2022年初,Greenplum 7版本将正式GA(具体时间和功能请以最终发布为准)。今年,Greenplum中文社区将和墨天轮社区合作,邀请原厂专家,开展《Greenplum 7 新版本大剧透》系列直播。第一讲(内核篇,组件篇)中,Greenplum原厂研发总监杨瑜介绍了Greenplum 7引入的多个激动人心的新特性和最新开发进展。第二讲中,Greenplum内核研发工程师陈金豹为大家详细解说了Brin Index在Greenplum 7中的理论与实现。本文涵盖了演讲所有精华内容,由于篇幅所限,文章分为两个部分,公众号将在下周推送第二部分,欢迎关注。
在系列直播的第二讲,我们为大家详细讲解Greenplum 7中Brin Index的理论与实现。熟悉PostgreSQL的同学应该了解,Brin Index是PostgreSQL 9.5版本中引入的一个新特性。由于Greenplum 6内核对应的PostgreSQL 9.4版本,因此6版本中并没有该特性。在Greenplum 7中,内核版本更新至PostgreSQL 12,Brin Index也会出现在新的版本。
Greenplum有两种存储,一种叫堆表(Heap Table),另一种叫追加表(AppendOnly Table)。堆表继承自PostgreSQL,因此在Greenplum 内核更新至PostgreSQL 9.5版本后,Greenplum的堆表就天然支持了Brin Index。由于Greenplum的追加表的存储结构和堆表差异很大,因此并不能天然支持Brin Index。
今天和大家介绍的内容分为如下四个部分,本文将着重介绍第一部分,剩下的内容将在下一篇文章讲解。
- Brin Index on Heap
- AppendOnly Table
- Brin在AppendOnly Table上的实现
- 性能测试
第一部分 堆表上的Brin
1. Block Range Index
Brin是Block Range Index的简写,顾名思义,索引记录的是存储数据块中的元组字段的最大值和最小值,用于过滤不符合条件的数据块。以下图为例,右边的堆表包含三个block,第一个block中有4个tuple,字段上的值分别是1、3、2、5。因此,与这个block相对应的Brin的元组就记录了 block的最小值1,最大值5。同理,7、8、8、10的最小值是7,最大值是10;9、11、11、12的最小值是9,最大值是12。这样就获得了一个 Brin。
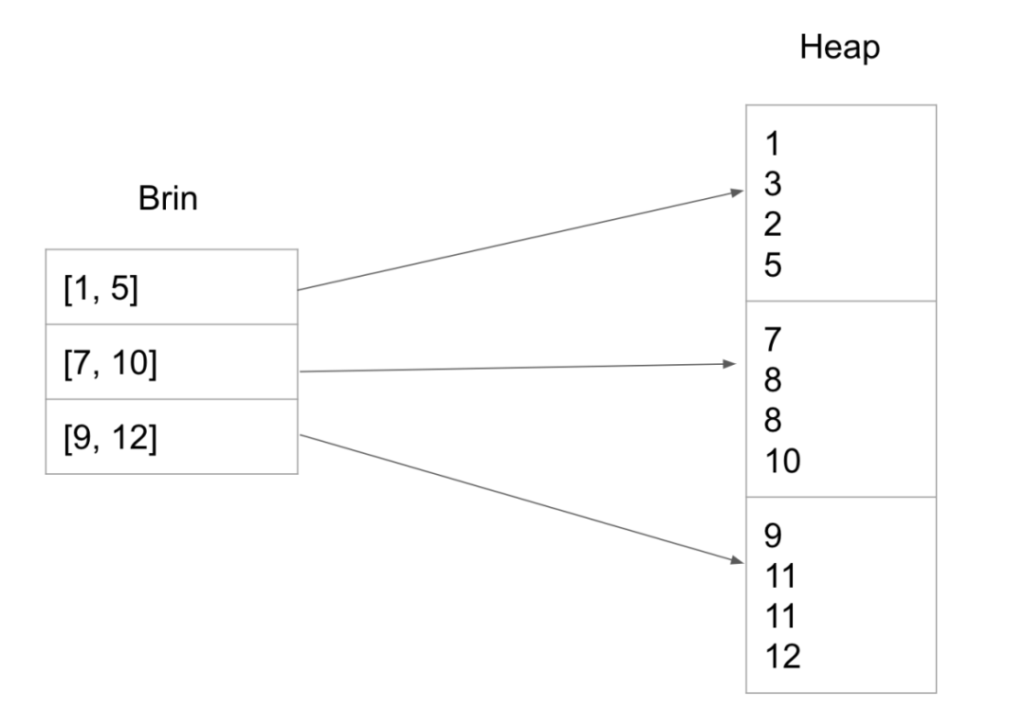
在执行带有条件的查询时,就可以利用Brin记录的这些信息,找到相应的block,同时滤掉大部分block,从而起到Index的作用。Brin Index是一种非常直观简单的Index。
2. Brin的优势和劣势
下面我们再来看一下Brin Index的优势和劣势。
- 优势
