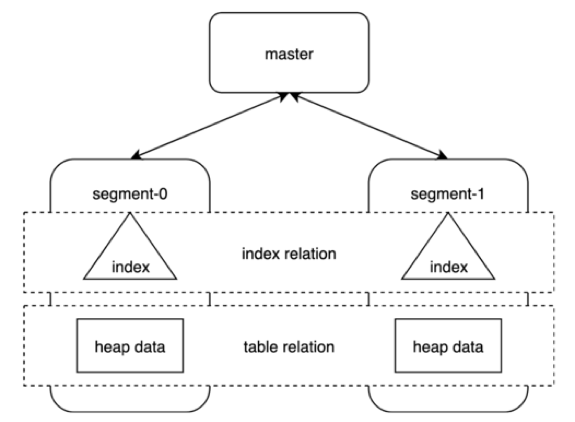
大家如果想看索引文件在哪,可以通过下面这个SQL查询,先找到文件名。在我的电脑上,通过文件名16524,在Greenplum数据目录中执行一下find命令,就可以找到这两个文件。这里有两个文件,是因为我的测试环境是2个segment,大家如果感兴趣可以执行一下看看。
demo=# select relname, relfilenode, gp_segment_id from gp_dist_random('pg_class') where relname = 'student_id_idx’;relname | relfilenode | gp_segment_id----------------+-------------+---------------student_id_idx | 16524 | 1student_id_idx | 16524 | 0(2 rows)$ find . -name 16524 | xargs ls -l-rw------- 1 interma staff 1212416 Mar 17 10:44 ./gpseg0/base/16384/16524-rw------- 1 interma staff 1179648 Mar 17 10:44 ./gpseg1/base/16384/16524
逻辑结构
接下来给大家介绍一下索引的逻辑结构。大家可以看一下下面这张图。从右向左看,下面是堆表中的数据部分,我们着重看一下上面的索引数据。
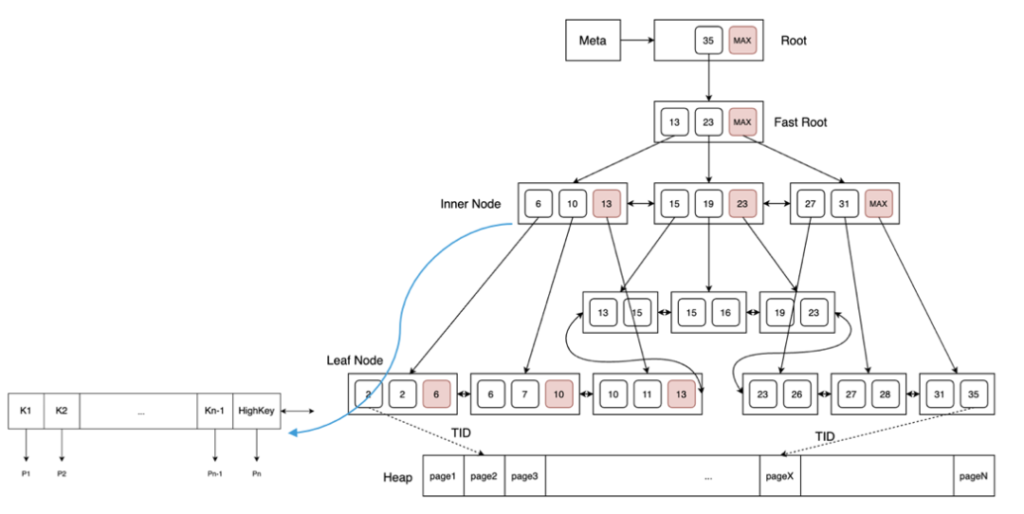
大家从上到下看,Meta页存储的是整个树的元信息。root节点大家应该都理解,但这里还有个Fast Root,我们来简单介绍一下什么是Fast Root?B树随着增删数据,有可能从最上层,每层的节点到下层都只有一条指针。这样的话,每次查找都需要从根上往下走,但是每层到下层只有一个指针,因此就没必要再从第一层进第二层再进第三层,直接从fast root层进入即可,这样就起到一个加速的作用。每个节点中标注粉色的就是高键。
此外,论文中提到Blink树只要是右向指针就可以,但Greenplum中用的是双向的,因此在反向遍历的时候也很方便。
这是树的整体情况,接着我们来看看单个节点,即左下这个图。单个节点里边是N-1个键值和N的指针,即指针会比键值多1,再配上一个高键,即High Key。
