简介
Greenplum 数据库利用多版本并发控制(MVCC)来维护数据的一致性和管理对数据的并发访问。事务快照被用来控制哪些数据对一个特定的SQL语句是可见的。当一个事务读取数据时,数据库会选择一个特定的版本。这可以防止SQL语句查看由修改相同数据行的并发事务产生的不一致的数据,提供事务隔离 (transaction isolation)。MVCC允许数据库即使在繁重的活动中也能提供高并发性。
事务快照保持了一个数据库服务器的一致性,但没有提供跨多segments的一致性保证。
Greenplum 通过利用分布式快照扩展了快照模型,分布式快照在所有segments上同步一个快照。[1]当在Greenplum中运行一个语句时,coordinator会生成一个分布式快照,然后将其与查询一起发送给各segment。当每个segment收到分布式快照时,它会创建一个本地快照,将local transaction ID (xid)映射到分布式 xid。这就是Greenplum维护整个集群数据一致性的方式。
隔离级别和事务快照
Greenplum 提供两个级别的事务隔离:READ COMMITTED和REPEATABLE READ。
READ COMMITTED是默认的。当一个事务使用READ COMMITTED时,一个SELECT查询在查询开始运行时看到的是数据库的快照。如果其他事务在语句之间提交变化,在同一事务中运行的后续SELECT可能看到不同的数据。
在REPEATABLE READ中,单个事务中的所有语句只能看到事务中运行的第一个查询或数据修改语句(INSERT、UPDATE或DELETE)之前提交的行。单个事务中的后续SELECT语句总是看到相同的数据,也就是说,它们不会看到在REPEATABLE READ事务中提交的其他事务所做的更改。
所有交易都存储一个快照,由以下字段定义:
xmin – 仍处于活动状态的最早的xid。在这之前的所有事务都保证会被提交或中止。
xmax – 第一个未分配的xid。所有 xids >= to xmax 都还没有开始,对快照来说是看不见的。
xip_list – 在快照发生时活跃xid。
每个元组都有一个xmin,被设置为INSERT或UPDATE事务的xid。
一个元组的xmax由UPDATE或DELETE语句的xid设置。
快照导出
一个事务可以导出它正在使用的快照。只要该事务保持活跃,其他事务可以导入快照,保证他们看到的数据库状态与原始事务相同。[2]
快照是用pg_export_snapshot()导出的,用SET TRANSACTION SNAPSHOT导入。
让我们来看看一个基本的例子。
我们在表foo中插入10行,然后在REPEATABLE READ中开始一个事务,并导出快照。
会话1:
postgres=# create table foo(a int); insert into foo select generate_series(1,10);
postgres=# BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
postgres=# select pg_export_snapshot();
pg_export_snapshot
---------------------
00000005-0000009F-1
postgres=# select count(*) from foo;
count
-------
10第二个会话出现了,插入另外10行。
会话2:
postgres=# insert into foo select generate_series(11,20);
INSERT 0 10
postgres=# select count(*) from foo;
count
-------
20因为会话1的事务隔离级别是REPEATABLE READ,它不能看到额外插入的10行。
会话1:
postgres=# select count(*) from foo;
count
-------
10然后我们可以为会话2设置TRANSACTION SNAPSHOT,得到与会话1相同的数据库状态。
会话2:
postgres=# BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ ;
BEGIN
postgres=# SET TRANSACTION SNAPSHOT '00000005-0000009F-1';
SET
postgres=# select count(*) from foo;
count
-------
10在END之后,我们又看到了所有的20行。
会话2:
postgres=# END;
COMMIT
postgres=# select count(*) from foo;
count
-------
20那么锁呢?