对于B-tree Index这样的密集索引,对应数据表的每一条数据,索引里也会存在一条数据,也就是说B-tree Index里的条目数目,大体上和数据表里的条目数是相当的。它的大小和数据表是一个量级的。但是Brin就完全不同了,数据表中的一个block或者一组block只会在Brin里生成一个条目,因此占用空间会非常小。
Brin的另一个优势是创建快。和B-tree Index一样,在创建brin的过程中,需要对表做一次完整的扫描。但是由于写需求很小,创建速度会快很多。
- 劣势
当然Brin Index也会有劣势。Brin Index只有在数据具有一定的分布特点时才有用。如果数据在索引字段上没有任何的分布特性,即它的空间分布和在索引字段上的值是没有任何关系,数据在空间上是完全随机分布的,这种情况下,Brin Index的效率会很低,因为能过滤掉的block将很少。
如果数据具有一定的分布特性,索引字段上的值和物理分布具有一定的关联,这种情况下,Brin的效率将很高。
3. Brin的体积
接下来我们具体分析一下Brin的体积,下图我们以PostgreSQL上默认的一个情况来举例。
在PostgreSQL中,默认情况下,每20个heap block生成一个Brin的元组。
这样的情况下,对于一个有 6~7列的不大不小的表,我们认为Brin Tuple有20个bytes左右的大小。此时Brin的体积情况如下,
- Brin Tuple:20bytes
- Block Range:8K*20=160K
- Brin比Heap小8000倍
- 1TB的Heap表只需要125M的Brin
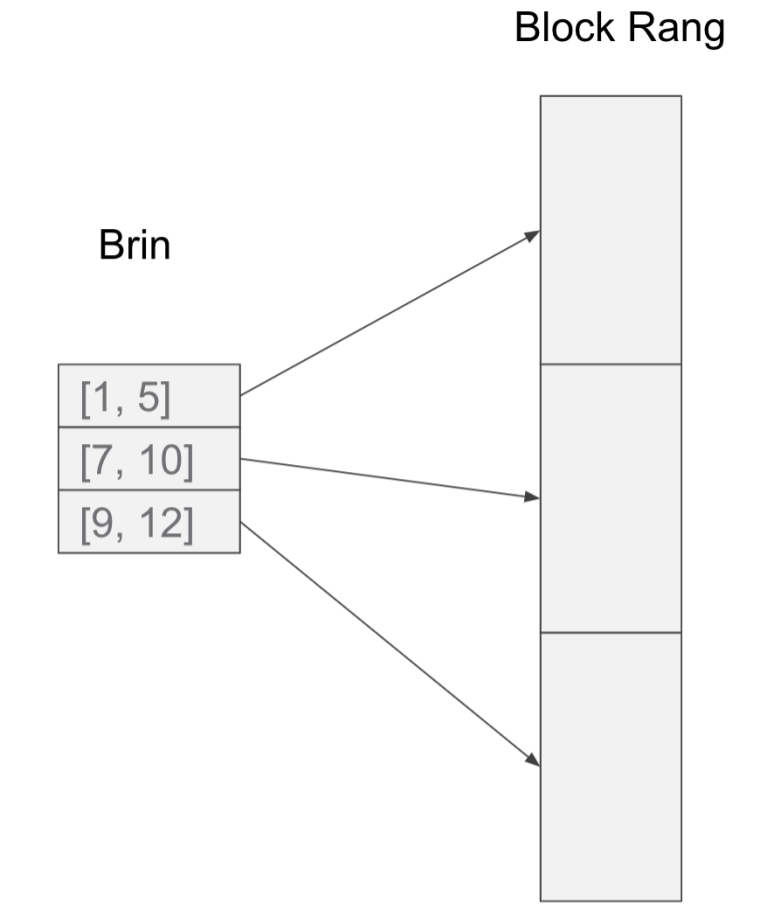
从这些数据大家可以看出,Brin Index的体积非常小,比B-tree Index具有数量级上的优势。
4. Brin的选择率
前文在介绍Brin Index劣势时,我们提到Brin Index只有在数据具有一定的分布特点时才有用。下面,我们将建立一个粗略的模型为大家定性的分析一下这个问题。
我们假设存在一个表,表内有100万条数据,100万条数据分布在1000个block里,即每一个block有1000条数据。
此时有一条查询,查询的内容是什么不重要,重要的是查询它的查询条件的选择率是1%,也就是说查询条件会命中1%的Tuple。由于Brin Index是一个以块为单位的,Brin Index的作用就是将不符合查询条件的block过滤掉。
在例子中具体情况如下:
- BlockNum: B = 1000
- TupleNum: N = 1000000
- TuplePerblock: M = 1000
- Selection: a = 1%
我们可以将该例子等效成一个球的概率的问题:假设有一百万个球,其中1%也就是1万个是黑球,99万个是白球。我们把这100万个球随机放进这1000个盒子中,即数据是随机的。那么会存在多少盒子,里面全是黑球,一个白球都没有呢?
这个概率题可以通过下面的公式算出:
Brin Selection: 1-((B-1)/B)^(N*a) = 1- 0.000045
最终的结论是盒子里只有白球,没有一个黑球的概率是0.00045,即万分之0.45。