有些读者可能会问,索引里边有没有版本信息呢?答案是没有。也就是说实际上Greenplum的每个版本的数据元组,都会有对应的索引元组。为了减少索引空间开销,Greenplum引用了 HOT (Heap Only Turple)技术。这里就不做进一步介绍,大家感兴趣可以去网上搜索了解一下。
索引节点物理结构
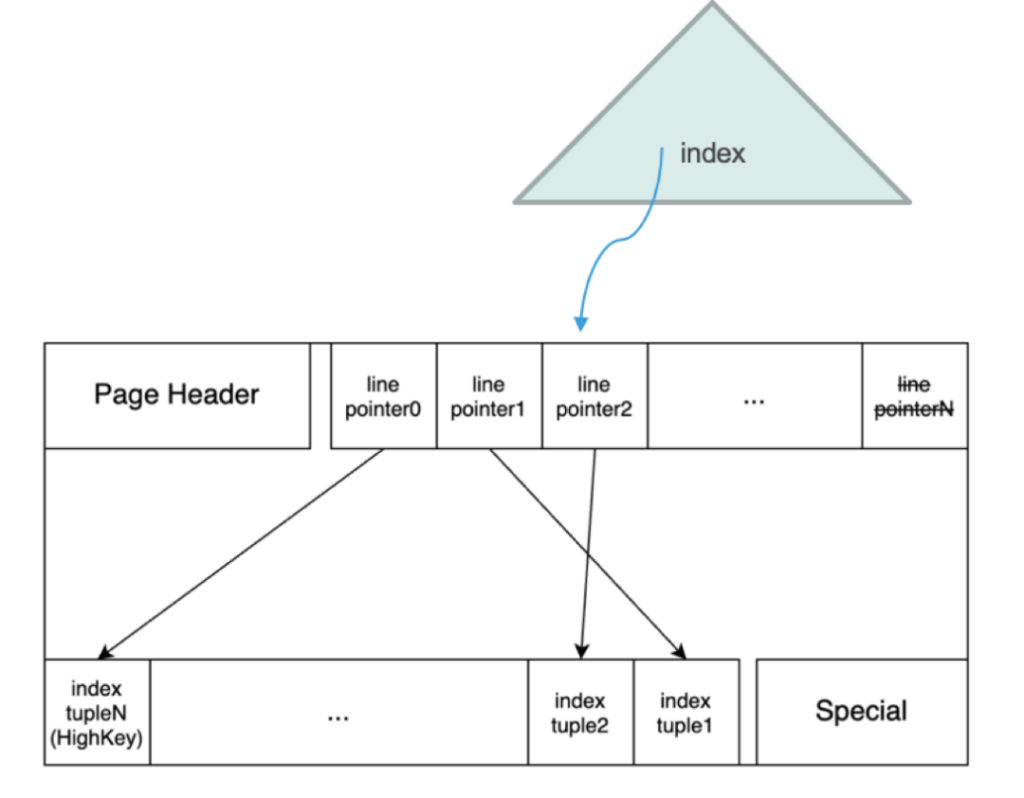
每个索引节点实际上都对应一个物理页面。页面结构和堆表(Heap)的页面结构基本一致,但还存在一些区别。由于数据元组,即堆表里的页面存储的是数据元组,而这个索引的页面,因此里面存储的肯定不是数据,而索引元组,它逻辑上的内容就是键值和指针。
这里大家需要留意的是,Line pointer0指向的,即第一个索引元组是高键,它后边的才是普通的索引元组。而Special 页面存储了页面级元信息,包括兄弟指针、页面类型等。
Pageinspect示例
介绍完逻辑结构和物理结构,读者可能有疑问,怎么能比较直观的看到这些内容呢?可以通过Greenplum或者Postgresql中的一个扩展来查看,它叫Pageinspecthttps://www.postgresql.org/docs/9.5/pageinspect.html,通过它可以查看页面中的内容。除了可以查看数据元组的内容,即堆表的内容,它还提供了很多函数查看索引的内容。查看B树索引,最常使用的是下面这三个函数。
- bt_metap returns information about a B-tree index’s metapage
- bt_page_stats returns summary information about single pages of B-tree indexes
- bt_page_items returns detailed information about all of the items on a B-tree index page
第一个是bt_metap,是用来看B树的meta页。bt_ page_stats是用来查看页面的special 元数据,而bt_page_items会返回索引元组的信息。
