Greenplum是一个大规模并行处理数据库,它由一个master和多个segment组成,其数据按照设定的分布策略分布于各个segment上。数据表的单个行会被分配到一个或多个segment上,但是有这么多的segment,它到底会被分到哪个或哪些segment上呢?分布策略会告诉我们。
分布策略
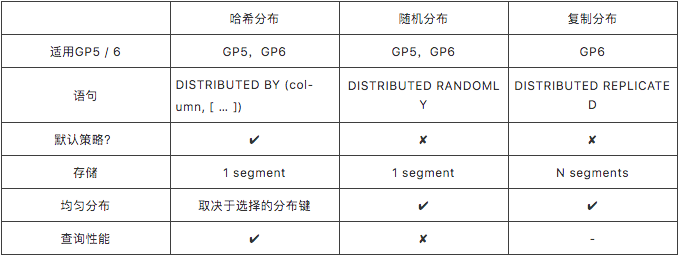
在Greenplum 5中,有2种分布策略:
- 哈希分布
- 随机分布
在Greenplum 6中,添加了另一个策略:
- 哈希分布
- 随机分布
- 复制分布
数据表的单个行会被分配到一个或多个segment上,但是有这么多的segment,它到底会被分到哪个或哪些segment上呢?分布策略会告诉我们。
哈希分布:
要使用这一策略,需要在创建表使用 “DISTRIBUTED BY(column,[…])” 子句。
散列算法使分布键将每一行分配给特定segment。相同值的键将始终散列到同一个segment。选择唯一的分布键(例如Primary Key)将确保较均匀的数据分布。哈希分布是表的默认分布策略。
如果创建表时未提供DISTRIBUTED子句,则将PRIMARY KEY(如果表真的有的话)或表的第一个合格列用作分布键。什么类型的列是合格列呢?几何类型或用户自定义数据类型的列不能用作Greenplum分布键列。如果表中没有合格的列,则退化为随机分布策略。
但是,如果未提供DISTRIBUTED子句,Greenplum最后会选择哪种分布策略还会受其它因素的影响,例如:GUC gp_create_table_random_default_distribution和当时使用的优化器(optimizer)也将影响最终决定。因此,请千万不要忘记在CREATE TABLE时添加DISTRIBUTED BY子句。否则,表的分布策略可能是只薛定谔的猫。
随机分布:
要使用这一策略,需要在创建表使用 “DISTRIBUTED RANDOMLY” 子句。
随机分布会将数据行按到来顺序依次循环发送到各个segment上。与哈希分布策略不同,具有相同值的数据行不一定位于同一个segment上。虽然随机分布确保了数据的平均分布,但只要有可能,应该尽量选择哈希分布策略,哈希分布的性能更加优良。
复制分布:
这种分布策略是GPDB 6的新增特性。
Greenplum数据分布和分区策略
要使用这一策略,需要在创建表使用 “DISTRIBUTED REPLICATED” 子句。
Greenplum数据库将每行数据分配到每个segment上。这种分布策略下,表数据将均匀分布,因为每个segment都存储着同样的数据行。当您需要在segment上执行用户自定义的函数且这些函数需要访问表中的所有行时,就需要用到复制分布策略。或者当有大表与小表join,把足够小的表指定为replicated也可能提升性能。
请注意,有一个例外:catalog表没有分布策略。
关于3项策略的摘要:
分区策略
现在让我们看一下分区,对于Greenplum新手用户,分区的概念会很容易地与分布混淆,其实分布与分区有根本上的的不同。分布是对存储的数据进行物理划分,而分区则是逻辑划分。
分区是通过 “PARTITION BY” 子句完成的,它允许将一个大表划分为多个子表。“SUBPARTITION BY” 子句可以将子表划分为更小的表 。从理论上讲,Greenplum对于根表(root table)可以拥有多少级(level)或多少个分区表(partitioned table)并没有限制,但是对于任一级分区(表的层次结构级别),一个分区表最多可以有32,767个子分区表。
当只考虑分布时,可以只把分区表当作一个普通表。对于一个根表来说,它的数据首先会被分配到某个分区表,然后单个分区表会像普通表一样根据分区表的分布策略分布在Greenplum的各个segments上,这与任何未分区表相同。Greenplum数据库中的表物理地分布在Greenplum各个segments上,使并行查询处理成为可能。表分区是一种逻辑上划分大表的工具,可提高查询性能并促进数据仓库维护任务。分区不会更改表数据在segment之间的物理分布。
Greenplum支持以下分区类型:
- 范围分区(RANGE):根据数字范围(例如日期或价格)对数据进行划分。
- 列表分区(LIST):基于值列表的数据划分,例如销售地区或产品线。
- 两种类型的组合。
对大表进行分区,将提高查询性能并简化数据库的维护任务,例如将旧数据滚动移除出数据库。
但是不要创建超出您需要的分区。创建过多的分区可能会拖慢管理和维护的速度,例如清理,恢复segment,扩展集群,检查磁盘使用情况等等。
除非查询优化器可以根据查询谓词修剪分区,否则使用分区不会提高查询性能。需要依次扫描各个分区表的查询比只需扫描无分区的根表的查询运行得慢,因此,如果你的查询中很少能用上分区裁剪,请尽量尝试避免对表进行分区。在GPCC中,可以检查查询监视器中的可视计划,以防扫描无关分区。 您还可能会遇到另一种分区:默认分区。
当进来的数据与所有的分区不匹配时,它将被插入默认分区。如果分区设计没有默认分区,它将拒绝其插入操作。
默认分区是一把双刃剑,有了它,表的操作很安全,但是也可能会掩盖问题。
假设您有一个表,并根据“age”列创建分区。它定义了一个LIST,当数据行的年龄为1时,它进入Partition1;当年龄为2时,它进入Partition2,…,当年龄为100时,它进入Partition100。但是有一天,一个101岁的人来了,BANG,错误发生了,因为您尚未为age = 101创建分区,所以也没有partition101表。这个人无处可去。
如果您为该表创建了默认分区,则101岁的老人将转到该默认分区。问题解决了,大家都很开心。
而假设某一天人类的寿命变得更长,比如200岁,那么100岁以上的人都将被分到默认分区。默认分区会被撑的越来越大,如果没有人注意,查询就会越来越慢,因为该分区太大,以致于分区修剪并无多大效果。既然表的这些分布和分区策略如何重要,您可能会问:我们如何监控这些情况,以及及早发现异常。
我们将在下一篇《GPCC如何提供帮助》详细解答。
关于作者
杨茹,Pivotal软件工程师,Greenplum Command Center(GPCC)全栈工程师。毕业于南开大学自动化系,长期从事一线软件开发工作,是GPCC Table Browser功能的核心开发人员之一。

