在之前的文章《不惧宕机,数据库高可用理论与实践》中,为大家介绍了数据库系统的高可用理论知识,以及Greenplum是如何实现高可用,为企业的数据保驾护航的。
今天我们将在上篇文章的基础上,补充介绍Greenplum事务一致性的几个重点,它们也是Greenplum可以高可用的重要前提和保证。本文将就分布式事务日志在时间线上的顺序,以及事务的提交和可见在代码层面的细节逐一分析讲解。
分布式事务日志
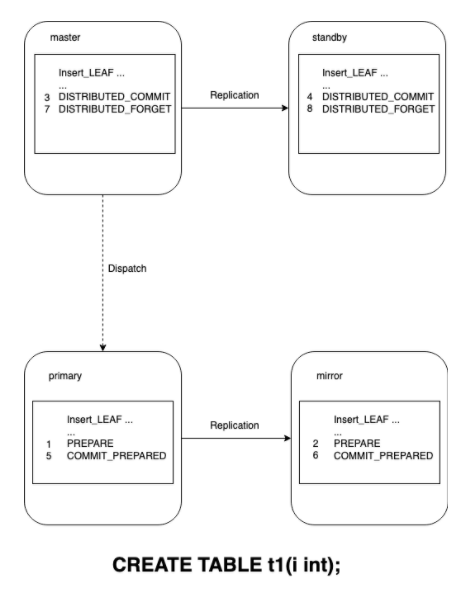
我们以 CREATE TABLE t1(i int); 为例介绍关键事务日志的时间线。随后讲解事务在各个阶段发生故障时,Greenplum怎样保证数据的一致性。
- QD/QE进程更新数据库对象,插入表格。
- QD进程通知segments执行PREPARE TRANSACTION,并等待所有primary节点上的QE返回成功。
- primary上的QE在本地执行完PREPARE TRANSACTION后,将WAL刷盘,并唤醒walsender进程,并将WAL同步到mirror本地。primary上的QE成功地将WAL同步后,返回结果给QD,至此该primary准备就绪。
- 所有的segments准备就绪后,QD在本地写入DISTRIBUTED_COMMIT日志并刷盘,然后唤醒walsender进程,并等待将日志同步至standby。
- QD进程发起两阶段提交的COMMIT PREPARED。
- primary上的QE进程执行COMMIT PREPARED。QE在本地写入COMMIT_PREPARED日志并刷盘,唤醒walsender进程后,等待将日志同步至mirror。
- primary上的QE进程等待日志成功同步至mirror后,将结果返回给QD。
- QD等待所有的segments都成功提交后,写入DISTRIBUTED_FORGET。此记录并不需要刷盘,没有它数据库也能工作。它的作用仅仅是优化了数据库恢复过程,告诉恢复进程“这个分布式事务已经成功提交(包括segments),忽略掉它,不要再尝试提交了”。
真实的WAL日志
master节点上的事务日志
rmgr: Heap len (rec/tot): 54/ 1378, tx: 986, lsn: 0/7407A748, prev 0/74075578, desc: INSERT off 13 flags 0x00, blkref #0: rel 1663/57434/7142 blk 0 FPW
rmgr: Btree len (rec/tot): 53/ 353, tx: 986, lsn: 0/7407ACB0, prev 0/7407A748, desc: INSERT_LEAF off 13; page 1, blkref #0: rel 1663/57434/6103 blk 1 FPW
rmgr: Heap len (rec/tot): 215/ 215, tx: 986, lsn: 0/7407AE18, prev 0/7407ACB0, desc: INSERT+INIT off 1 flags 0x00, blkref #0: rel 1663/57434/6052 blk 0
rmgr: Btree len (rec/tot): 94/ 94, tx: 986, lsn: 0/7407AEF0, prev 0/7407AE18, desc: NEWROOT lev 0, blkref #0: rel 1663/57434/6054 blk 1, blkref #2: rel 1663/57434/6054 blk 0
rmgr: Btree len (rec/tot): 72/ 72, tx: 986, lsn: 0/7407AF50, prev 0/7407AEF0, desc: INSERT_LEAF off 1; add length 24 item at offset 1 in page 1, blkref #0: rel 1663/57434/6054 blk 1
rmgr: Heap2 len (rec/tot): 70/ 70, tx: 986, lsn: 0/7407AF98, prev 0/7407AF50, desc: CLEAN remxid 968, blkref #0: rel 1663/57434/1249 blk 17
rmgr: Standby len (rec/tot): 42/ 42, tx: 986, lsn: 0/7407AFE0, prev 0/7407AF98, desc: LOCK xid 986 db 57434 rel 57435
rmgr: Transaction len (rec/tot): 469/ 469, tx: 986, lsn: 0/7407B010, prev 0/7407AFE0, desc: DISTRIBUTED_COMMIT distributed commit 2021-02-22 17:30:36.383408 UTC gxid = 8730