下面的例子中建立了一张测试表,表里有两个字段,第一个字段是ID,是递增的1到1万,第二个字段随机插入了一个字符,然后建立了索引。因为Greenplum是MPP数据库的,它的Master上是没有数据的,因此如果大家运行这个SQL时,需要通过工具模式直接连接到segment上。
# 建立测试表demo=# create table test_index (a integer, b text) distributed by (a);demo=# insert into test_index(a,b) select s.id, chr((32+random()*94)::integer) from generate_series(1,10000) as s(id) order by random();demo=# create index on test_index(a);demo=# create extension pageinspect;PGOPTIONS=‘-c gp_session_role=utility’ psql -p 6000 demo #通过工具模式直接连接到segment上
我们先看meta页面,从查询中数据可以看出:
- 这个索引的根层级是1(叶子节点层级是0),即树的高度为2。
- 快速根节点和根节点是同一个节点(块号相同,均为3)
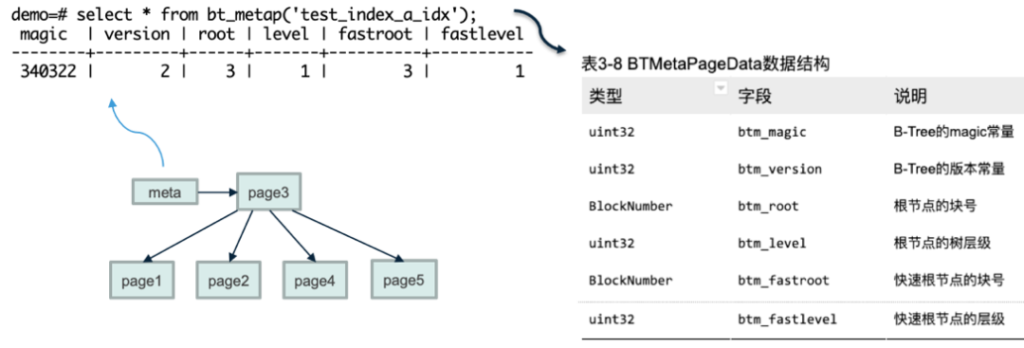
如果大家看过Greenplum代码,就会发现这里的这些信息,和代码里的BTMetapageData结构体是一一对应的。
接下来,我们来看看内部节点长的是什么样的。Stats对应页面中的special结构:对应代码中的BTPageOpaqueData结构体。各字段的含义如名字,其中btpo表示层号:root节点的层号是1。Items对应页面中的索引元组:其中内部节点的第一个索引元组的键值为空。刚刚我们提过,节点里的键值是n减一个,指针是n个,由于键值少1,因此按照惯例,我们会把第一个键值留空。
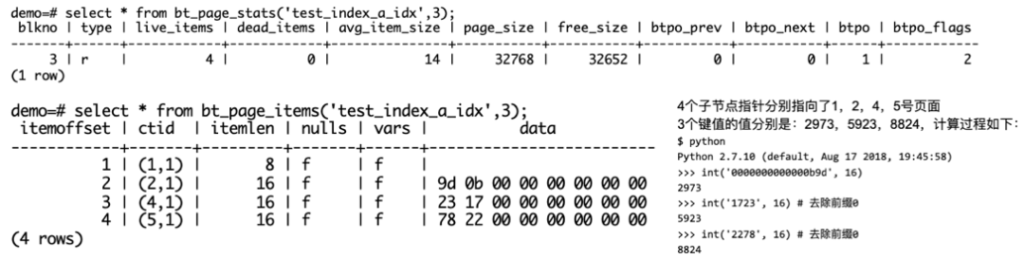
接着我们再来看看叶子节点。叶子节点type都等于l,表明leaf页;btpo都等于0,表示第0层。live_items总共:1473*3+597=5016个索引元组,而另一个segment上有4984个索引元组,这与表中共10000个记录吻合。前3个leaf页面已经填满,填充率约为(1-3264/32768)=90%,这也是B-Tree的叶子节点的默认填充因子(内部节点的填充因子是70%),如果页面完全填满,会导致这个页面非常容易分裂,因此我们特地留了一点点空间,让页面不那么容易分裂来提升性能。btpo_prev和btpo_next页面表明leaf页的顺序是(由左到右):1 <-> 2 <-> 4 <-> 5。
