在上篇文章中,我们介绍了堆表上的Brin Index,包括Brin的优缺点、适用场景、Brin Scan、Brin Vacuum、Brin Storage等内容。本篇文章将为大家概述Brin在AppendOnly Table上的实现,并结合一些性能测试帮助的大家更好的理解Brin Index。
1、Brin在AppendOnly Table上的实现
对于包括Greenplum在内的擅长于OLAP场景的数据库,Update和Delete的应用场景较少,而sequential scan的场景非常多。堆表会存在两个问题,第一,由于堆表更擅长于update,它的每个block都不能装满;第二,堆表结构很难进行压缩,在同样数据量的情况下,堆表的占用空间很大。这两个缺点会导致在进行sequential scan的过程中,磁盘的IO非常大,因此堆表结构并不适合OLAP数据库。针对这种情况,Greenplum设计了一种紧凑的数据结构,即AppendOnly Table。
AppendOnly Table是一种紧凑的数据格式,适用于较少进行Update/Delete的场景。Tuple以紧凑的方式存储在变长的Block中,所以Block在写入磁盘后不能修改,只能向后追加新的Block,在实现并发Insert的过程中可能会出现冲突,为了实现并发Insert,每个AO表逻辑上有128个AoSeg,每个事务向一个特定的AoSeg追加数据,这就是AoTable的基本结构。
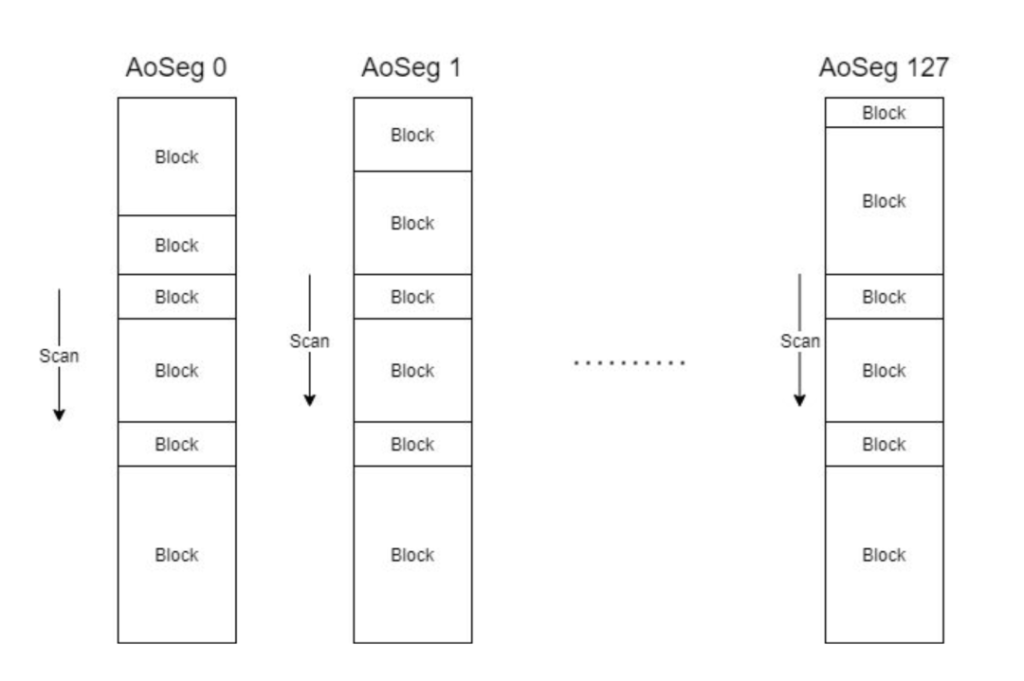
这种基本结构上在实现brin的过程中会遇到一些困难。AO表是一个变长的block,同时有128个AoSeg。在上篇文章中介绍brin的结构时,我们提到brin的前半部分是被称为Revmap的逻辑上的数组。它是一维的连续的结构,而AoTable是多个不连续的AoSeg,且里面的block不一样大,如何将brin的Revmap和AoSeg进行对应呢?
