《深入浅出Greenplum内核》系列直播已经进行到第八场,还有二场就要告一段落啦!前八场的视频内容可以前往Greenplum中文社区B站频道观看相关视频,相关PPT均已上传Greenplum中文社区网站(cn.greenplum.org)的下载页面,欢迎获取!现在让我们通过这篇万字长文来回顾一下第七场活动《Greenplum分布式事务》精华内容。
存储引擎的知识体系非常庞杂,拥有很多分支内容。而其中,Heap表是最为关键的模块之一,包含了众多重要的知识点,本文将为大家介绍其中的一些关键内容,来帮助大家进一步学习和理解Heap表。
MVCC机制
之前在《Greenplum MVCC并发控制:严格的一致性与极致的性能》中,大家学习了并发控制相关的内容。由于MVCC是存储引擎中非常重要的内容,今天我们再来回顾一下相关要点。
MVCC,全称是Multiversion concurrency control,翻译成中文是多版本管理。多版本控制管理的核心是对数据的更新、修改、和删除处理。在大学计算机课程里,对于数据的增删查改,通常是这么处理的:删除数据会把数据整体抹掉,更新会在数据存储的内存二进制的文件上,或是在文件映像上直接更改数据,从而不会留下历史数据,并且会引起读写互相等待。
MVCC:INSERT, DELETE, UPDATE
多版本管理中,数据的更新和删除并不一定会在原数据上进行修改,而是需要创立一个新的版本,把原数据标记为失效的数据,再在新版本上增加新数据,数据具有多个版本,这也是多版本管理的名称的由来。插入数据需要记住两个信息,一个是数据的创建者,另一个是数据的删除者,每个数据均带有版本信息。
下图中,事务编号为40的事务创建了原始数据,创建记录会被记录下来。在处理删除时,并不会直接将数据抹掉,而是会记录另一个信息:数据的失效时间或是被删除时间。创建事务是40,删除事务是47。而更新会包括两个操作,一个是删除老的事务,一个是增加新的数据。因此更新会增加两个记录,图中的删除记录是78,增加新数据的记录中创建记录也是78。

总结一下MVCC的特点:
- 每个数据带有一个版本信息。同一个行的数据内容,经过不停修改后,会变成多个数据,历史版本均会存下来。
- 数据的更新或删除并不会影响原来数据在磁盘或文件中的位置。行更新后,原来的行会被标记为删除,行的位置所在的空间还在,新记录不会替换老记录,老记录的位置将不会改变,这让老数据的指针非常有效,这是一个非常重要的特性。
Greenplum中,在扫描一些数据时,利用第二个特性可以通过不用加锁的方式来访问页面。这是因为该快照时刻可见的数据,被认为是不会被移动的,即使被标记为失效,也不会影响到数据移动并仍然有效。
事务间可见性