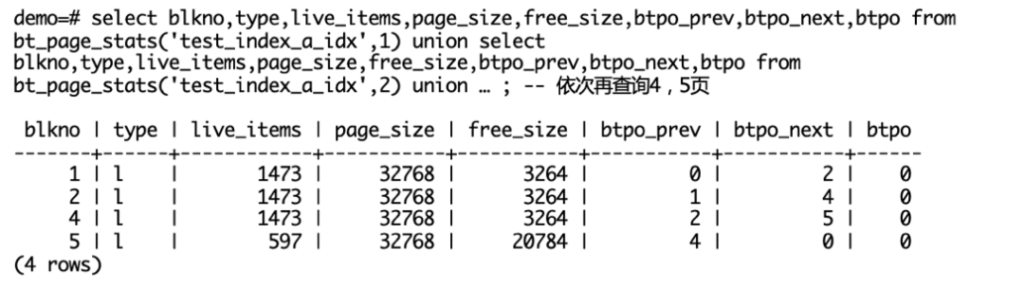
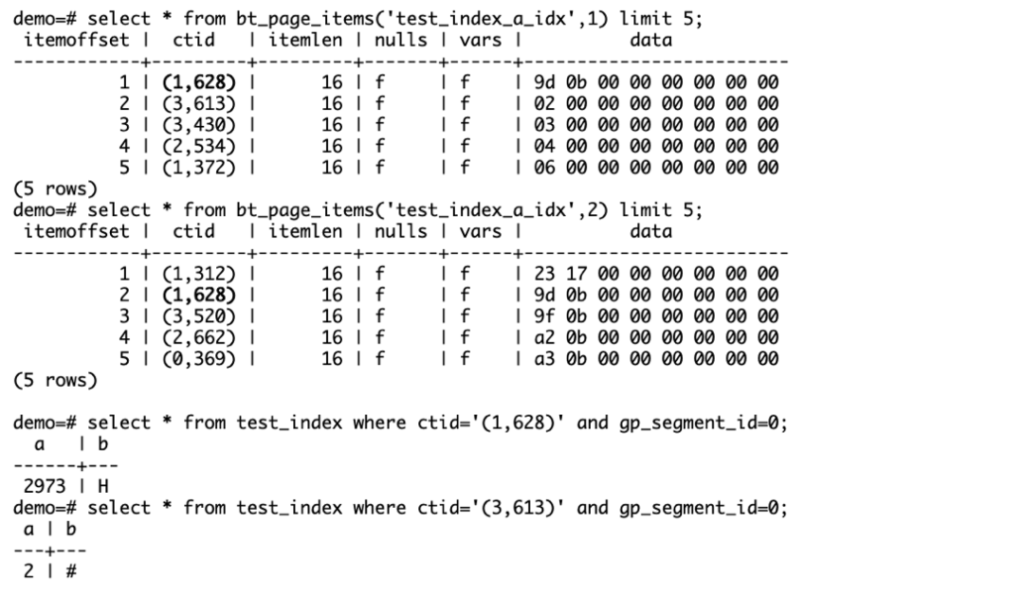
前面介绍的是页面元信息,我们再来介绍一下页面的索引元组叶子节点items。叶子节点items的第一个条目是ctid=(1,628),如前边B-Tree逻辑示例图中所述,每个页面内存储的第一个键值是HighKey,而从第二个元素开始,才是真正叶子节点存储的键值。同时这也是第二页的第一个普通键值(这里不是巧合,B-Tree构建的细节将在后边详述)。而第一页的第2个键值为2,它也是这个B-Tree索引的最小值。
操作算法
介绍完B树结构,接下来我们来看看B树的操作算法。这里的操作算法我们将不从代码层面来进行介绍,而是着重介绍一下增删改查的算法。然后在这里大家不用考虑并发控制,因为并发控制是在我们下一节来介绍的。
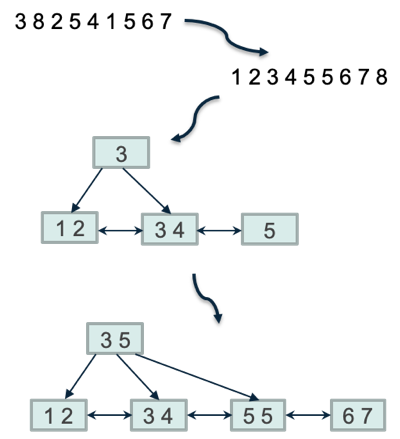
构建
构建一棵B树是由create index触发的,从表中现有数据创建出一颗B树索引,算法可以分2大阶段。第一个阶段是排序,将表中数据元组有序化。排序对比插入方案,插入方案在每次插入时,都需要由根到树叶部分做一次下降过程,消耗较大,因此我们会采用排序来提升效率。先排序还可以提前处理唯一索引。
第二步是遍历有序的数据元组,由下向上来构建整个B树。当节点页面已满(实际上还有部分空闲空间)时,生成当前节点高键;再生成右兄弟节点,插入键值到父节点中。最后由下向上补全B树,并填充meta信息。
插入
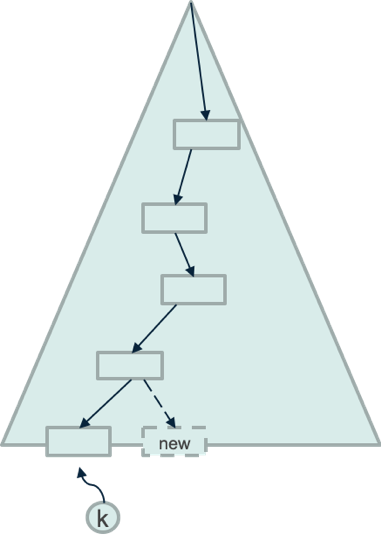
插入算法是由insert语句触发:首先插入数据元组,然后插入索引元组,算法如下:
首先从根节点开始向下查找,目标是定位要插入索引元组的叶子节点。记录从根节点到叶子节点的这条路径,供后续反向插入父节点使用。随后在叶子节点中定位要插入的具体偏移位置,并插入索引元组到这个叶子节点中。如果叶子节点已满,则需要分裂节点并插入一个新键值到父节点中,此过程会沿着查找路径递归向上执行(有可能导致父节点继续分裂)。
