外部表是greenplum的一种数据表,它与普通表不同的地方是:外部表是用来访问存储在greenplum数据库之外的数据。如普通表一样,可使用SQL对外部表进行查询和插入操作。外部表主要用于Greenplum数据的导入及导出。
本文按照以下顺序介绍外部表:外部表创建和使用,外部表读写实现机制,外部数据转换,外部表的查询计划,外部表的事务,使用可读外部表加载数据。
一 外部表创建和使用
Greenplum数据库在创建一个外部表时,需要声明外部数据的LOCATION和FORMAT。LOCATION指定外部数据URL,包含外部数据读写协议;FORMAT指定外部数据格式,如TEXT、CSV等,greenplum会根据指定的格式,实现外部数据和数据库内部tuple的转换。
创建外部表之后,可以与操作普通表一样,对其进行select、insert等操作。外部表分为可读外部表和可写外部表,可读外部表可以执行select 操作,对可写外部表只能执行insert操作,不能对其进行update和delete。
1.1 可读外部表
创建可读外部表时声明READABLE,或者直接使用缺省值。数据源可以是文件,gpfdist 进程(后面介绍),或者可执行程序。例如:
CREATE EXTERNAL TABLE ext_expenses (name text, date date, amount float4, category text, desc1 text )
LOCATION ('file://filehost/data/international/*',
'file://filehost/data/regional/*',
'file://filehost/data/supplement/*.csv')
FORMAT 'CSV';上面的例子从多个位置的文件创建一个可读外部表ext_expenses。
LOCATION 指定外部数据URL, 数据源地是’file://filehost/data/international/*’, ‘file://filehost/data/regional/*’, ‘file://filehost/data/supplement/*.csv’ (其中file是外部数据读写协议, filehost是文件所在的机器hostname)。
FORMAT指定外部数据格式是csv。
可读外部表创建成功后,可以使用select做查询操作。比如从外部表ext_expenses查询上述外部数据源(文件)中所有amount大于10000的记录:
select * from ext_expenses where amount>10000;1.2 可写外部表
创建可写外部表时需要声明WRITABLE。数据可以写入到gpfdist或者可执行程序,不支持写入本地文件。例:
CREATE WRITABLE EXTERNAL TABLE sales_out (LIKE sales)
LOCATION ('gpfdist://etl1:8081/sales.out')
FORMAT 'TEXT' ( DELIMITER '|' NULL ' ')
DISTRIBUTED BY (txn_id);上面的例子创建了一个输出到gpflist的可写外部表sales_out。
sales是greenplum数据库中的一个普通表,作为外部表sales_out的内部数据源。
LOCATION指定外部数据URL,通过gpfdist进程将数据写入sales.out文件。
FORMAT指定外部数据格式是text。
可写外部表创建成功后,可以使用insert从greenplum数据库中导出数据。比如将sales表中customer_id=123的数据写入上述的sales.out文件:
INSERT INTO sales_out SELECT * FROM sales WHERE customer_id=123;二 外部数据表读写实现机制
这一节介绍外部表的不同类型的数据源,以及数据读写的实现机制。
外部表的数据源可分为四类:
- File,本地文件
- Execute,外部可执行程序
- Gpfdist,实现了gp_proto协议的http server
- Custom,预留的用于扩展外部表的存储类型接口
Greenplum实现读写各种类型数据源的代码在src/backend/access/external目录下。其中url.c 是外部表数据读写的入口,url_file.c、url_execute.c、url_curl.c、url_custom.c实现了url.c中的接口,分别读写本地文件、外部可执行程序、gpfdist进程(http server)、扩展的外部数据存储类型的数据。
url.c对外的方法如下:
- url_fopen(): 打开外部数据文件