事务可见性其实就是基于这种MVCC这种朴实的概念。
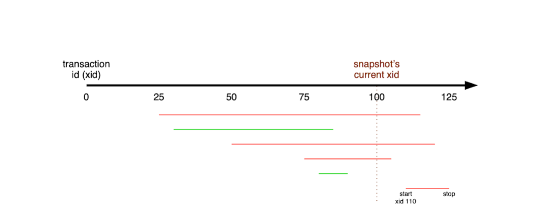
上图中,事务快照在时间点100上,红线和绿线代表事务的起始时间,红色的事务和时间点100有交集。由于事务结束在100之后,此时事务还未结束。也就是说红色事务所做的修改,对当前位于时间点100的事务均是不可见的。相反,绿色的事务已经结束,因此所做的修改能够被100点的事务看到。
数据的可见性判断
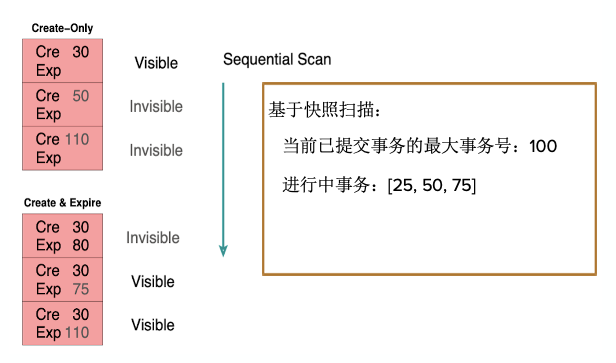
利用上述特性可以进行当前数据的可见性判断。下图中,假设基于事务快照,最大已提交的事务编号是100。也就是说,100以上事务都被认为还在运行当中。但对于小于100的事务,由于可能还在运行中,并不一定已经提交了。因此,需要记录一个信息来标识仍在执行中的事务。例子中的25,50,75仍在运行中,除了这三个外小于100的其他事务均已结束,但大于100的一定是没有提交的。
基于这些信息,我们来判断一下数据是否可见。基于快照从上往下进行扫描,第一个记录被标记由事务30创建,但它没有被删除。30这个事务不在进行中的事务列表里,并小于100,因此这个事务已经结束了。假设该事务已提交,则这个事务是可见的。
对于第二个记录,即50这个记录,虽然它是在100以下,但由于该事务仍在运行中,因此当前事务是不可见的。即使该事务已经结束了,由于判断是基于快照时间点来进行的,快照时间点可能是在当前时间点之前,而不是基于当前时间来判断,会存在时间差。
对于第三个记录,创建记录编号为110,和事务快照的最大拿事务编号对比,比最大事务号100大,因此数据是不可见的。通过这种方式就可以判断每条记录的可见性。
基于事务状态判断元组可见性
上面的例子中,我们假设事务结束后是提交状态。但真实情况下,Greenplum里的事务可以回滚的。回滚分为显示回滚和自动回滚,如果执行过程中遇到错误,会自动回滚,或显示去执行abort命令来回滚。这样的话,每个已经结束的事务会存在提交状态和回滚状态。针对已经回滚的事务进行创建或更新,其影响的数据对其他事务是不可见的。
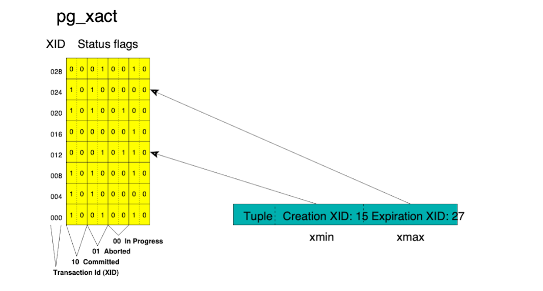
那我们如何去获得这个信息呢?在Greenplum里,每个元组会有一个创建事务的xmin ID和删除事务的xmax ID,因此可以通过LRU的通用数据结构来查找事务状态。LRU是顺序结构,通过事务号按照顺序来寻找事务状态信息。
下图中,创建事务号是15,在第12行,往右边数,在第4列的状态为1。对于删除的事务27,从24行来找事务的状态信息。如果事务是回滚的,则其修改的信息是不可见的。例如,当我们发现xmin是被回滚的,即创建元组的事务是被回滚的,整个元组均不可见。如果是xmax,即删除元组的事务是回滚的,则对元组的删除是不可见的,即该元组对外还是可见的