也就是说如果数据是完全随机分布的,即它的物理位置和字段的值是任何关系的情况下,在选择率只有1%的条件下,只能filter掉万分之0.45的数据,剩下的数据仍然需要扫描,此时,Brin Index就没有存在的意义了。这就是为什么Brin Index最大的缺点就是只有在数据具有一定分布特点时才有用,如果数据是完全随机分布的,Brin Index是没有用的。
因此,Brin Index的适用性并没有Heap Index那么好,数据管理员在使用中需要自行判断数据分布是否具有一定的分布特性,来决定是否需要使用Brin Index。
5. Brin 的适用场景
通过Brin的优势和劣势的分析,我们可以总结出Brin Index的适用场景如下:
- 表非常大
- 数据有一定的分布特性
- 用户不想在Index上付出太多存储空间
在这样的使用场景下,Brin Index将是一种很好的选择。在包括Greenplum在内的OLAP数据库中,表非常大,同时用户不想在Index上付出太多存储空间,这种场景是非常常见的。在大部分OLAP数据库中,由于数据量非常大,OLAP的查询又非常复杂,这种情况下,建立索引会占用大量的空间,用户几乎不可能接受这样存储空间的付出。因此,很多 OLAP的数据库用户并不倾向于建立索引。而如果数据分布具有一定特性,Brin就是非常适合OLAP数据库场景建立的索引。
6. Brin Scan
下面我们来探讨一下Brin在PostgreSQL中,或者Greenplum的堆表中,到底是如何起作用的。
Brin里记录了每个 block的最大值和最小值。大家可能都了解,PostgreSQL有三种 scan的类型。如果没有索引的话,它只能进行sequential scan,即全表顺序扫描。如果有Index就可以进行Index Scan,即从Index里查询,Index里记录了所有字段的值,同时记录了指向数据元组的 Tuple ID。如果从Index里查到一个Tuple ID,就可以从表中拉出一条数据,这就是Index Scan。
PostgreSQL提供的第三种Scan的方式叫Bitmap Index Scan。即从索引里查到Tuple ID后,不马上去通过Tuple ID取出Tuple,而是用这个Tuple ID建立一个 bitmap,bitmap的每一位就代表了Tuple在存储中的一个位置。查询结束后,就建立起了一整套的bitmap,接着通过bitmap再去存储内处理和查询,这就叫Bitmap Index Scan。Bitmap Index相对于Index Scan的劣势在于,它必须建立一个 bitmap, 而 bitmap会产生一些代价。但Bitmap Index的好处在于它把对于数据存储的随机读取变成了顺序读取,在数据量比较大的时候具有一定优势。
