作者:张桓,Greenplum内核研发
排序在数据库执行器中扮演了重要的角色,除了显示的ORDER BY语句,数据库的聚集、窗口函数中都存在排序算法的身影。内核系列的第六篇文章,我将从4个方面来为大家讲解一下Greenplum排序算法。
- 内排序算法
- 外排序算法
- Greenplum排序的底层模块—— TupleSort
- 排序在Greenplum中的应用
一、内排序算法
相信很多数据库从业者都对很多内排序算法耳熟能详,比如冒泡排序、插入排序、快速排序、堆排序、基数排序等。Greenplum使用的是快速排序和堆排序,为什么会使用两种排序算法呢?
Greenplum在快速排序之外还使用了堆排序主要是面向需要使用topK查询的一些使用场景。例如sql语句中的order by后跟了一个limit的语句,我们就可以切换到TopK查询,对于Top k查询,堆排序的性能会更好。因此Greenplum支持两种内排序算法。
1、快速排序
快速排序是最常用的排序算法,由Tony Hoare在1959年发明。顾名思义,快速排序的特点就是“快”。我们来看一下它是如何实现快速的。
快速排序算法(简称快排)分为三个步骤:
- 步骤1:挑选基准值;从数列中挑选出一个基准元素,称为pivot
- 步骤2:分割;重新排序数组,所有比基准元素小的元素排放到基准元素之前;所有比基准元素大的元素排放到基准元素之后。分割完成后,我们完成了对基准元素的排序,即基准元素在数组中的位置不再改变
- 步骤3:递归排序子序列;递归地将小于基准元素的子序列和大于基准元素的子序列分别进行排序
快速排序算法每次选取一个基准元素,将比基准元素小的排到基准元素左边,比基准元素大的排到基准元素的右边,从而将待排序数组分成两个子集。下面通过一个例子来展示一下快排的过程。
首先选取一个pivot的元素,假设通过随机选取后,选取的元素是6,我们将所有比6大的元素8、7、7、9排到6之前,所有比6小元素3、2、1都排在6之后,再分别对蓝色和橘色这两个子序列,递归的调用快排算法。
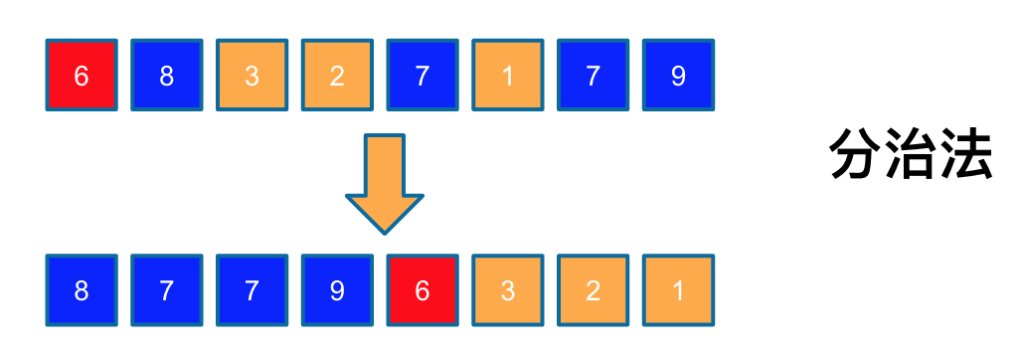
大家可以看到其实快排本质的核心思想是一个“分而治之”的策略。下面是快排的一个伪代码。作为一个递归的算法,代码有两个部分:
- 第一个部分是递归的终止条件:当排序只剩下一个元素的时候,递归终止。
- 第二部分是把问题划分成若干子问题。即前文提到的选取基准元素,划分子序列,在子序列上分而治之。递归调用QuickSort算法的过程。

2. 堆排序
Greenplum在排序中对于topk使用的是堆排序。堆排序是最常用的排序算法,由J.Williams在1964年发明。