事务文件日积月累会变得越来越大,这里就需要回收技术,与Greenplum已有的vacuum的机制相关,感兴趣的小伙伴可以给我们留言。
文件结构
回顾了MVCC多版本控制的机制,我们再来看一下对于真实的一个文件,存储结构是什么样的。首先我们来看一下在Greenplum里,文件是个什么样的概念。
Greenplum并行处理架构
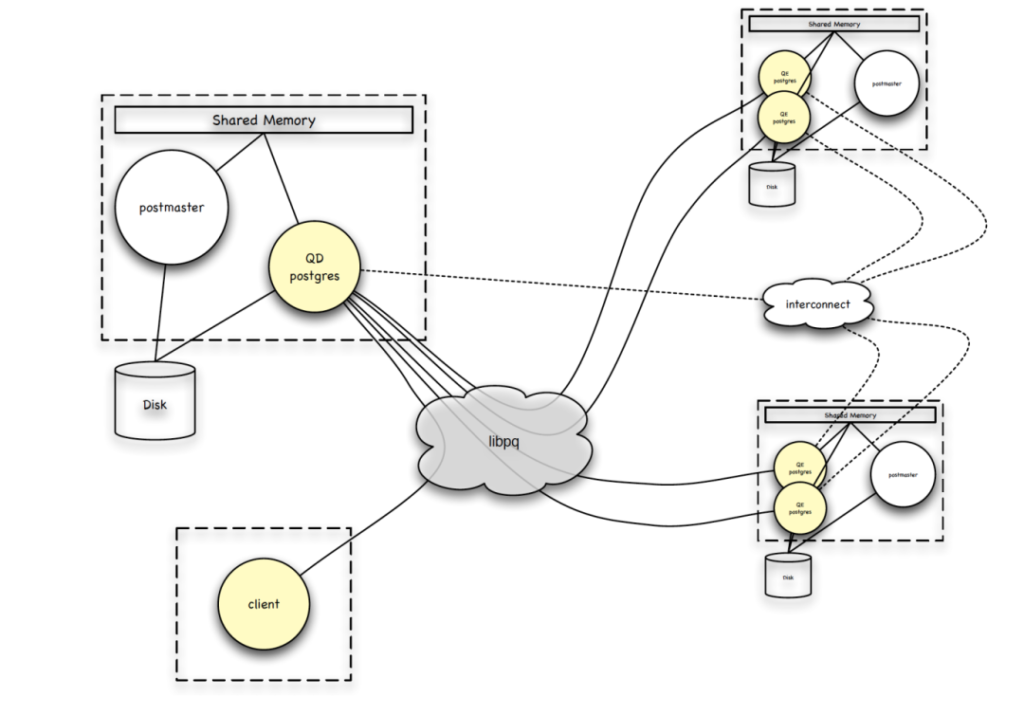
我们先回顾一下内核系列文章第一课中讲的Greenplum的架构。在Greenplum中,client通过libpq连接到master节点,master 节点会fork一个QD进程,该进程为服务进程,服务当前的client。所有client的查询语句都会发送到QD进程,QD进程在通过libpq来连接segment节点,segment节点会fork出本机上的QE进程。无论是QD还是QE,都借用了PG的fork机制来处理请求。
Greenplum共享文件模型
上图中每个虚线框都是一个物理节点,每个物理节点多个进程之间会共享磁盘,对文件进行共享,从而共享数据。
从整个进程结构上来看,postgres进程、backend进程都会指向共享整个数据的目录,在部署Greenplum时,可以指定数据目录。下图中,是放在了data目录下,base作为前缀,后面紧跟数据库的DB ID号(16384),接着是文件编号。
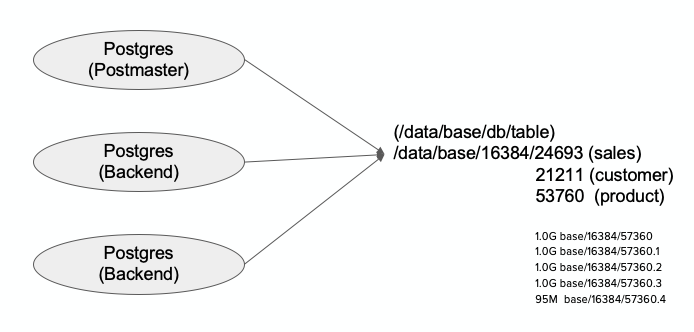
文件编号并不特指某一个文件,例如上图的三个表,存储时会分片存储,数据满后,就会分一个新文件来进行存储,通过“.”后缀形成新的文件片段,一旦存满一个片段,就会往后面增长,例如上图的57360.1,57360.2,… 。
这种模型会存在一些问题,如果几个进程都去访问这个文件,如何去做到并发控制。我们可以通过共享内存来完成的,本文将在共享内存的内容里细述。
了解了文件里的数据是成块的,那么文件里面的数据块如何去管理,需要维护什么样的数据结构呢?
1. 文件页组织:链表方式
比较简单的方法是通过链表的方式存储这些数据块。文件里有一个“头”,被称为头块。头块通过不同的链指向不同的文件框,文件框之间再通过链串起来。但这种处理方法,由于链表不支持随机访问,在访问数据时较为繁琐。此外,文件块头如何设计也是需要慎重考虑的因素。
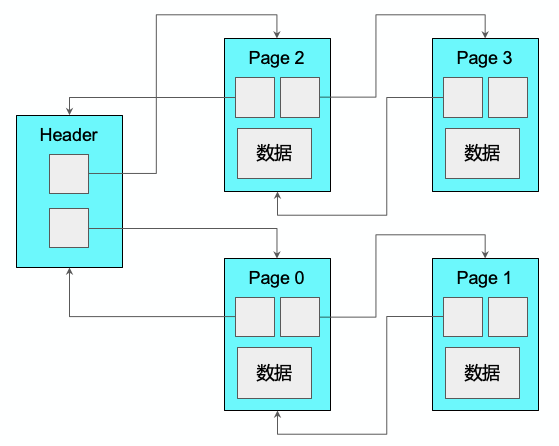
2. 文件页组织:目录方式