rmgr: Transaction len (rec/tot): 34/ 34, tx: 986, lsn: 0/7407B1E8, prev 0/7407B010, desc: DISTRIBUTED_FORGET distributed forget gxid = 8730segment上的事务日志
rmgr: Heap len (rec/tot): 54/ 1378, tx: 885, lsn: 0/881D8998, prev 0/881D3758, desc: INSERT off 13 flags 0x00, blkref #0: rel 1663/57434/7142 blk 0 FPW
rmgr: Btree len (rec/tot): 53/ 353, tx: 885, lsn: 0/881D8F00, prev 0/881D8998, desc: INSERT_LEAF off 13; page 1, blkref #0: rel 1663/57434/6103 blk 1 FPW
rmgr: Standby len (rec/tot): 42/ 42, tx: 885, lsn: 0/881D9068, prev 0/881D8F00, desc: LOCK xid 885 db 57434 rel 57435
rmgr: Transaction len (rec/tot): 1005/ 1005, tx: 885, lsn: 0/881D9098, prev 0/881D9068, desc: PREPARE at = 2021-02-22 17:30:36.373860 UTC; gid = 8730
rmgr: Transaction len (rec/tot): 465/ 465, tx: 0, lsn: 0/881D9488, prev 0/881D9098, desc: COMMIT_PREPARED 885: 2021-02-22 17:30:36.386186 UTC; inval msgs: catcache 80 catcache 79 catcache 80 catcache 79 catcache 53 catcache 52 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 7 catcache 6 catcache 34 snapshot 2608 relcache 57435故障分析
事务开始后,完成DISTRIBUTED_COMMIT写入之前,一旦master(严格来说是Query Dispatch, i.e. QD进程)或任一参与事务的primary(Query Execute, i.e. QE进程)发生错误/故障,事务都会被回滚。如果mirror发生故障,致使replication发生中断,primary上的FTS handler会报告给FTS probe进程。紧接着,FTS服务会请求primary设置synchronous_standby_names为空值,primary不再将WAL同步到它所对应的mirror上,并唤醒等待同步WAL的backend进程。
只要图中的步骤3完成(master节点依旧存活),不管segment节点是否临时掉电,分布式事务都最终完成。因为分布式提交已经持久化地记录在master节点上,只要master节点还活着,它都可以去尝试请求segment提交已经处于prepared状态的事务。现实情况下,处于prepared状态的事务仍有极小的可能无法成功提交事务,一般是数据库BUG或磁盘故障。除非primary和mirror同时出现故障,segment上的事务都能成功提交。
如果QD进程在图中步骤3完成后,master节点突然掉电,那么这个分布式事务是否可以最终提交?取决于DBA等待恢复master,还是将standby提升为新的master提交服务。如果是前者,那么这个事务依旧被认为是分布式提交了,DTX recovery进程会尝试提交已经就绪的事务。如果DBA选择提升standby,那么这个事务的分布式提交日志在standby上丢失,事务会被取消,并且是永久性的,不管原来的master节点之后怎样。
如果primary在图中步骤3完成时,突然挂掉,FTS probe会将它对应的mirror提升为新的primary,然后再发起新的请求来完成segment本地事务提交。
事务提交与可见
事务的WAL记录(COMMIT/COMMIT_PREPARED)决定事务是否被提交并最终可见。写入WAL记录COMMIT/COMMIT_PREPARED并不意味着事务瞬间对其他事务可见。backend进程将WAL刷盘后,保证事务在掉电重启后依旧可以完成并最终可见,但在事务可见之前,backend进程还需要更新内存中的数据结构,使得事务在下一次事务快照(Snapshot)可见。
首先backend计算事务及子事务的最新事务ID,并将用来更新ShmemVariableCache->latestCompletedXid。