- url_fclose():关闭外部数据文件
- url_feof():判断外部数据文件是否结尾
- url_ferror():获取外部文件操作错误信息
- url_fread(): 读取外部文件
- url_fwrite(): 写外部文件
- url_flush(): flush外部文件
2.1 file
file类型的外部数据URL格式是:file://host/path
URL中file指明了数据读写协议,host在下文执行计划部分会讲到。
file 类型的外部数据只支持读取,不支持写入。读取时不仅可以读一个文件,也可以读取多个文件,例如file://filehost/data/international/*。
2.2 execute
execute类型的外部数据URL格式是:EXECUTE ‘/var/load_scripts/get_log_data.sh’
其中execute指明了数据读写协议,/var/load_scripts/get_log_data.sh指定可执行程序。
execute类型不仅支持读取外部数据,同时也支持写入外部数据。
Greenplum外部表通过执行定义的外部执行程序:例如get_log_data.sh,和管道实现execute类型数据的读写。读外部数据:将程序的标准输出的作为数据来源;向外部写数据:将外部程序的标准输入作为数据表中的数据。
2.3 gpfdist
gpfdist是greenplum数据库的并行文件分发程序。代码在src/bin/gpfdist/下。
启动gpfdist进程的命令如下:
gpfdist -d /tmp/test/ -p 8081其中-d /tmp/test指定了gpfdist的工作目录,-p 8081是gpfdist进程的端口号。
gpfdist进程管理的文件在工作目录/tmp/test下。client向gpfdist 进程发出读请求时,设置要读取文件的path,则可以读取到/tmp/test/path的文件。例如/tmp/test下有两个目录d1,d2,client要读取d1下的文件,则需要设置path=/d1。
gpfdist的主要功能是实现了并行分发文件。当多个client同时读取同一文件,gpfdist不会把文件内容整体发送给每个client,而是把文件进行切分,每个client只得到文件中的一部分。例如有n 个client 同时向gpfdist进程发送读取同一path下文件的请求, path下全部文件大小是n*m*block_size,gpfdist首先从文件中读出n 个数据块分发给这n个client,每个client处理完读取到的数据块后,可以再次向gpfdist发送读数据请求,直到gpfdist 管理的path下的文件被全部读完为止。当client是greenplum的segment时,可以实现segments对外部数据的并行处理。
gpfdist中有一个session的概念。session管理一组并发读或写同一目录文件得request。Session维护request列表,记录文件读取的offset,维护文件的读取状态,用于实现文件的读写分发。
Session处理相关的函数如下:
- session_attach(): 把一个request加入到一个session钟
- session_detach(): 把request从session中删除
- session_end(): 结束一个session,把session打开的文件关闭
- session_free():删除session
- session_get_block():session读取path下文件一个block数据
- sessions_cleanup():清理过期session
gpfdist怎么判断client的request请求应该属于哪个session呢?
对于greenplum数据库来说,用户在执行查询或者插入语句的时候,segments会并行地向gpfdist进程发请求(可以看后面的查询计划部分),所以属于同一个transaction的request应该放到同一个session中,但同一个transaction中可以包含多条SQL命令,存在两条SQL需要访问同一个外部表的可能;同一条SQL中也可能不止一次扫描外部表,因此gpfdist定义了每个session的 key:
transactionId + commandId + scanNo + path
- transactionId: 事务号
- commandId: 属于同一个事务的SQL 命令编号
- scanNo: 一条SQL命令的plan对外部表扫描的编号。
request中有这几个参数,可以据此判断出该request属于哪个session。
