Greenplum 作为全球领先的开源大数据平台,被广泛应用于包括金融、保险、证券、通信、航空、物流、零售、媒体、政府、医疗、制造、能源等行业。而将多个源端数据抽取、转换并加载到 Greenplum 数据库可能是目前很多用户较为关心的场景。
在数据集成方面,除了自己写程序或脚本来实现特定的功能,有一款顺手的ETL工具能大大提升工作效率。目前市场上现存的ETL工具或有部分ETL的CDC工具五花八门,老牌产品有Informatica、Datastage、Kettle 等,新秀有 NiFi、HVR 等。从今天开始,陆续给大家分享一些ETL相关的内容,分享中有任何建议请留言沟通。
Kettle简介
话不多说,今天开始介绍的一系列文章都与 Kettle 相关,Kettle 这个ETL工具集,允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。它是一款开源的ETL工具,纯java编写,可以在 Windows、Linux、Unix(包括Mac)上运行,运行高效稳定,图形化界面使用方便,可以说是目前开源产品中用户体验最好的产品。但是在监控和集群运行方面仍然存在短板(后期在介绍NiFi的时候会体会更深)。
Kettle 起初由开发大神 MATT 开源,其目的就是统一多个数据源数据并输出,目前它被日立公司收购,目前官方名称为 Data Integration,已经发展到 Data Integration 9.x 版本。所以大家可能会在百度搜索时看到很多概念,请不要让这些噪音混淆了你的判断,你大爷仍然是你大爷,Kettle 仍然可以免费下载使用。
随着 Kettle 版本的更迭,所支持的产品也越来越多,几乎包含了目前我们所能遇到的绝大部分产品。当然功能越全,软件包就越大,我在这里采用的是 Kettle 7.0 版本,用的比较顺手而已(当然我自己认为 6.x\7.x 版本比较经典,国内好多厂商都是基于这两个版本的 Kettle 进行的国产化),大家日常可以自行选择版本。
Kettle安装
Kettle 安装简单,由于其基于 Java 开发,所以首先需要在对应的环境下安装 JDK,然后将下载的 Kettle 安装包解压缩,点击 Data Integration 文件夹下的 spoon.sh/bat 运行即可,这里最需要关注的是 Kettle 版本与 JDK 版本的对应关系。
Kettle下载地址
传送门 –> https://sourceforge.net/projects/pentaho/files/
参考资料
PDI 官方文档:https://help.pentaho.com/Documentation
常见问题解答
传送门 –> https://wiki.pentaho.com/display/EAI/Beginners+FAQ
与JDK对应关系
官方文档指出:Since Kettle version 5 you need Java 7 (aka 1.7), download this version from Oracle(http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html). When the right version is not found on the path (verify with java -version on a command line) you can set this within the Spoon.bat file (see the set PATH line).