第二种处理方法相对更为便捷,即通过目录方式来记录所有的数据块的信息,通过目录,可以快速找出所有的数据块位置,这种结构有一个单独的模块来存储原始的meta信息,但是对一些特殊访问格式不是特别友好。
3. 文件页组织:Heap方式(Greenplum)
在Greenplum里,按顺序存储。上文我们提到,文件是分片存储的,所有的分片文件会组织在一起形成了一个逻辑上的一维空间。
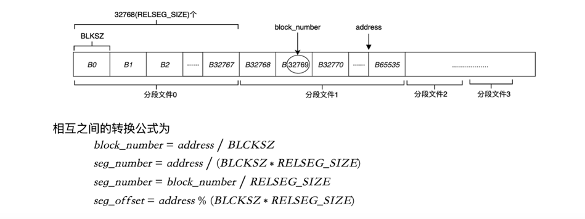
如何寻找文件编号呢?转换公式可以来求出物理位置到块号之间的一个对应关系。Greenplum涉及的块数跟PG不一样,PG中的一个块为8k大小,而Greenplum设计的是32k,可以更好的支持分析型(AP)场景。
页面结构
了解了Greenplum的页的组织,我们再来看一下页面里的结构。
基于日志存储数据
页面里对数据的存储有几种方式,第一种是基于日志存储数据。某些数据库没有单独存储的数据页,数据均存在了日志里。这种处理方式的优点是恢复时间较快,缺点是由于需要采用顺序扫描,有时效率较低。
下图例子中,从前往后的方式写入数据,生成不同的日志记录,日志记录里面存有数据,可以从记录里对数据信息进行提取。对于删除操作,不需要记录全部数据,只需记录ID信息。对于更新,只需记录更新的delta值,以及对哪个数据来做更新的信息即可。
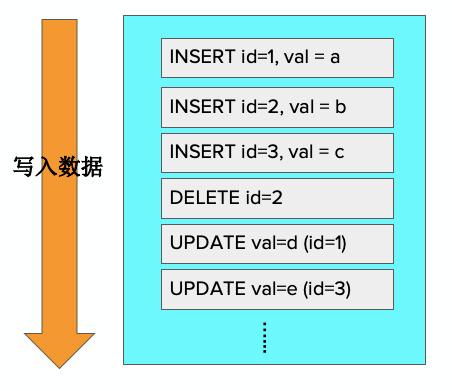
由于写是从前往后写,因此读是从后往前读,找到所有的每个记录对应的数据,把所有的信息合起来,就可以知道在某个快照时间点数据的版本。如果需要查找某一个数据,需要通过ID建立索引。
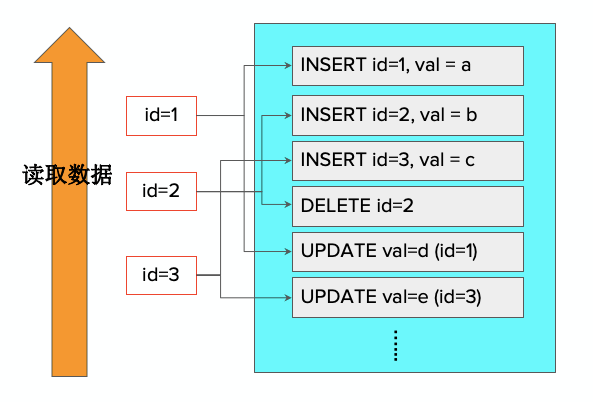
我们通过ID这个值去建一个索引,索引记录了同样的数据在日志里面多处出现的位置。读时需要把这些位置汇总,从而得出基于某个快照时间点最终的值,进而找到每条记录的数据信息。这种格式对于顺序扫描性能不佳。
页面结构:朴素方式
另外一种存储结构是朴素方式。只需对每个页面存一个信息,包含几个元组,再将元组从前往后排。


这种方式的问题在于,如果中间一些数据被删除,元组数被更改为二,此时从前往后读取数据时,无法知晓第二条数据是否已经被删除。此外,如果数据进行更新,变长数据可能会存在存不下的情况,此时将无法处理。
Heap:Greenplum存储格式
Greenplum采用Heap的方式来进行存储。下图是Greenplum经典的页面结构,页头指向了元组区域的第一个位置。前文提到过,页头,顾名思义是在页的头部,存有指向数据的指针信息,称为Item。数据放在页的末尾。中间部分留白,这样在增加数据时,可以把数据放到最后面,再在前面增加一个Item指针指向数据,通过这个方式来形成数据。每次新增数据时,Item会从前往后增加,数据会后往前增加,中间区域是空白。这种结构能够有效避免了前面两种存储格式的弊端。