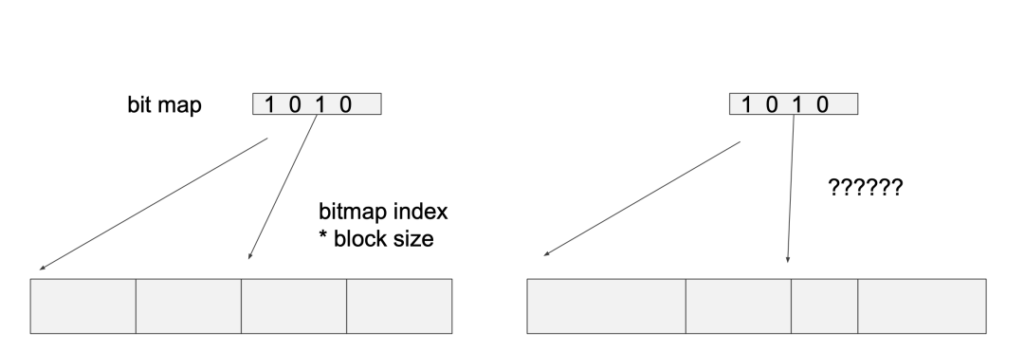
我们首先来看变长的block,这其实并不会构成问题。由于每个Ao Seg里都存在block number,虽然block是变长的block,但可以在逻辑上通过tuple ID进行对应。熟悉PostgreSQL的小伙伴都知道,tupleID是由两个部分组成,前面四字节是block number,后四个字节是block内部的偏移量。对于 AppendOnly Table,有了tupleID后,可以通过前四个字节分出逻辑上的block,从而block number可以和Revmap里数组的项一一对应起来。
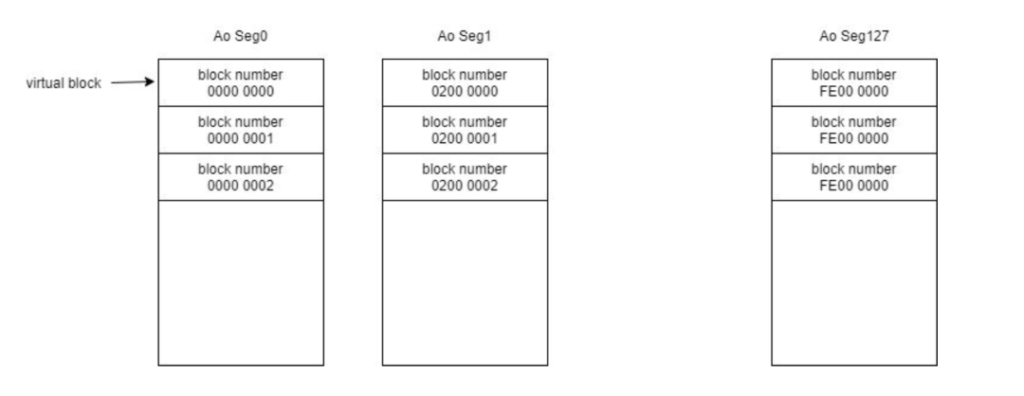
那么AoSeg的tupleID,或 tupleID对应的block number的取值范围是多少呢?由于tupleID是4个字节,因此它的取值范围天然是从0到2^32-1。如果是一个堆表,由于它的block都是连续的,所有的block number在整个取值范围只占据了开头的一段, 从而很容易和一个连续的结构进行对应。但AoTable则截然不同。它这128个AoSeg并不是集中的占用了某一小段的取值范围,而是均匀的分布在整个的取值范围之上。
如下图所示,第一个AoSeg的取值范围是从0开始,第二个AoSeg的取值范围则是从从2^32÷128的位置开始。最后一个AoSeg起始的block number是2^32/128*127开始的。也就是所有的 block number均匀的分散在整个的取值空间当中。如果我们用一个连续的物理结构和这样分散的block number去一一对应,中间就会出现很多的空洞。由于整体是一个数组,空洞也需要为它分配空间,这样的话,Revmap就会变得非常大:2^32*3。因此不管AoSeg内有多大的数据,只要最后一个AoSeg里有数据,就必须初始化一个24g大小的Revmap,这种做法是完全不能接受的,因此我们必须对这个结构进行一定的改进。
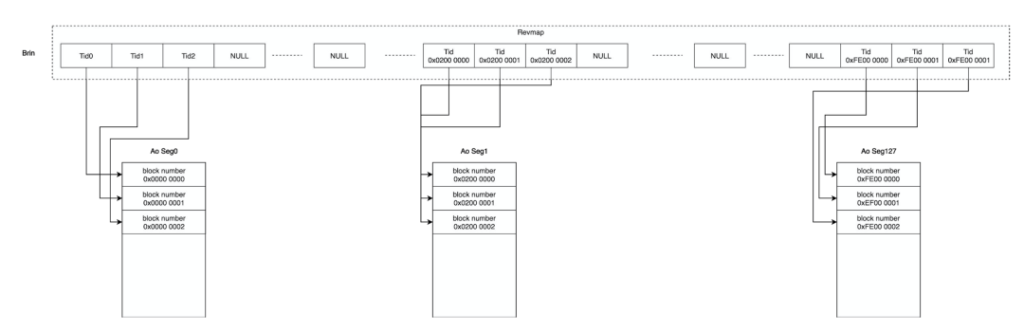
那么Greenplum的改进思路是什么呢?我们在Revmap这一层之上再加一个上层结构。因为 Revmap这一层是一个逻辑的数组,存放在一个block里。而上层结构存储的就是这个block里的block number。下层结构则可以变成按需分配的结构,即只有真正的数据对应的block number,才会给它分配空间。因为上层结构记录的是Revmap的block中的block number,就会有近5000倍的压缩比。
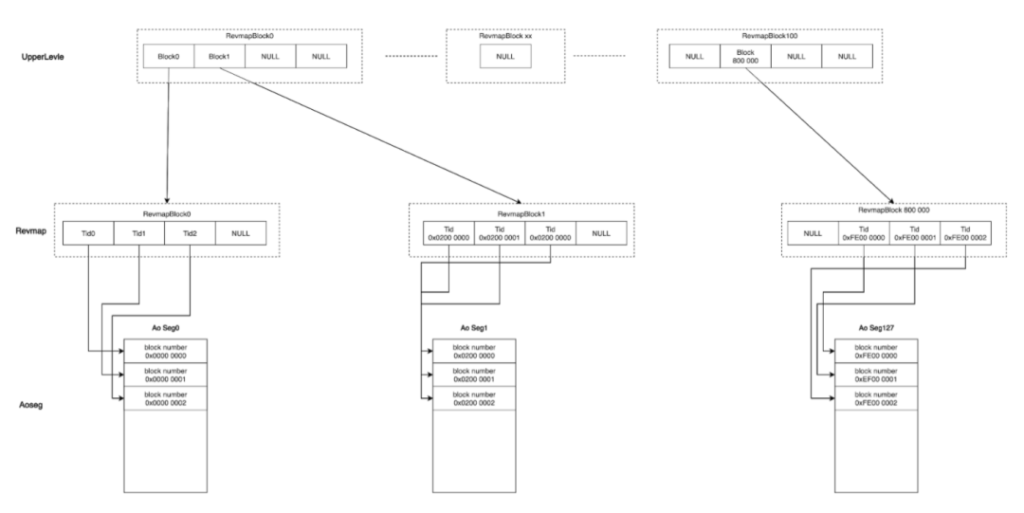
这样的话,虽然会有一些空洞,Revmap依然会非常小:
- Upper Level:定长数据段,约为3.2MB
- RevMap:变长数据段,大小随数据表数据量变化,向后增长
- BrinTuples:存放Min Max的数据段,Page结构和Heap Page相同

改进后,整个Brin Index的空间占用会回到一个合理的区间。在这种结构下,upper level_index和 revmap_offset可以根据以下几个公式进行计算:
- recordnumber = 2^32/TidNumPerPage
- upper_index=blocknum/TidNumPerPage
- revmap_offset=blocknum%TidNumPerPage