上面说的比较笼统,意指只要安装JDK 1.7版本即可。
在实际使用过程中,如果您发现启动报错或有卡住不动的情形,可以简单参考以下对应关系(仅为个人经验)。
Kettle 5.x --> JDK 1.6/JDK 1.7
Kettle 6.x --> JDK 1.7/JDK 1.8
Kettle 7.x/8.x --> JDK 1.8Kettle 在 Mac 平台的安装注意事项
我这里下载了 Kettle 7.1 版本的安装包:pdi-ce-7.1.0.0-12.zip。解压完后,如果直接点击 Data Integration.app(Mac下启动方式),程序是没有任何反应的,但是直接在 terminal 中执行 spoon.sh 可以启动,从 terminal 启动呢,极有可能遇到菜单栏和资源库 Connect 按钮无法点击问题。
这个问题大概是因为 macOS 的安全策略禁止了这个应用去访问一些数据,此处只需要把这个应用的一些权限删除即可,正确的操作姿势应该是:
$ cd data-integration
$ sudo xattr -dr com.apple.quarantine . Data\ Integration.app
将整个文件夹拖到【应用程序】文件夹,通过Mac的程序坞打开
Kettle 在 Windows/Linux/Unix 平台的安装注意事项
在 Mac 之外的平台使用 Kettle,只需要执行压缩包下的 Spoon.bat(windows) 或 spoon.sh(Linux/Unix) 即可。这里默认您已经安装了对应版本的JDK并配置了Java环境变量。
入库之insert
Kettle的作业与转换
作业(Job)和转换(Transformation)是 Kettle Spoon 设计器的核心两个内容,这两块内容构建了整个 Kettle 工作流程的基础。
- 转换(Transformation):主要是针对数据的各种处理,一个转换里可以包 含多个步骤(Step),每个步骤定义了对数据流中数据的一种操作,整个转换定义了一条数据流。
- 作业(Job):更加趋向于流程控制。一个作业里包括多个作业项(Job Entry),一个作业项代表了一项工作,而转换也是一种作业项,一个作业里可以包含多个转换。当然作业里也包括其他项,例如:开始、结束、FTP访问等。
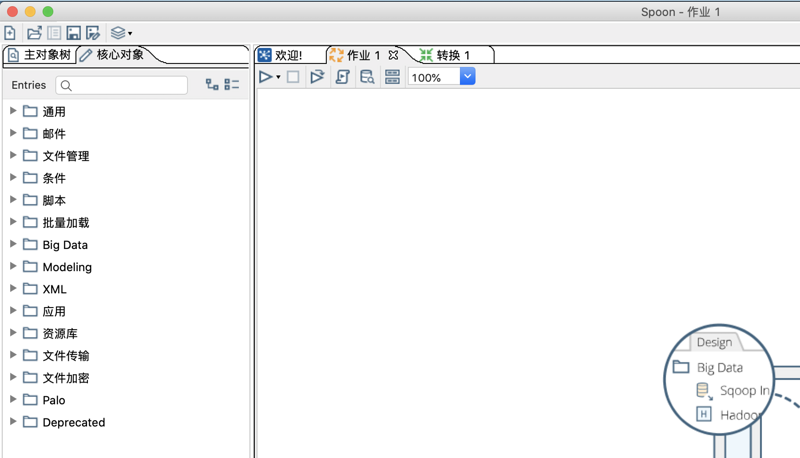
作业界面,左侧为作业项(Job Entry)
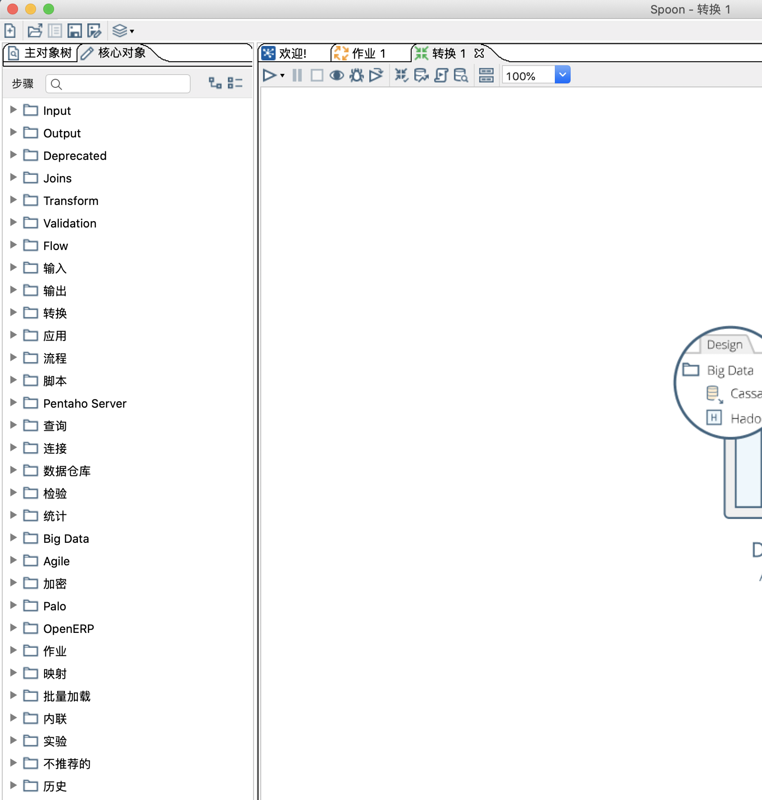
转换界面,左侧为转换步骤
Kettle insert 入库 Greenplum
因为数据处理的步骤都在转换里,所以演示暂时以转换为主。Kettle 连接 Greenplum 有几种方式,今天主要介绍 Insert 方式。我们会用到【转换–>输出–>表输出】和【转换–>输入–>文本文件输入】这2个步骤。
0、前置条件
首先我们需要准备好 Greenplum 数据库,这里假设大家已经安装完成并开放外部访问权限( pg_hba.conf )。
然后我们用下面的脚本初始化数据库表 T1。
[gpadmin1@centos-7 ~]$ psql
psql (9.4.24)
Type "help" for help.