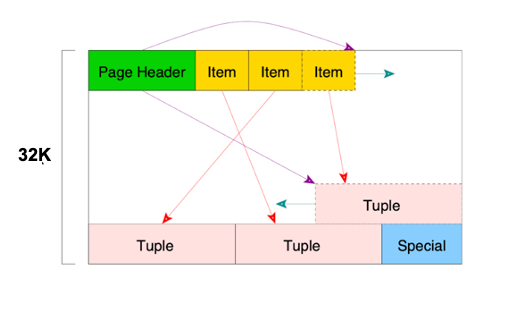
1. Heap:索引
对于索引,里面存储的是某个特定的值。而位置信息包括了数据文件里的页数信息,以及页里对应的Item信息,即Item Pointer的数据结构。位置信息指向的是一个定位到页以及页里的偏移位置的信息。通过这些信息可以快速的找到页的信息,再通过页信息指向的位置就可以快速把查找的数据加载进来
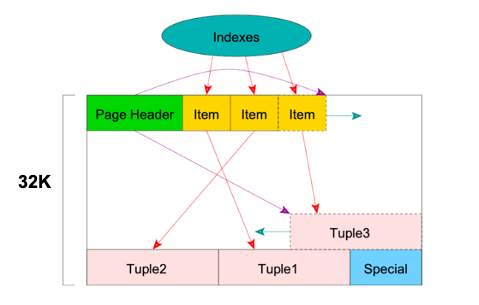
元组中存有数据可见性的信息,而索引是不存版本信息的,它会找到数据,通过数据的版本信息来判断该数据对当前的事务的快照是否可见。
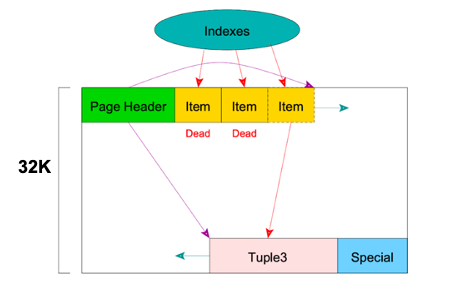
2. Heap:删除元组
如果发现数据被删除了,例如图中第二个元组被删除后,数据空间便不再被占用了,可以将空间释放。下图中,我们就可以将3元组往后挪把中间空间释放出来,减少数据碎片,此时由于数据已经被删除,第一个和第二个Item已经无用,但由于索引的存在,如果被回收填充,索引会指向新的数据导致出错,因此空间不能被回收,除非对应的索引项被删除。此时,被删除元组的Item会被标记为Dead,第三个Item指向第三个元
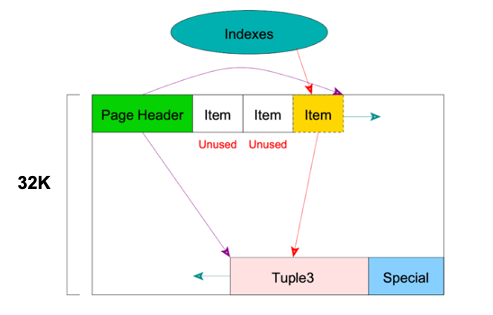
3. Heap:索引空间回收
当做索引空间回收时,会从头将索引扫描一遍,此时会发现索引指向数据是dead状态,相应的记录也不再需要。这个时候,才可以将索引里的记录信息删掉,删除后,可以标记这两个Item为Unused,从而可以被新的元组重新使用。
4. 减少索引项:Heap Only Tuple(HOT)
由于MVCC的存在,数据会存在很多版本数据,在索引里加了过多索引项,从而会让索引变得非常庞大,查询效率也会降低。索引的设计初衷是为了让访问更快,如果索引变得很庞大,访问反而变慢,就与初衷相违背。因此Greenplum做了个优化叫Heap Only Tuple(HOT)。
如果元组更新的列不是索引列,此时并不需要添加一个新的索引项。例如元组是由ID和Value组成的,索引是基于ID键创建的,如果ID号没变只是更新了Value列并且新增加的元组在相同页内,此时索引便可以复用。那么,该如何复用呢?
例如下图,索引指向的Item指向v1,v1修改为v2,此时并不需要重建索引项,只需在v1和v2之间建立一个跳转,即创立HOT链。访问时,通过HOT链便能找到最新版本的数据。通过这种方式可以减少索引的数目。