事务快照不是锁的替代品。它们只能保证用户数据的一致性。
某些DDL命令,比如TRUNCATE和ALTER TABLE的某些变体,不是MVCC安全的。这意味着一旦TRUNCATE提交,表对于并发的事务来说将显示为空,即使它们使用的是TRUNCATE提交前的快照。让我们来看看一个例子。
会话1:
postgres=# BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ ;
BEGIN
postgres=# select pg_export_snapshot();
pg_export_snapshot
---------------------
00000005-000000A3-1
postgres=# select count(*) from foo;
count
-------
20在一个新的会话中,试图TRUNCATE表会被阻止,因为会话1对foo有一个ACCESS SHARE锁(来自SELECT)。
会话2:
postgres=# truncate table foo;
...(hanging)以下是锁的样子:
postgres=# select gp_segment_id, locktype, mode, granted from pg_locks where relation='foo'::regclass and gp_segment_id=-1;
gp_segment_id | locktype | mode | granted
---------------+----------+---------------------+---------
-1 | relation | AccessExclusiveLock | f
-1 | relation | AccessShareLock | t当TRUNCATE被阻止时,让我们打开第3个会话并导入原始快照。
会话3:
postgres=# BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ ;
BEGIN
postgres=# SET TRANSACTION SNAPSHOT '00000005-000000A3-1';
SET
postgres=# select count(*) from foo;来自foo的这个select count(*)也被挂起。它被排在会话2的TRUNCATE后面,而TRUNCATE本身也在等待会话1。
gp_segment_id | locktype | mode | granted
---------------+----------+---------------------+---------
-1 | relation | AccessShareLock | t <==== Session 1
-1 | relation | AccessExclusiveLock | f <==== Session 2
-1 | relation | AccessShareLock | f <==== Session 3回到会话1 我们依然可以看到所有的20行。让我们commit看看会发生什么。
会话 1:
postgres=# select count(*) from foo;
count
-------
20
postgres=# COMMIT;
COMMIT其他会话被解禁,语句执行完成。
会话 2:
postgres=# truncate table foo;
TRUNCATE TABLE会话 3:
postgres=# select count(*) from foo;
count
-------
0即使会话3仍然在使用导入的快照的事务中,它在foo中看到0行。这是因为TRUNCATE是一个破坏性的动作,并不是MVCC安全的。
快照实战:并行的gpbackup
连贯的备份是数据库系统的一项重要维护任务。对一个大型数据库进行连续的备份可能需要许多小时来完成。此外,随着数据库规模的增长,备份时间通常也会随之增长。
我们已经通过在Greenplum数据库备份工具gpbackup中添加快照支持来解决这个问题。[3] 通过使用导出的快照,我们可以让多个连接并行地备份表,同时确保他们都能看到数据库的单一快照。对于gpbackup,我们可以用–jobs标志来指定并行连接的数量。
性能分析
在下一节,我们将分析gpbackup并行备份的性能。关于gpbackup和以下测试中使用的标志的详细信息,请参考文档。
运行在并行系统上的程序的执行时间可以分成两部分:
- 一部分不受益于处理器数量的增加(串行部分)。
- 另一部分受益于处理器数量的增加(并行部分)。
对于gpbackup,串行部分包括设置、收集数据库集群信息和转储元数据。并行部分包括数据备份本身。
测试是在一个单主机3个segments集群上进行的,启用了镜像功能,硬件如下:
16 cores
2 threads per core
128GB RAM
1 TB NVME
给定一个固定的问题规模,在我们的案例中是备份一个特定的数据集,阿姆达尔定律给出了资源改善时执行任务的理论上的延迟加速。[4]
该公式为:
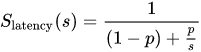
其中
- S是整个任务执行的理论速度。
- s是任务中受益于改进资源的部分的速度提升
- p是受益于资源改善的部分原来所占的执行时间比例。
让我们用gpbackup来测试一下这个公式,它包含了一组大约165GB的数据的表。这些表和生成的数据来自TPC-DS基准,这是一个数据库的jobs负载分析工具。[5]
首先测试串行备份作为基线。
$ gpbackup --dbname testdb --leaf-partition-data --backup-dir /data_nvme --include-schema 'scaletest' --compression-type zstd
20230328:00:00:24 gpbackup-[INFO]:-gpbackup version = 1.27.0
20230328:00:00:24 gpbackup-[INFO]:-Greenplum Database Version = 7.0.0-beta.2+dev.33.g992aa87343e build dev
20230328:00:00:24 gpbackup-[INFO]:-Starting backup of database testdb