postgres=# create table t1 (id int, name text);
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE
postgres=# insert into t1 values(1,'a'),(2,'b');
INSERT 0 2
postgres=#1、新建转换
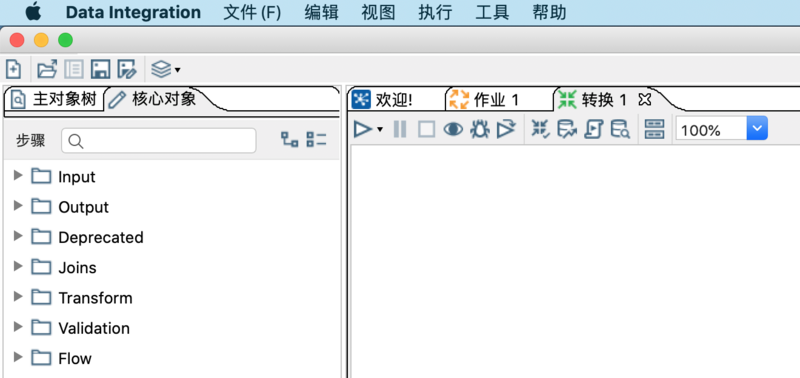
【文件】–>【新建】–>【转换】
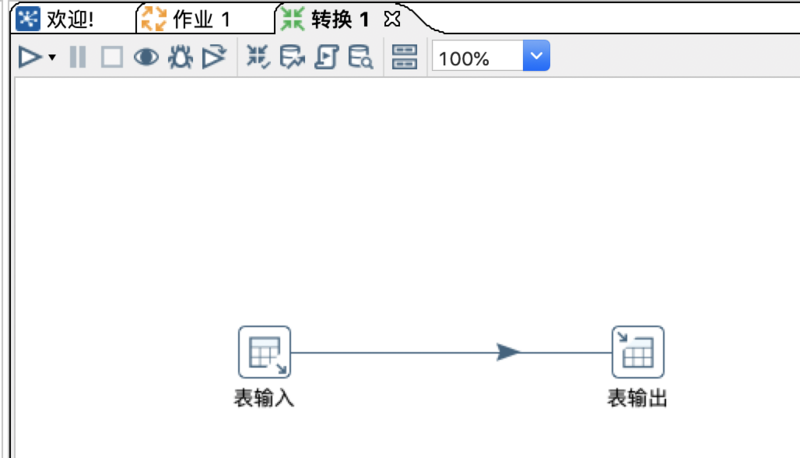
2、在转换中增加输入输出步骤
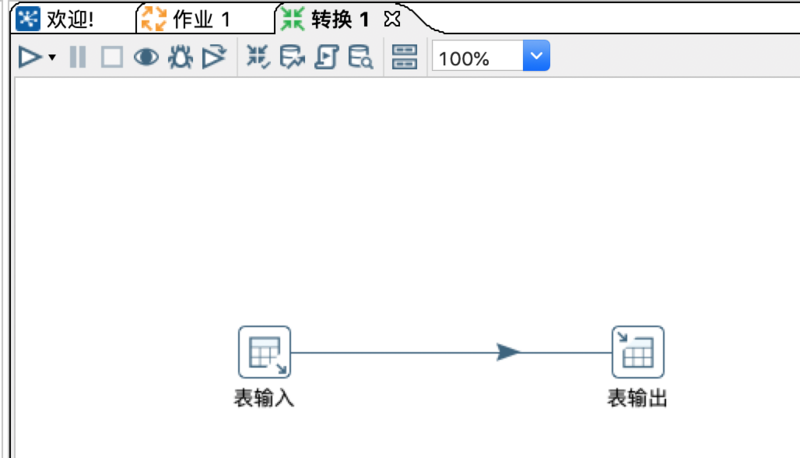
左侧步骤中打开【输入】–> 双击【表输入】或直接将其拖动到右侧设计幕布。