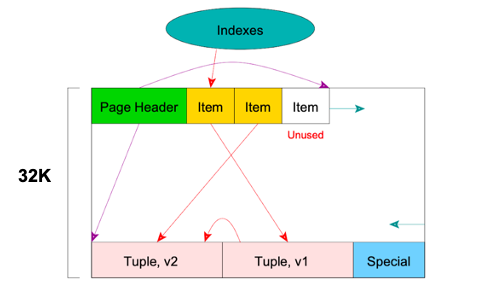
HOT链的终止有两种情况:
- 如果更新的列涉及到任何索引的列,HOT就终止了,即需要重新创建一个索引。
- 如果当前空间不够了,也就是元组放不下,只能存放在其他页面里面,此时HOT会被终止。由于跨页涉及到页面的置换,会影响读取效率,因此HOT链无法跨页。
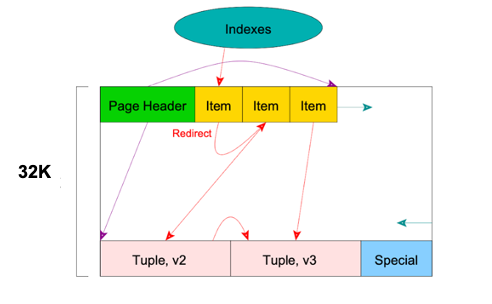
下图中v1被删除,v2更新为v3,创立HOT链指向v3,由于v1被删除,Item指针不再指向实际数据,而索引指向这个Item,此时会将这个Item以重定向的方式指向第二个Item,从而减少HOT情况下回收空间导致的错误。
元组结构
讲完了元组在页面的结构,现在我们对元组结构做一个剖析。整个元组的结构其实较为复杂,总的来说可以分为两大块:一个头部 + 一些属性。
头部会记录元组的基本属性,包括但不限于下图里列出的一些属性。属性的具体信息可以参考下图
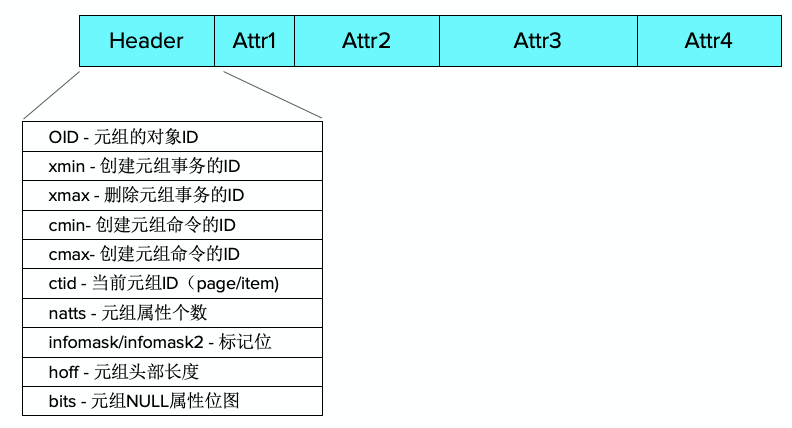
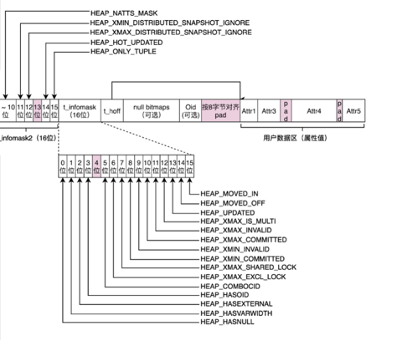
其中元组标记位里包括了很多用于特定目的的属性。HEAP_HOT_UPDATED和HEAP_ONLY_TUPLE被配合用于前文提到的索引HOT技术。下面的informask有16个位,每个位对应了不同的意义,例如HEAP_XMAX_IS_MULTI被用于需要元组加锁的情况。还有一些用于判断来加快处理的,例如HEAP_XMAX_COMMITTED被用于直接判断一些xmax事务是否已被提交而不用再去查找事务状态的文件。
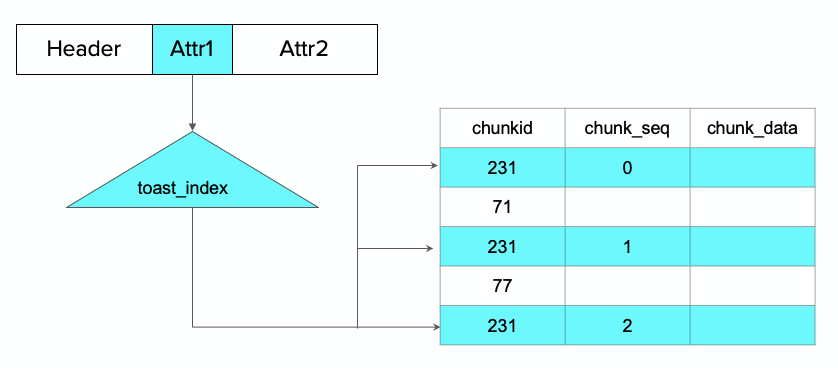
对于字符串,如果摊平存储,会导致元组非常大,在页面里32k是存不下的,读的时候需要把元组全部读出来,性能效率低下。Greenplum里采用的是线外存储(TOAST)的方式,首先它会根据用户指定的信息试图做一些压缩,压缩之后,如果能存下就可以直接存储,如果存不下的话,会采取向外扩展的方式来存储,即通过另外一个表来进行存储,这个表就是TOAST表。TOAST表会把属性分成多块来处理,每一块是一个小的元组。
下图中,属性被分为三个元组进行存储,每个元组存了一个属性对应的内容片段,所有片段按照顺序组装起来,变成相应数据。后面的data就是数据内容,把数据内容按照顺序号拼接在一起,形成真正的变长属性内容。如果进行压缩就涉及到解压,Attr中存的是ID号,通过索引可以找到所有的元组。
共享缓冲区管理
文件是由页面组成,管理读页和写页的并发控制是如何做到的呢?