Gpfdist是基于libevent实现的,处理一个读request的步骤如下:
- doAccept :得到一个request请求
- do_read_request:解析处理一个request请求
- attach_session: request加入到对应的session中
- handle_get_request or handle_post_request: 根据request是get还是post调用对应的处理函数
- do_write: 如果是get请求则调用do_write方法,do_write 首先调用sesson_get_block读取数据,然后向client发送该数据
- 如果是post 的请求,则在handle_post_request中调用fstream_write ,把数据写入文件
- request_end: 结束request
- session_detach/session_end: 把request从session中删除
三 外部数据转换
上一节介绍了greenplum数据库怎么读写各种类型的外部数据,本节介绍greenplum数据库怎么转换外部数据。
数据转换的代码在src/backend/access/external/fileam.c
Greenplum数据库对外部数据只有select和insert两种操作。Select操作是读取外部数据每次获取一个tuple(数据表中的一行数据)。Insert 操作是每次向外部写入一个tuple。外部表读取外部数据的时候是按照数据块读取的,那么select和insert时需要把外部数据块再进行分割处理,转换成一个一个的tuple。这一过程的实现方法是fileam.c中的externalgettup 。
外部数据的格式多种多样,目前greenplum数据库默认支持csv和text。其他格式的数据也是支持的,但是需要用户自己写把数据块转换成tuple的formatter。
四 外部表查询计划
在解读查询计划之前,先简单了解一下greenplum数据库的架构,如下图所示:
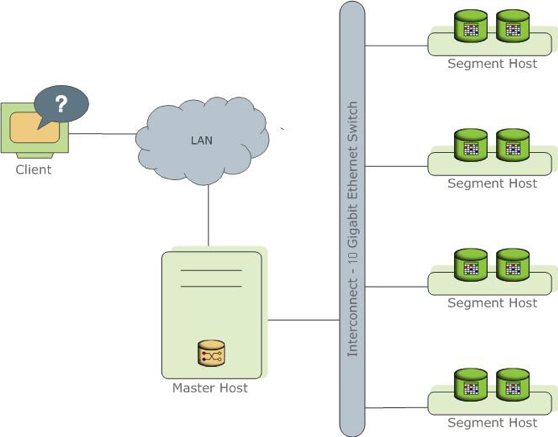
Greeplum数据库是由一个master节点和多个segment节点组成的。Master负责接收查询请求。数据分布在多个segment节点上,每个segment只存储数据表的一部分数据。Master接收请求后,生成查询计划,然后把查询计划分发给每个segment;多个segment并发地执行查询计划,并把查询结果发送给master;由master汇总结果,返回给client。
下面分别描述普通表和外部表的查询计划,并介绍不同类型外部表的的数据分配方式。
4.1 普通表的查询计划
explain select * from expenses;
QUERY PLAN
-----------------------------------------------------------------
Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..344.00 rows=24400 width=104)
-> Seq Scan on ext (cost=0.00..344.00 rows=8134 width=104)
expenses 是一个普通表,查询计划分为两步:
第一步,每个segment上expenses表行seq scan(扫描表)。
第二步,每个segment把得到的数据发送给master (Gather Motion)
4.2 外部表的查询计划
explain select * from ext_expenses;
QUERY PLAN
-----------------------------------------------------------------
Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..11000.00 rows=1000000 width=104)
-> External Scan on ext_expenses (cost=0.00..11000.00 rows=333334 width=104)
ext_expenses 是一个外部表,查询计划同样分为两步:
第一步,每个segment上对ext_expenses 外部表行external scan(扫描表)。
第二步,每个segment把得到的数据发送给master (Gather Motion)
和普通表的查询计划一样,数据也是通过每个segment 上做数据扫描获取,只是把seq scan换成了extenral scan。那么每个segment怎么知道external scan 需要扫描的是哪些外部数据文件呢?