然后,backend写入(并刷盘)WAL记录COMMIT_PREPARED和提交日志(commit log)。在此之后,由于该backend的PGPROC并没有更新,事务对其他进程依旧不可见。
接着,backend进程以互斥模式取得ProcArrayLock后,更新PGPROC和ShmemVariableCache->latestCompletedXid,并从procArray删除PGPROC,最后释放锁ProcArrayLock。如果此时有另外的backend进程调用GetSnapshotData()获取事务快照,它被会阻塞在拿锁操作上。
最后,其他backend继续执行GetSnapshotData(),这个时候,刚提交的事务对其他backend进程可见了。
如果primary在提交与可见之间发生故障,执行恢复操作后,事务后依旧可见。这是因为共享内存被重置,重做事务日志后,事务会完成并可见。
FinishPreparedTransaction()
{
...
/* compute latestXid among all children */
latestXid = TransactionIdLatest(xid, hdr->nsubxacts, children);
if (isCommit)
RecordTransactionCommitPrepared(xid,
hdr->nsubxacts, children,
hdr->ncommitrels, commitrels,
hdr->ncommitdbs, commitdbs,
hdr->ninvalmsgs, invalmsgs,
hdr->initfileinval, gid);
else
RecordTransactionAbortPrepared(xid,
hdr->nsubxacts, children,
hdr->nabortrels, abortrels,
hdr->nabortdbs, abortdbs,
gid);
ProcArrayRemove(proc, latestXid);
gxact->valid = false;
…
}
ProcArrayRemove(PGPROC *proc, TransactionId latestXid)
{
ProcArrayStruct *arrayP = procArray;
int index;
LWLockAcquire(ProcArrayLock, LW_EXCLUSIVE);
if (TransactionIdIsValid(latestXid))
{
Assert(TransactionIdIsValid(allPgXact[proc->pgprocno].xid));
/* Advance global latestCompletedXid while holding the lock */
if (TransactionIdPrecedes(ShmemVariableCache->latestCompletedXid,
latestXid))
ShmemVariableCache->latestCompletedXid = latestXid;
}
// REMOVE PGPROC from procArray
…
}
Snapshot
GetSnapshotData(Snapshot snapshot, DtxContext distributedTransactionContext)
{
...
/*
* It is sufficient to get shared lock on ProcArrayLock, even if we are
* going to set MyPgXact->xmin.
*/
LWLockAcquire(ProcArrayLock, LW_SHARED);
/* xmax is always latestCompletedXid + 1 */
xmax = ShmemVariableCache->latestCompletedXid;
Assert(TransactionIdIsNormal(xmax));
TransactionIdAdvance(xmax);
/* initialize xmin calculation with xmax */
globalxmin = xmin = xmax;
…
for (index = 0; index < numProcs; index++)
{
...
xid = UINT32_ACCESS_ONCE(pgxact->xid);
/* Add XID to snapshot. */
snapshot->xip[count++] = xid;
…
}
LWLockRelease(ProcArrayLock);
...
}本文对分布式事务中几个关键日志点进行了介绍和简单分析,包括它们的时间线。通过这些约束,主节点在任意时刻发生故障,Greenplum都可以达到事务一致性。在主节点发生故障时,数据库系统都可以安全地将备节点提升为新的主节点,从而达到高可用的目标。点击文末“阅读原文”,获取Greenplum中文资源。