Greenplum通过共享缓冲区来做到文件访问的管控。下图中,灰色部分是每个进程自己独占的数据区域,有数据段和代码段,中间这部分就是共享内存。共享内存会映射到不同进程里对应的相同的地址空间。由于映射的是同一个内存,每个进程修改共享内存的内容可以被别的进程看到。
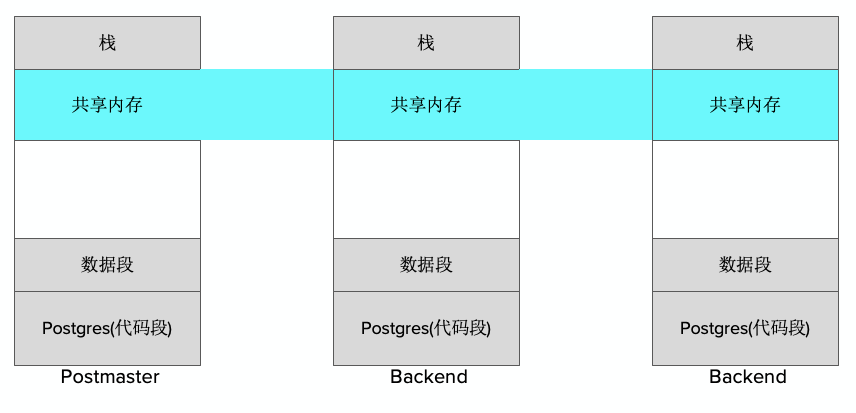
共享内存里会存储非常多的内容,具体请看下图。共享缓冲区本质上是作为数据交换的中间区域,它可以存一些并发控制相关的内容、数据交换和管道等信息。
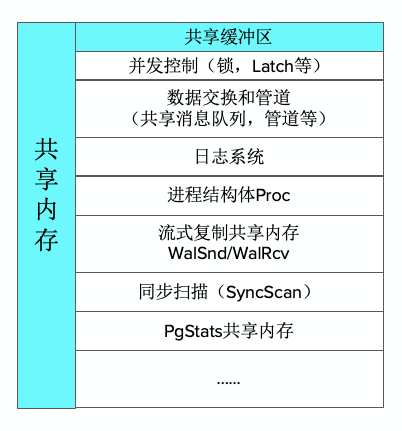
共享缓冲区(考虑随机访问与扫描多种访问模式)
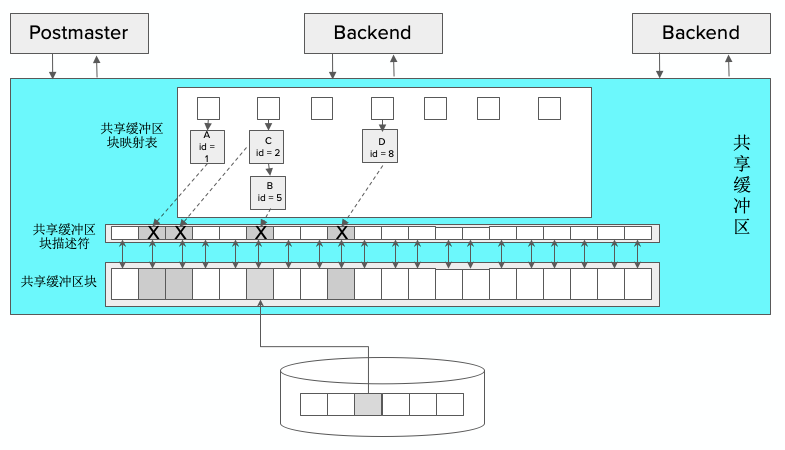
我们着重来看一下共享缓冲区。在Greenplum里,共享缓冲区里有一个Postmaster和多个Backend。下图中整个蓝色区域是共享缓冲区区域。下面是文件部分,文件会被切成块,以块来为单位进行页面的IO。共享缓冲区映射表的主要作用是,当被要求取第n块数据时,它将告知对应的是数据是在第几个缓冲区。得到数据编号后,会去对应的槽取相应的数据。数据对应的槽分为两部分,一部分是缓冲区的描述符信息和控制信息,另一个部分是关于缓冲区块的内容信息,对应于文件块中的内容。其中控制符全部存在了描述符里。
缓冲区替换算法
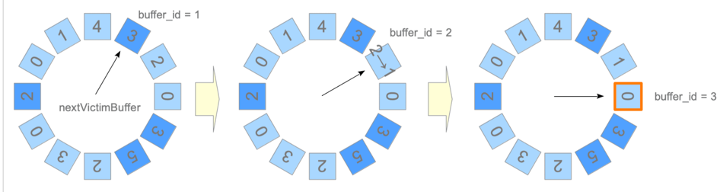
要读取文件块的内容到缓冲区里,如果缓冲区有空的,便可以直接载入。但如果所有的槽里都有内容,没有空位的话,就需要做替换。Greenplum里使用了LRU的算法来进行缓冲区的替换。该算法会沿着页面按顺序转圈,每转一圈会将当前基数减一,首先减为0的基数会被选中作为替换用的共享缓冲区。