左侧步骤中打开【输出】–> 双击【表输出】或直接将其拖动到右侧设计幕布。
按住键盘shift键,点住鼠标左键,从【表输入】向【表输出】划线,形成数据流连接线。
3、连接 Greenplum 数据库表
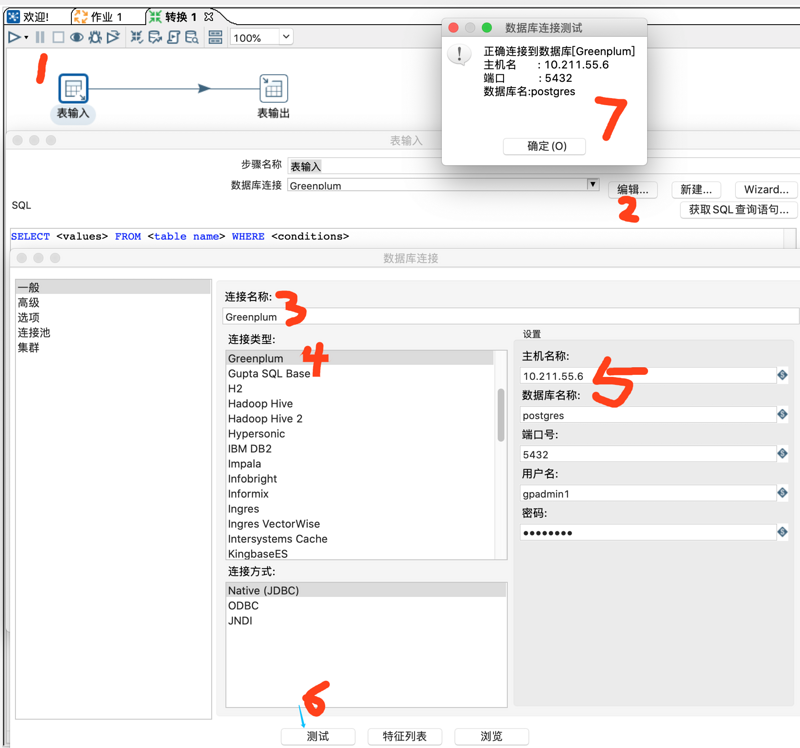
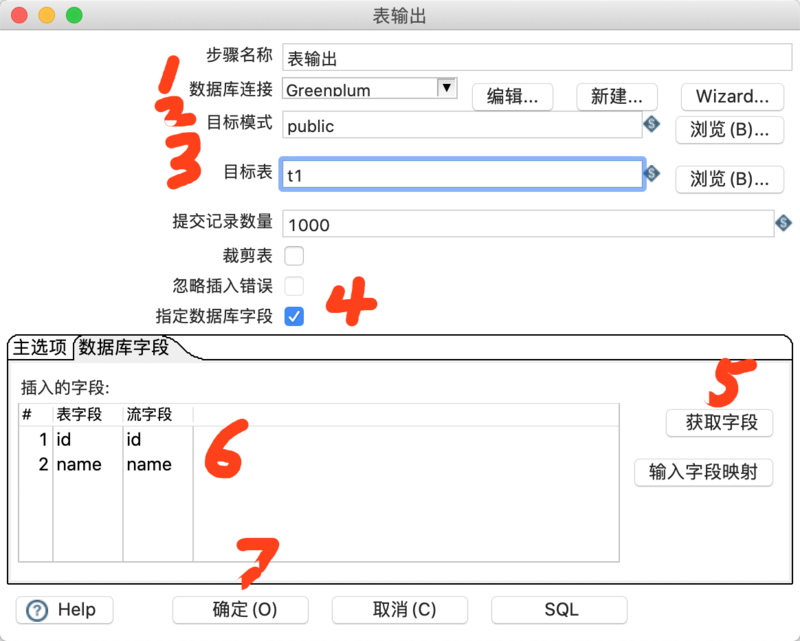
双击【表输入】,在弹出的属性配置对话框中点击【新建】数据库连接,根据下图序号配置Greenplum数据库连接。
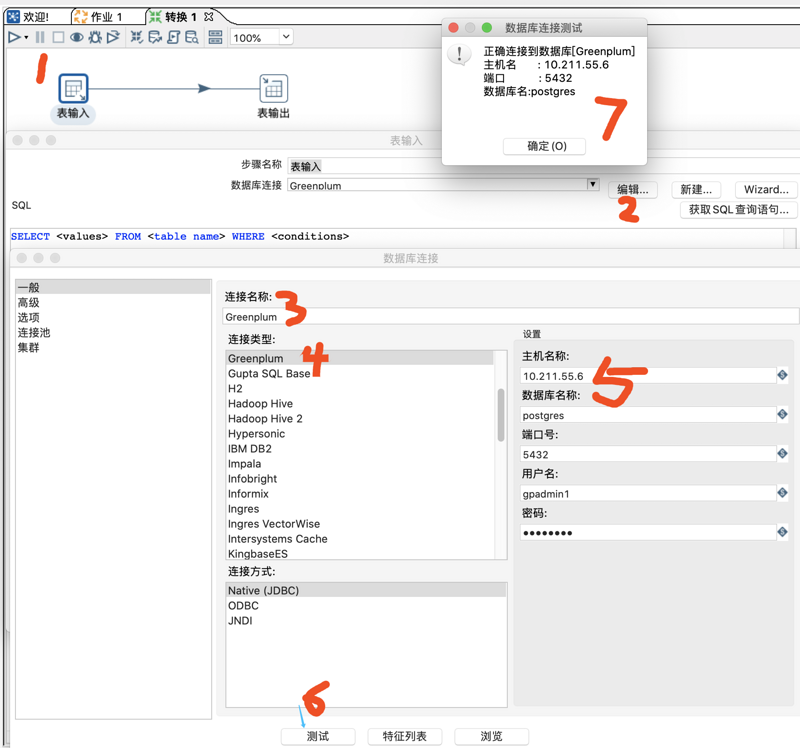
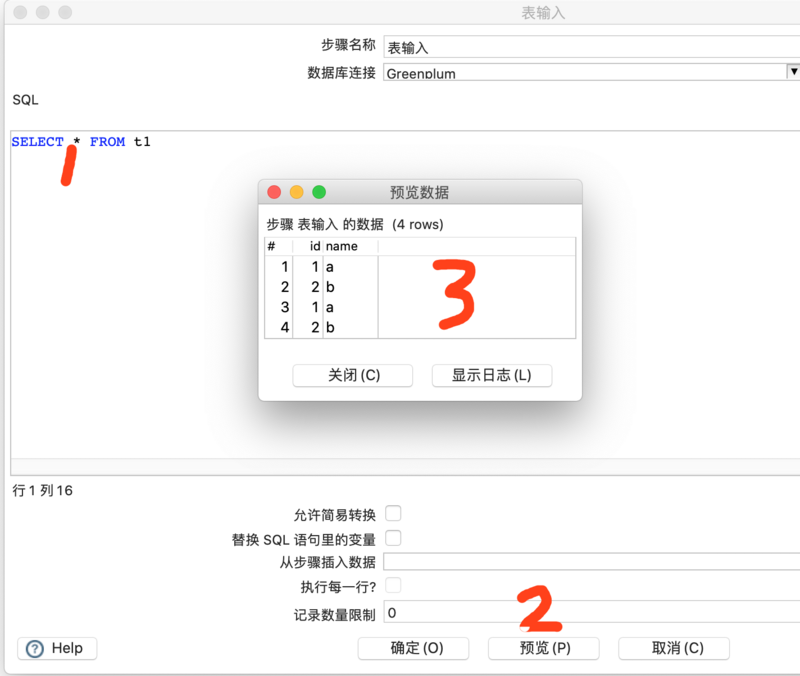