理解堆排序,首先我们需要理解什么是堆。堆是一种近似完全二叉树的结构,最大值堆要求每个子节点的键值总是小于父节点。最小值堆相反,要求每个子节点的键值总是大于父节点。
堆排序算法的实际过程分成三步:
- 步骤1:建立最大值堆,最大元素在堆顶
- 步骤2:重复将堆顶元组移除并插入到排序数组,更新堆使其保持堆的性质
- 步骤3:当堆的元素个数为零时,数组排序完毕
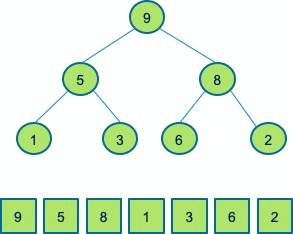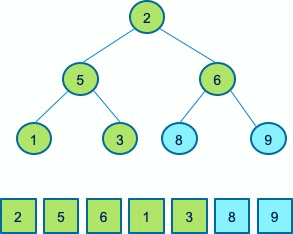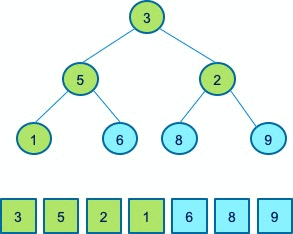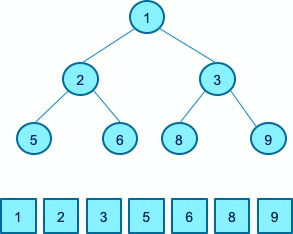
下面同样通过一个例子来帮助大家理解堆排序。待排序数组是下图中的数组9、5、8、1、3、6、2。首先,我们建立了这样一个堆,保证每一个父节点大于子节点。
接着我们进行排序,首先移除堆顶元素9,和最后一个元素2进行交换,9就排序好了,而2已经不满足堆的性质,因此我们需要做一个操作,让其满足堆的性质,即将其和8、6进行交换。接着迭代的进行排序,把此时的堆顶元素8移除,和2进行交换。为了让新的数组满足堆的性质,再将2和6进行交换。接着再把堆顶元素6弹出来,重新交换3和5,保持堆的性质….
这样一系列的操作后,最终只剩下一个堆顶元素,最后把堆顶元素弹出,即完成了对原始数组的一个排序,这就是堆排序的完整的过程。
堆排序的算法可以分解成两大阶段,
- 第一阶段是建堆
- 第二阶段是不断弹出带占比元素,并维持对应的性质保持不变,直到大小为0。

二、外排序算法
前面我们介绍了Greenplum排序所使用的快速排序以及堆排序两个算法。这两个算法主要是用来处理海量数据,对海量数据进行排序时,不可避免会出现内存无法容纳下的情况,此时我们就需要使用外排序算法。
外排序一般是基于归并排序,什么是归并排序呢?
归并排序分为两个阶段:
- 阶段一是分割阶段,将原始待排序数据分成若干个顺串;
- 阶段二是合并阶段,将所有小顺串合并成一个包含所有数据的大顺串;
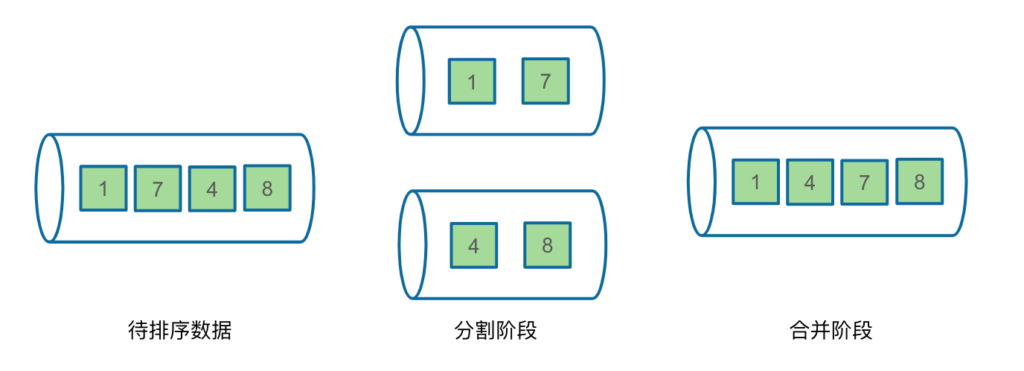
归并的过程就是分割加合并,分割合并两个阶段很简单,但如何更快的实现一个归并排序,就会涉及到一系列问题,主要包括三个问题:
问题一:有没有办法在分割阶段就生成大于内存大小的顺串呢?
分割阶段只需要顺序扫描一次外存,最简单的策略是读取外存数据,加载到内存,当内存用满时,执行快速排序等内排序算法,生成一个顺串。之后清空内存,继续读取外存数据,如此反复,直到所有外存数据处理完毕。该算法生成的每一个顺串的大小都不会超过内存的大小,而顺 串越小,合并阶段的代价就越高,需要读取外存的次数也越多,有没有办法在分割阶段就生成大于内存大小的顺串呢?