在生成查询计划时,master会为每个segment分配它需要读取的外部数据文件。不同类型的外部表数据分配方式不同。
1)file
会根据filehost分配外部表数据文件。如果segment的host和filehost相同,则filehost的数据文件由该segment处理。每个filehost的数据只能最多被一个segment读取(多个segment可能在同一个host上)。
2)execute
可以指定在master上,或者全部segment上,或者部分segment上执行命令获取外部数据。
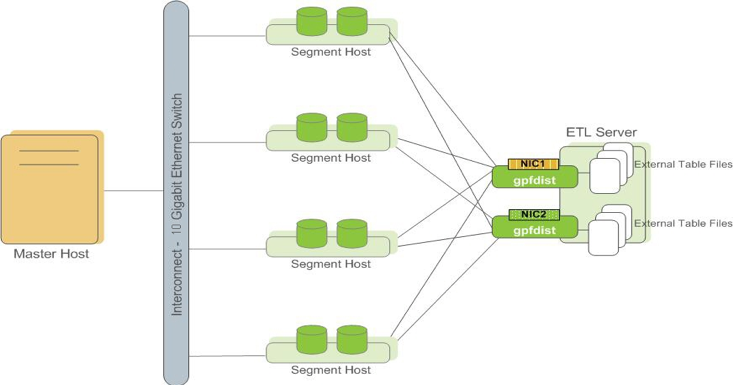
3) gpfdist
CREATE EXTERNAL TABLE ext_customer (id int, name text, sponsor text) LOCATION ( 'gpfdist://filehost1:8081/*.csv', 'gpfdist://filehost2:8081/*.csv' ) FORMAT 'CSV' ( DELIMITER ',');
如果有m个gpfdist,n个segment, 要求m<=n
则 n个segment对应的gpfdist是:1,2,3,…m,1,2,3,…m…n%m
第1,m+1, 2m+1… segment 并行读写同一个gpfdist。
可以设置gp_external_max_segs,限制每个gpfdist做多被多少个segment读取。
如果m*gp_external_max_segs < n,那么某些segment将无外部数据可读。
五 外部表的事务
Greenplum数据库基于mvcc实现事务的隔离,使用Write-Ahead Logging (WAL) 把事务的redo 操作记录到xlog中,实现事务的持久化和一致性。在greenplum数据库普通表中,每个tuple都记录有xin,xmax信息,是实现mvcc必须的字段。外部表与普通表不同:
- 对于可读外部表,数据中没有事务相关的xmin,xmax字段。因此在scan外部数据的时候不需要关心数据的可见性,直接把外部的数据返回给执行器即可。
- 对于可写外部表,写到外部的数据不能包含xmin,xmax等相关字段,所以无法实现事务隔离等功能。因此,对可写外部表做insert操作的时候,不会分配transctionId。可写外部表没有事务的功能,无法做回滚操作,也不会对外部表的操作记录xlog。
六 使用可读外部表加载数据
可读外部表通常用于向greenplum数据库加载数据:
INSERT INTO normal_table SELECT * FROM external_table;explain insert into normal_table select * from external_table;
QUERY PLAN
-----------------------------------------------------------------
Insert on normal_table (cost=0.00..11000.00 rows=333334 width=4)
-> Redistribute Motion 3:3 (slice1; segments: 3) (cost=0.00..11000.00 rows=333334 width=4)
Hash Key: external_table.a
-> External Scan on external_table (cost=0.00..11000.00 rows=333334 width=4)
假设normal_table是greenplum数据库中的一个普通表, external_table是一个外部表。加载数据的过程分为三步:
- 扫描外部表,获取tuple。
- 根据normal_table的distribution key,对external table 中的tuple进行hash,并redistribute 到对应的segment上。
- 把tuple插入到该segment普通数据表中。
基于外部表的功能,Greenplum实现了许多ETL工具,比如gpload 和gpss。
在使用外部表向数据库导入数据的时候,默认如果数据中任何一行包含错误,则整个导入数据的SQL就会失败,整个导入数据的insert transaction会回滚,不会有任何数据插入到目标表。
需要放宽这一限制,可以在创建外部表时定义SEGMENT REJECT LIMIT 。当扫描外部表遇到错误的时候,只要错误行数小于SEGMENT REJECT LIMIT的值,则继续扫描外部表且继续执行数据加载。SEGMENT REJECT LIMIT 是对每个segment节点生效的,每个segment节点上单独计算错误行数。当任意一个segment 节点上的错误行数达到SEGMENT REJECT LIMIT,则SQL执行失败。
本文作者:王晓冉,现任Pivotal研发工程师。目前主要负责GPkafka工作,核心参与kafka流数据导入greenplum数据库工具的开发与设计。此前参与了Postgres Merge工作。在加入Pivotal前曾在小米的支付部门参与软件研发工作。研究生毕业于中国科学院软件所软件工程专业。