查找和删除
我们再来给大家讲一讲查找、删除算法。最常见的使用索引的方法是普通索引扫描,它和我们插入算法特别相似,就是一条下降路径下降到叶子节点,然后在叶子节点中找到一个偏移,就可以找到。
索引扫描最终是找到一个指针,通过这个指针就可以访问到数据。但指针就意味着这是一个随机IO,也就是说它是随机访问的。因此尽管通过索引查找速度很快,但相对于顺序IO,性能较差。如果有大量的随机IO,性能将很难提高。于是引入了位图索引扫描,它会把找到的地址进行一个排序,然后会随机IO尽量转化成顺序IO。位图索引扫描可以查看这篇文章详细了解。
关于删除算法,大家可能会想是不是在删除一个数据源组的时候,会把索引给删了,答案是不会的。删除不是由delete语句触发,而是索引扫描时发现死亡的数据元组后,对相应的索引元组进行”标记删除”。vacuum时进行最终删除,也是二阶段算法:首先删除已标记的索引元组,然后删除空页面并调整树结构(由下向上调整)。
并发控制
在现实生活中应用的数据库系统里,并发控制是必须要考虑的,因为数据库不可能只由一个人使用,这也是Greenplum选择Blink树的原因。在介绍并发控制算法之前,我们先看看一个朴素算法会遇到什么问题,来帮助大家理解Greenplum中为什么要使用Blink树。
这种朴素的并发控制算法的思想非常简单,在读节点时加读锁,写节点时加写锁,唯一需要特殊处理的就是节点分裂。大家可以看一下下面的代码。每次其实只有一个节点会被加锁,往下走的时候,会把下面的节点加锁,再把上面的节点的锁释放。


插入节点会复杂一些。每次加的锁是写锁。这里要给大家介绍一个新的概念,当在某个节点上插入一个新索引元组后,不会触发它的分裂,那么这个节点就叫做安全节点。也就是说还没满的节点,每次插入一个键值的时候,就把这条路径上的所有节点都会加写锁。那么为什么要加写锁呢?前文的插入算法里提过,我们有可能会反向向父结点中插键值,因此必须要锁住。
在大多数情况下,在叶子节点中插完键值后,才把叶子节点释放掉,然后再把父节点的锁释放掉。这里的安全节点就是一个特殊的优化情况,有些节点因为还没满,可能往里插键值也不会分裂,也就是它上层的树的结构是不会变化的。所以说上层这两个父节点的锁都可以先释放掉,这是一个简单的优化。但是在极端情况下,这条路径都加了锁。这就会带来两个问题,首先由于每次路径下降都需要锁操作,所以在靠近树根的位置上的锁冲突率较高。另外在路径下降时加的这些锁,大概率都会被马上释放掉。