上图【确认】完成配置后,在【SQL】部分填写选取表数据的SQL,然后点击【预览】查看是否可以获取到数据。
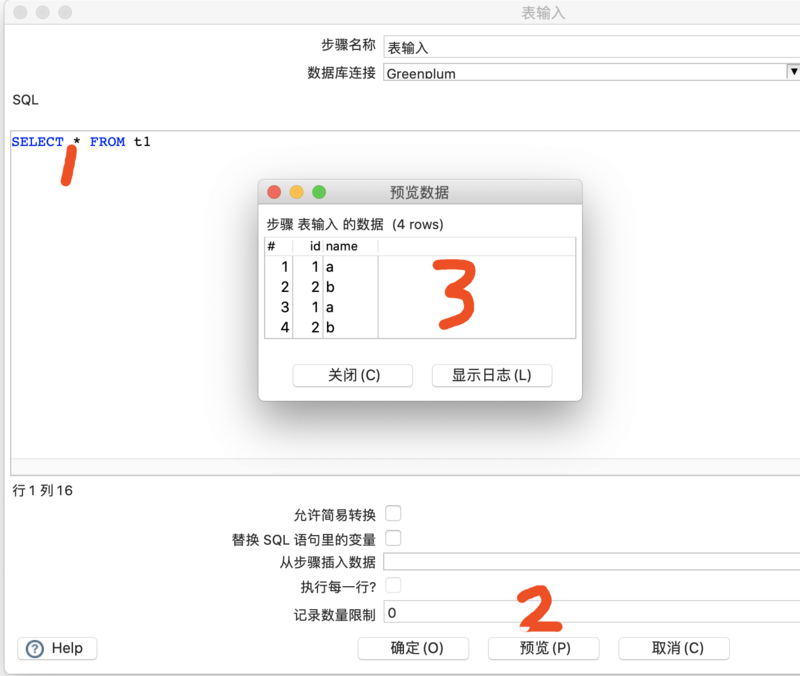
接下来按照类似的配置,选取数据库连接,并配置表及字段对应关系。
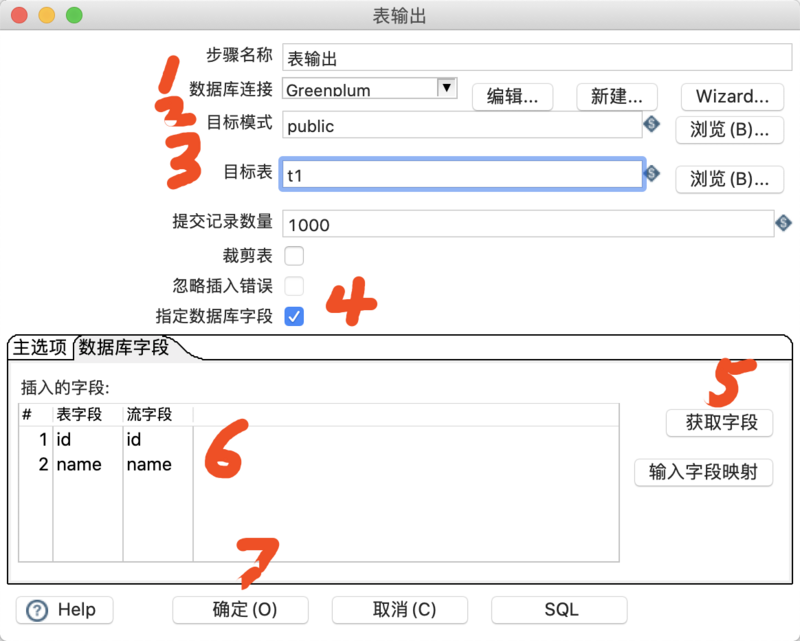
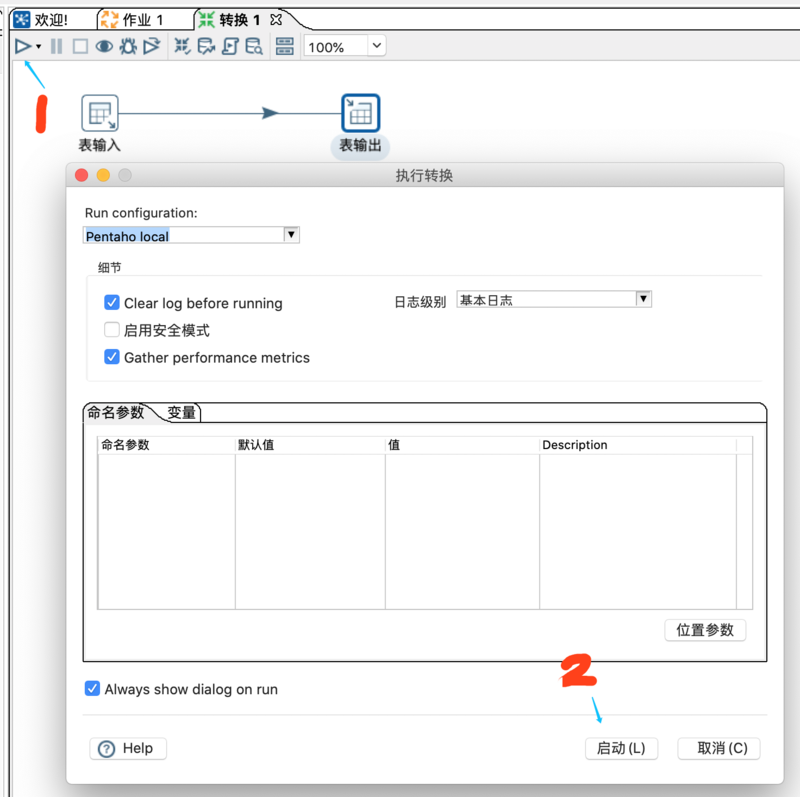
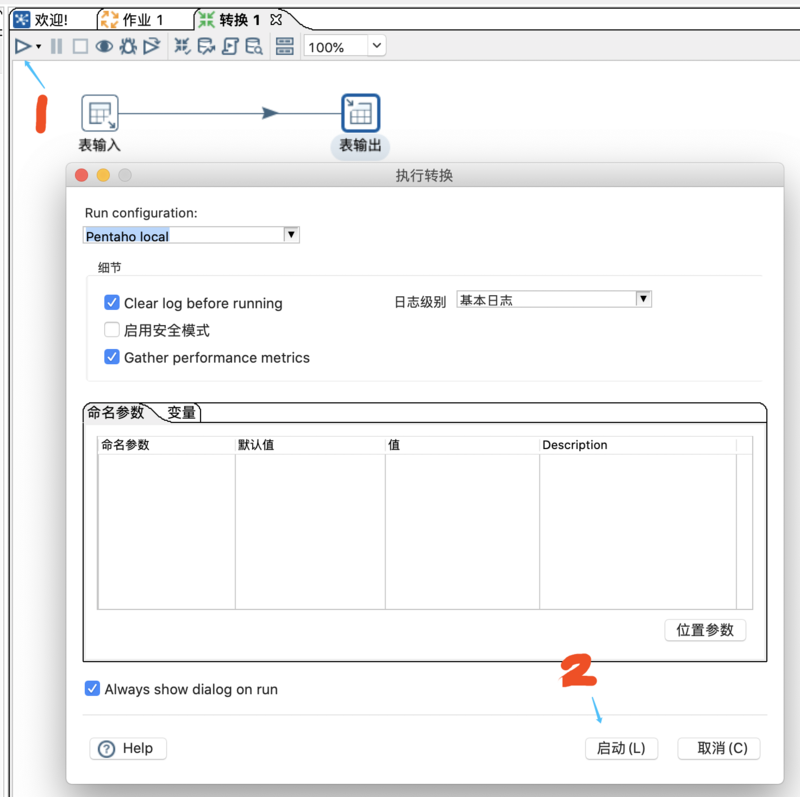
4、执行 Insert 入库
点击左上角的三角形运行按钮,执行【启动】,保存转换后执行,并查看执行结果。
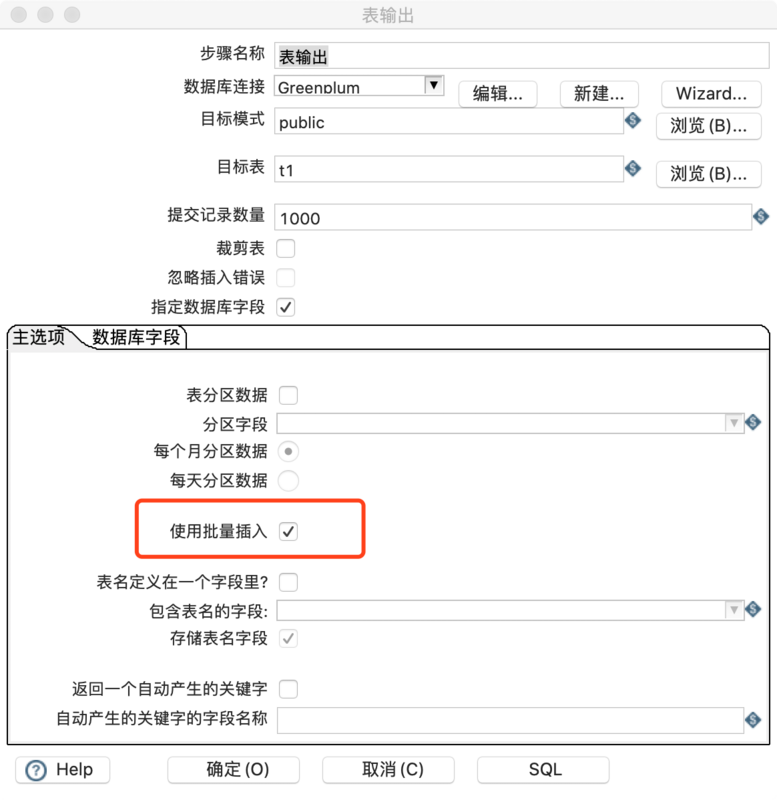
Kettle batch insert 入库 Greenplum