这样就可以得到一个在AoTable上,同时空间占用较合理的Brin Index。
2、性能测试
那么,这样的Brin Index会有怎样的的性能表现呢?我们进行一组测试来看一下。
这个测试非常的简单,
create table aocs(a int, b int) with(appendonly=true, ORIENTATION = column);insert into aocs select i,i from generate_series(1,10000000)i;create index abidx on ao using brin(b) with(pages_per_range=1);create index atidx on ao using btree(b);
我们先创建一个Ao表,这个表只有两列:a列和b列。接着在AO表里insert 1000万条数据,在某个字段上创建一个 brin Index,同时再创建一个b-tree index,进行性能上的对比。
首先进行一次等值的查询。
select gp_segment_id,* from ao where b=999999;得到的结果如下:
- seqscan: 3957.205 ms
- brin-bitmapscan: 36.456 ms
- btree-bitmapscan: 18.111 ms
从以上结果可以看出,使用index比不使用index结果有了质的飞跃,而brin要比btree慢一倍。
第二个测试,我们将条件的选择率升高。
select gp_segment_id,* from ao where b > 1000000 and b < 1010000;得到的结果如下:
- seqscan: 5757.855 ms
- brin-bitmapscan: 57.838 ms
- btree-bitmapscan: 42.250 ms
在选择率提高至千分之一。我们可以看到seqscan仍然是最慢的,虽然brin依旧比btree慢,但是差距已经缩小。
第三个测试中,我们继续将选择率进行提高。
select gp_segment_id,* from ao where b > 1000000 and b < 2000000;在百分之10的选择率下,得到的结果如下:
- seqscan: 6413.329 ms
- brin-bitmapscan: 2241.363 ms
- btree-bitmapscan: 2141.896 ms
此时,仍然是seqscan最慢,btree最快。但brin和btree的结果已较为接近。
再来看一下空间占用情况:
- ao: 180,198,032
- atidx-btree: 222,920,704
- abidx-brin: 6,553,600
从这三个测试可以看到,在数据具有较好的分布特性的前提下,brin index都有较好的性能。虽然brin index性能相对btree index性能较差,但brin index空间占用远小于bree index,这样的结果也是符合预期的。
这就是brin index的全部内容,如果大家对brin index有任何问题,欢迎在文章底部给我们留言!《Greenplum 7新版本大剧透》系列直播仍在进行中,欢迎大家的关注!

本文分享自微信公众号 – Greenplum中文社区(GreenplumCommunity)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