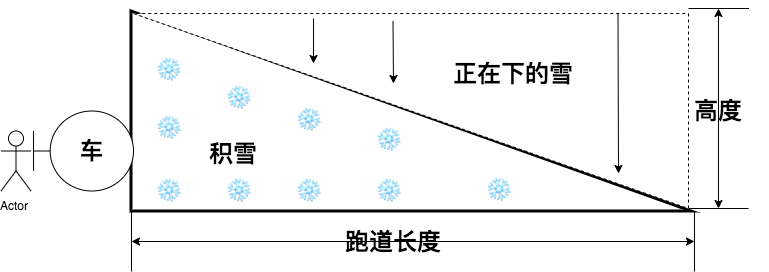
针对这个问题,Greenplum使用的替换选择算法,这个算法借鉴的是扫雪机模型。如上图所示,在环形跑道上有一台扫雪机在不断扫雪,扫雪机启动时前面的积雪高度为h。扫雪机不断向前开,新下的雪一部分落在了扫雪机的前方,一部分落在了扫雪机的后方。假设扫雪机扫雪的速度和雪下的速度一致,即扫雪机转了一圈之后,扫雪机前面雪的高度仍然为h。当扫了一圈之后就达到了一个动态的平衡,即扫雪机正前方的雪高度为h,正后方的雪高度为0,中间的雪量是一个从h到0如图1所示的斜坡。我们可以很容易算出任意时刻的路面积雪量就是图1中直角三角形的面积。但是由于扫雪机面前的雪的高度永远为h,扫雪机转了一圈,铲雪总量是跑道的长度*高度h,是路面积雪量的两倍。
类比扫雪机模型,跑道上的积雪就是替换选择算法使用的堆,积雪的量就是内存的大小。输出当前最小值,生成顺串的过程就是铲雪的过程。顺串的大小就是铲雪量。新落下的雪就是新的输入数据,由于输入随机,如果输入大于等于刚输出的元素,则被加入到堆中,即被扫雪车清除。如果输入小于刚输出的元素,则相当于新雪下在了扫雪车的后方,本次铲雪(顺串)不包含该元素。因此,顺串的长度就是铲雪量,也就是内存大小(跑道上的积雪)的两倍。
这个就是计算机超级大牛Knuth在自己的书《计算机程序艺术》中提到的5.4.1R替换选择算法,它是这么工作的:
- 初始化阶段,读取输入元组至内存,并建立最小堆。
- 弹出堆顶元组,输出到顺串文件的缓冲区,并记录该元组的排序键为lastkey。
- 读取新元组,如果元组排序键大于等于lastkey,插入堆顶,并调整堆,使其有序。
- 如果新元组排序键小于lastkey,将该元组放入堆尾,并将堆的大小减1。
- 重复第2步,直至堆大小变为0。
- 顺串生成完毕。将堆大小重置为N,并重新建堆。重复第2步,开始生成下一个顺串。
问题二:合并阶段假设存在N个输入缓冲区,如何高效的比较N个输入缓冲区的最小值,并输出到输出缓冲区?
假设顺串(长度为L)分布在K个文件中,顺串合并时需要K个输入缓冲区和1个输出缓冲区,每次选取K个缓冲区的最小值,输出到输出缓冲区。最后,输出缓冲区输出的顺串长度为L*K。因此算法复杂度 O(K* (L*K))。
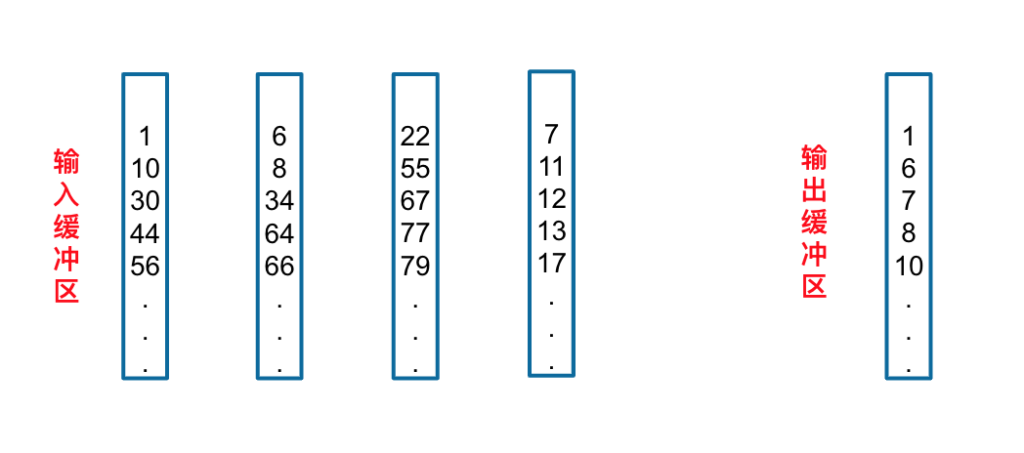
如何才能降低这么高的复杂度呢?接下来就为大家介绍败者树算法,败者树算法和堆比较类似,Greenplum目前使用的是堆来加速从N个元素中选最小的元素的方式,在这一块还在继续探索中。
- 输入每个顺串的第一个记录作为败者树的叶子节点。建立初始化败者树。