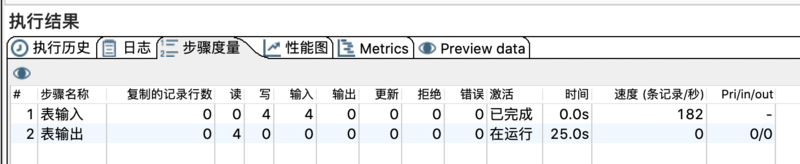
Kettle支持JDBC的batch insert方法,所以insert时可以采用批量插入的方式入库到Greenplum。整个处理的逻辑和之前介绍的insert入库基本一致,唯一区别的地方在于【使用批量插入】选项是否勾选,当然这个选项默认是勾选的。具体的步骤不详细展开了,放一张截图,大家有兴趣可以测一下2者的差别。
Kettle5: 入库之gpload
Kettle gpload 入库 Greenplum
因为数据处理的步骤都在转换里,所以演示暂时以转换为主。Kettle 连接 Greenplum 有几种方式,今天主要介绍 Insert 方式。我们会用到【转换–>输出–>表输出】和【转换–>输入–>文本文件输入】这2个步骤。
0、前置条件
首先我们需要准备好 Greenplum 数据库,这里假设大家已经安装完成并开放外部访问权限( pg_hba.conf )。
然后我们用下面的脚本初始化数据库表 T1。
[gpadmin1@centos-7 ~]$ psql
psql (9.4.24)
Type "help" for help.
postgres=# create table t1 (id int, name text);
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE
postgres=# insert into t1 values(1,'a'),(2,'b');
INSERT 0 2
postgres=#1、新建转换
【文件】–>【新建】–>【转换】
2、在转换中增加输入输出步骤
左侧步骤中打开【输入】–> 双击【表输入】或直接将其拖动到右侧设计幕布。
左侧步骤中打开【输出】–> 双击【表输出】或直接将其拖动到右侧设计幕布。
按住键盘shift键,点住鼠标左键,从【表输入】向【表输出】划线,形成数据流连接线。
3、连接 Greenplum 数据库表
双击【表输入】,在弹出的属性配置对话框中点击【新建】数据库连接,根据下图序号配置Greenplum数据库连接。
上图【确认】完成配置后,在【SQL】部分填写选取表数据的SQL,然后点击【预览】查看是否可以获取到数据。
接下来按照类似的配置,选取数据库连接,并配置表及字段对应关系。
4、执行 Insert 入库
点击左上角的三角形运行按钮,执行【启动】,保存转换后执行,并查看执行结果。