接下来我们来看看Greenplum中是如何解决的。Greenplum中的Blink树并发控制算法,引入了一个moveright操作,利用到了HighKey和右兄弟指针,用于及时发现节点已经被分裂:如果分裂,所查找的键值一定在右兄弟节点上。也就是说每访问一个节点,先看看查找的键值是否大于高键。如果是,就移到右边的节点上,然后再进行访问。

那么为什么要用这个操作呢?下图的示例来自Blink论文,因此也很有年代感了。通过moveright操作,可以处理下图这种分裂问题。Insert操作的下降过程中也加读锁,可以放松下降过程中的锁操作。
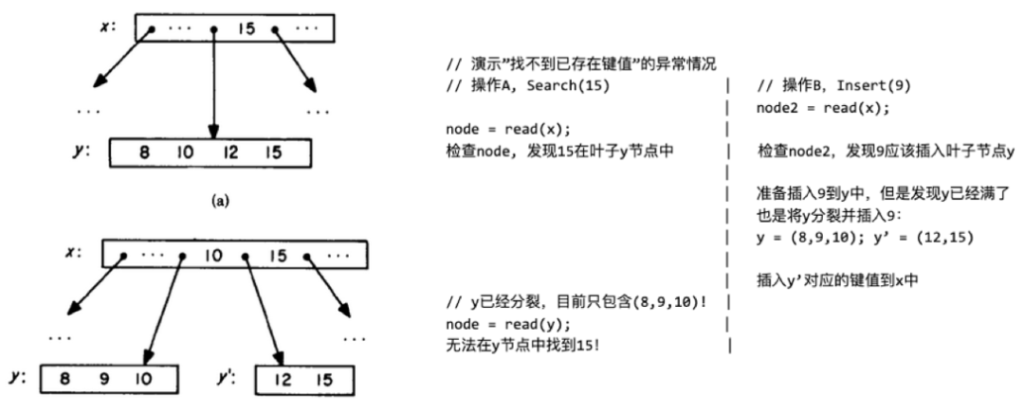
Blink树并发控制算法具体如下:
Blink树并发控制算法- Search
- 从根节点开始逐层下降,加读锁
- 每次下移一层后,都调用moveright操作,检查节点是否分裂
- 在下移或者右移操作时,都是先释放锁,然后再去申请新锁,即申请新读锁操作时并不持有锁,因此可以避免死锁(和Insert操作并发时)
- 最后到达叶子节点,加读锁,并读取内容
Blink树并发控制算法 – Insert
- 开始阶段同Search操作一样,逐层下降加读锁并配合moveright,因此并行佳
- 逐层下降到达叶子节点后,需要将读锁升级为写锁
- 如果需要节点分裂
- 新建右兄弟页面,加写锁,随后将它挂入到B-Tree中
- 随后递归向上插入键值:由下向上为父节点申请写锁,随后插入到父节点的操作,然后再释放下层节点的写锁
Blink树解决了朴素算法的2个问题
- 树根的位置上的锁冲突率较高 => 读写均加读锁
- 另外在路径下降时加的这些锁,大概率都会被马上释放掉 => 下降时加读锁,写锁由下向上申请
我们再来看下是否会产生死锁:
- Insert操作中写锁的申请顺序都是由下向上,由左到右,不会发生死锁
- Search操作是可能和Insert操作出现不同申请顺序(前者由上向下;后者由下向上),但是Search操作每次都是先释放再申请,因此也不会发生死锁
索引相关系统表
最后会给大家介绍一下索引相关系统表。大家在用索引的时候,经常会和系统表打交道,这里简单介绍它是什么作用,了解索引相关系统表也更好的了解其作用。这里给大家提了一个问题,Greenplum中的类型系统是可以自定义和扩展的,同一套B树算法如何支持不同的数据类型呢?