20230328:00:00:24 gpbackup-[INFO]:-Backup Timestamp = 20230328000024
20230328:00:00:24 gpbackup-[INFO]:-Backup Database = testdb
20230328:00:00:24 gpbackup-[INFO]:-Gathering table state information
20230328:00:00:24 gpbackup-[INFO]:-Acquiring ACCESS SHARE locks on tables
Locks acquired: 29837 / 29837 [=========================================] 100.00% 0s
20230328:00:00:25 gpbackup-[INFO]:-Gathering additional table metadata
20230328:00:00:30 gpbackup-[INFO]:-Getting storage information
20230328:00:01:14 gpbackup-[INFO]:-Writing global database metadata
20230328:00:01:14 gpbackup-[INFO]:-Global database metadata backup complete
20230328:00:01:14 gpbackup-[INFO]:-Writing pre-data metadata
20230328:00:01:17 gpbackup-[INFO]:-Pre-data metadata metadata backup complete
20230328:00:01:17 gpbackup-[INFO]:-Writing post-data metadata
20230328:00:01:17 gpbackup-[INFO]:-Post-data metadata backup complete
20230328:00:01:17 gpbackup-[INFO]:-Writing data to file
Tables backed up: 29825 / 29825 [=======================================] 100.00% 15m13s
20230328:00:16:31 gpbackup-[INFO]:-Data backup complete
20230328:00:16:33 gpbackup-[INFO]:-Backup completed successfully然后用2、4、8和16个jobs运行同样的备份。使用3个segments,gpbackup正在创建jobs*3个worker连接。
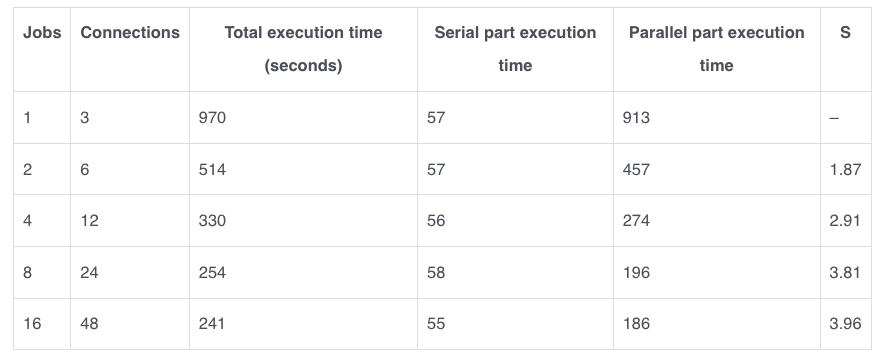
通过使用阿姆达尔定律计算S,我们可以得出结论
- 2个jobs提供了~2倍的速度提升
- 4个jobs提供了~3倍的速度提升
- 8个jobs提供了~4倍的速度提升
- 16个jobs我们有很强的收益递减,它只比使用8个jobs的速度略快。
因为测试硬件有32个线程,所以我们看到8个jobs(24个连接)有很大的好处,当线程饱和到16个jobs时,就会出现平稳。
最有效的jobs数将取决于硬件和系统上是否有任何额外的并发负载。
一般的出发点是 jobs = # cpus for host / (primary segments + 15 minute load),所以一台拥有96个cores和8个primary segments的主机,15分钟的平均负载为4,使用jobs = 96 / (8 + 4) = 8 jobs,将受益最大。如果主机是多线程的,这就为后台任务提供了一些额外的空间。
请注意,这只是一个简化,并没有考虑到其他性能指标,如内存或磁盘/网络I/O。
挑战
避免死锁
对有许多表的大型数据库进行备份会带来一些额外的挑战。考虑一个在上午12:00开始的备份。一个表foo可能在1000个其他表后面的队列中等待,并在凌晨3:00被一个备份工人捡到,然后发出了COPY foo TO …。在这3个小时的窗口中,外部命令可能已经排到了foo的锁。正如我们前面所看到的,如果TRUNCATE已经为foo排好了队,任何后续的语句都会被阻断。
在没有干预的情况下,我们有一个问题:COPY foo TO…被TRUNCATE阻断,而TRUNCATE又被0号worker的ACCESS SHARE锁阻断,后者正在等待COPY foo TO …完成。
我们如何避免这种情况?
就在发出COPY foo TO …命令之前,worker连接将尝试使用LOCK TABLE NOWAIT获得foo的ACCESS SHARE锁。如果该语句成功,我们就运行COPY。由于worker 0在备份开始时收集了所有的ACCESS SHARE锁,它可以安全地发布命令而不用担心死锁问题。
终止的交易
如果一个事务由于LOCK TABLE NOWAIT失败而被中止,其快照就不再有效。如果没有设置 TRANSACTION SNAPSHOT 的能力,开始一个新的事务将意味着该连接与其他worker相比对数据库状态有不同的看法。由于这将破坏数据一致性的要求,worker必须终止,我们会失去性能。有了快照功能,worker连接可以简单地开始一个新事务,设置快照,并继续处理表。
避免出现共享内存不足的错误
为什么不简单地让所有的worker获得表上的锁呢?对于小型数据库来说,这可以很好地工作,但这个解决方案并不能很好地扩展。锁并不是免费的,它们需要共享内存中的一些空间。为多个连接收集成千上万的锁,不仅速度慢,而且可能完全耗尽共享内存,导致备份失败。
更糟糕的是,如果连接在备份过程中使用额外的锁而不释放它们,那么在备份结束时可能会发生内存不足的错误。
相反,额外的连接只在需要处理表的时候保留一个锁,然后再释放。通过这种方法,我们消除了由于占用太多的锁而导致备份中途失败的可能性。
结论
分布式快照被Greenplum用来跨segments同步事务快照。它们可以被一个会话导出,并被新的会话使用,以确保他们都看到相同的数据库状态。Greenplum的备份工具,gpbackup,利用了jobs标志的这一特性,它允许并行的数据备份,从而显著提高性能。