如果每次Bitmap Index Scan都建立一个无损的bitmap,bitmap可能非常大。而bitmap是一个内存中的数据结构,如果太大将导致内存不够用,因此bitmap是可以压缩的,压缩的方式也十分简单。当一个block被命中的Tuple比较多时,就可以直接用一个bit来代表整个block,从而把 bitmap压缩到很小。而由于Brin Index索引的单位是Block或一组Block,输出的Bitmap天然是压缩到最小的情况,因此Brin Index其实可以被看作是最极端压缩的情况。
例如下面的例子中,得到的bitmap 就是1、1、0、0。该bitmap起到了索引应有的作用,4个block中过滤了2个block,因此只需要扫描2个block的数据。Brin Scan生成bitmap以后,就可以完全复用bitmap index scan的代码了。
select * from t where a > 1 and a < 8;

7. Index Update Delete
在讲完Brin是如何被建立出来、在Index Scan中是如何起作用之后,我们来看一下Brin Index在Insert、Update、Delete中是如何起作用的。Brin在维护更新的逻辑较为简单。由于每个元组代表一组Block索引字段的最大、最小值,如果Insert或者Update新的数据超出了最大、最小值的范围,则更新元组;如果落在Brin的范围区间内,则不需要进行任何操作;
而Delete预期范围是缩小的,但很难有方式来知晓是否真的缩小,例如范围是1~5,删除4,范围没有缩小;但如果删除值为5的Tuple,由于可能存在很多个Tuple值均为5,很难知晓是否范围缩小了。因此在Delete的时候,不需要做任何操作。
随着Insert、Update的操作的执行,Brin的范围会慢慢变大,因此在整个更新的过程中可能会损失一些性能。但是由于brin index本身就是一个不追求精确的Index,在索引和Bitmap Index Scan之后,还要用查询条件进行过滤,因此不会产生错误结果。
8. Brin Vacuum
由于Greenplum采用的是MVCC的更新模式,在更新的过程中会产生很多“垃圾”,而vacuum就是清理“垃圾”的操作。对于普通的vacuum,由于不需要做block之间的数据挪动,只是在Block内部清理一些“垃圾”,并且挪动一些Tuple,但仅限于Block内部的挪动。因此vacuum不需要做任何操作。
Vacuum full由于过程中需要做block之间的数据挪动,因此需要重建索引。
9. Brin Storage
下面我们来看一下Brin的存储情况。
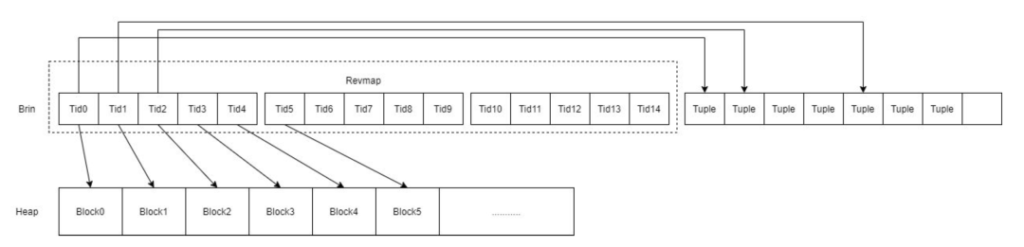
Heap表中,block之间的存储结构是非常简单的,是由一个个连续的文件,里面存储连续的block。因此Brin的前半部分是一个数组结构,数组的下标对应着block number。数组的value是Tuple ID,指向存储有最大最小值的Tuple。
这就是第一部分堆表上的Brin Index的全部内容,下一篇文章我们将介绍AppendOnly Table、Brin在AppendOnly Table上的实现以及性能测试,欢迎关注!