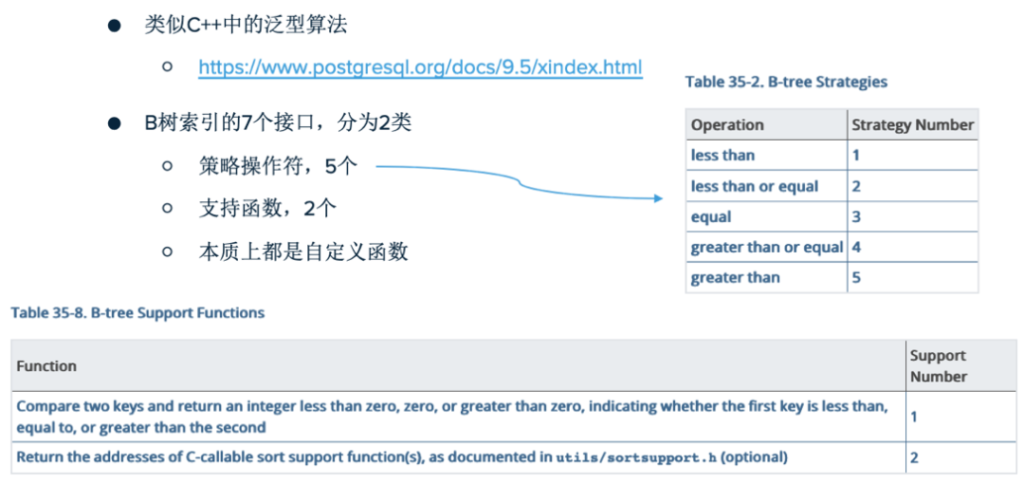
相信大家都已经有了答案,这里遇到的问题和C++中的泛型算法非常类似。相当于在B树算法里,留出了扩展点或接口。对于B树来说,就是7个接口,它们本质上都是自定义函数。
- 策略操作符,5个
- 支持函数,2个
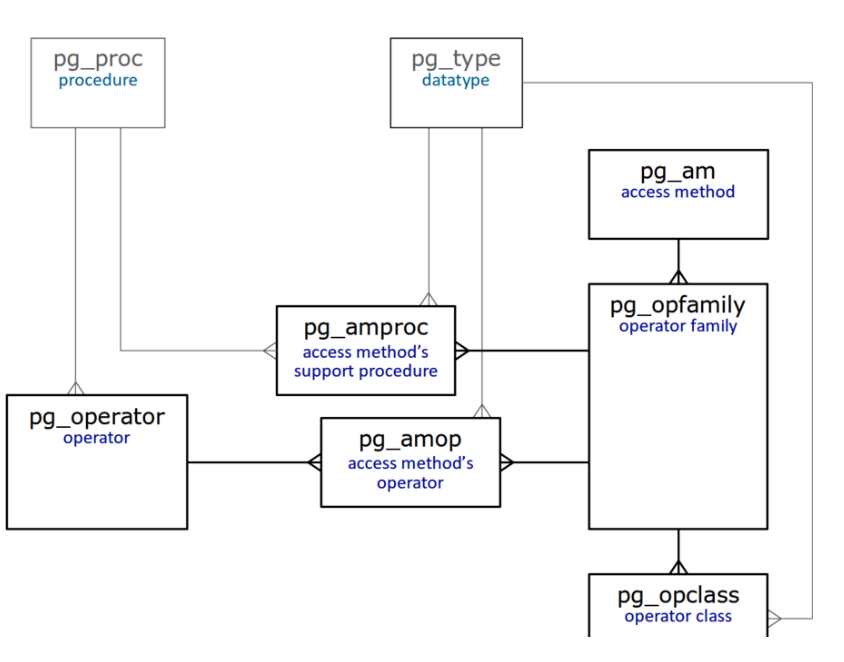
索引表的最终目的就是为自定义类型添加索引的支持。如果把系统表都展开,大家可以看到下图中,有很多个系统表,这里就不做赘述。这里就给大家解释两个容易混淆的概念,Operator class和Operator family:
- Operator class,同类型上的函数接口
- Operator family,跨相近类型上的函数接口
总结
B树的基本实现并不复杂,但是各种优化非常博大精深,涉及到系统优化的方方面面。Greenplum中的B树索引实现主要参考了Blink论文,这篇论文虽然已经年代久远,但非常经典,对后续B树的并发控制设计仍然具有深远的影响。读者如果有兴趣,非常建议继续阅读Greenplum的B树实现源码(位于src/backend/access/nbtree),从而可以了解到一个实用的数据库系统是如何处理各个细节的。