但顺序扫描和大量插入数据可能会导致算法失效,此时就需要更细粒度的缓冲区替换策略,可以给这种顺序扫描或者需要插入大量数据的场景,固定几个缓冲区来使用,而不是把所有的缓冲区都放进替换策略,从而减少影响。
读取文件页(存在空闲缓冲区块)
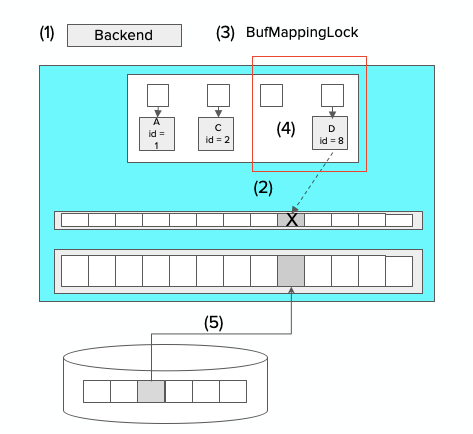
大家可以结合下图来看一下读取文件页的一个过程,
(1)开始读取特定文件块
(2)找到一个空闲缓冲区
(3)对映射表加分区锁,分区锁相比与大锁减少锁的竞争
(4)映射表中插入表项
(5)开始IO读取内容到缓冲区块中
读取到共享缓冲区后,如果有其他人访问,就可以迅速找到对应的缓冲区,从而可以直接读取。通过这种方式可以控制多个并发控制进程对文件的使用。
读取文件页(替换已有缓冲区块)
讲完有空闲缓冲区的情况,我们再来看看如果需要替换已有缓冲区块怎么办?
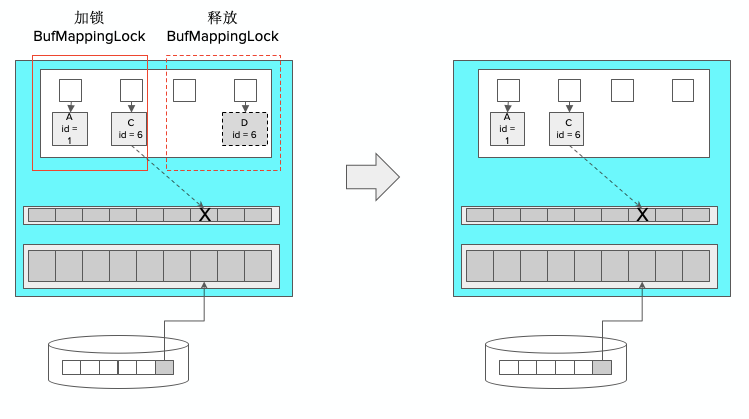
下图中,通过LRU算法,计算出将id=6的缓冲区块替换出去,替换分为多步,第一步是替换页面的现有映射,第二步是建立新的映射,然后再把数据加载进来。去掉已有映射时,需要为已有映射加一个分区的锁。
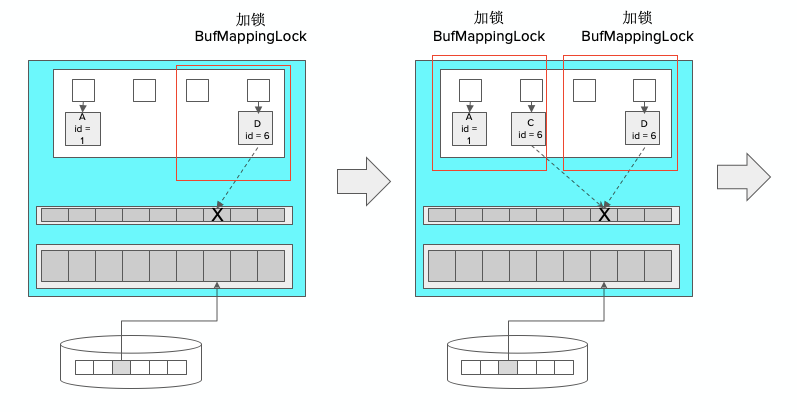
再将新的分区加上锁,将D的映射关系失效,让C使用此文件块,文件块内容再通过IO方式加进去。
这就是Greenplum存储引擎之Heap的关键知识点,希望大家通过这篇万字长文有所收获,欢迎给我们留言交流!下次活动我们不见不散!