- 两两相比较,父亲节点存储了两个节点比较的败者(节点较大的值);胜利者(较小者)可以参与更高层的比赛。这样树的顶端就是当次比较的冠军(最小者)。
- 调整败者树,当我们把最小者输入到输出文件以后,需要从相应的顺串取出一个记录补上去。补回来的时候,我们就需要调整败者树,我们只需要沿着当前节点的父亲节点一直比较到顶端。比较的规则是与父亲节点比较,胜者可以参与更高层的比较,一直向上,直到根节点。失败者留在当前节点。
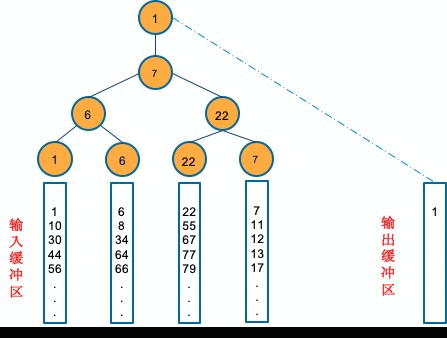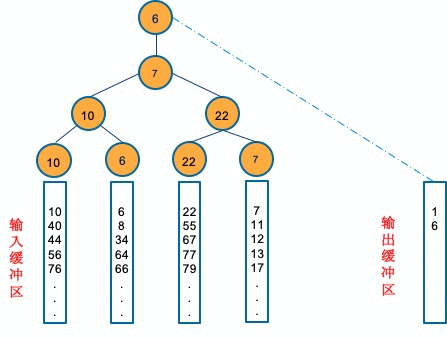
同样,我们通过下面这个例子来看一下败者树是如何工作的。下图中四个顺串的第一个元素分别是1、6、22和7。败者树记录每次比赛的失败者,但是获胜者晋级,即1和6比赛,6是失败者,记录在父节点,1成功晋级,并与右边的晋级者7进行比赛,新的失败者7被记录在父节点,1晋级。达到根节点后,将1放到输出缓冲区。
接着,读取顺序串1的第二个元素10,先让10和6进行比赛,失败者10就作为父节点,6则成功的晋级,6再与7进行比赛,6再次获胜,这时候6就为了根节点。此时在10、6、22、7里,6是最小的元素,我们就可以把6输出到输出缓冲区。
败者树对每一个新读读入的元组进行比较的时候,它的复杂度是树的高度,也就是 log(k)。
问题三:合并阶段,如何减少合并顺串过程中磁盘的读取的顺串数量。
败者树解决的是在合并阶段,如何快速从n个元素中选取最小值。合并阶段还有另外一个问题,如何减少合并顺畅过程中磁盘读取的顺串的数量?也就是说如何减少总的IO。
传统的标准算法是多路归并排序。我们先来了解一下什么是两路归并排序。
两度归并排序使用两个输入缓冲区,对应的两个输入文件和两个输出文件,并从输入缓冲区存储到输出缓冲区。下次归并,输入缓冲区与输出缓冲区位置调换。每次归并的时候,顺串的长度会翻倍,并且从输入缓冲区把顺串归并后的长度为两倍的顺序串存存储到输出缓存区。
- 假使初始顺串的长度为L,个数为N,每次迭代磁盘读取的数据量为L*N。迭代次数Log2(N)。
- 算法磁盘访问复杂度为L*N*Log2(N)。
- K路归并排序是对两路归并排序的扩展,其需要K个输入文件和K各输出文件。
下面我们用一个例子来数一数两路归并排序发生了多少次IO。两路归并排序需要使用4个文件分别作为输入(文件1和文件2)和输出文件(文件3和文件4)来存储顺串,两路归并排序需要文件中的顺串数呈现均匀的分布
| 文件1 | 文件2 | 文件3 | 文件4 |
| 32 | 32 | 0 | 0 |
| 0 | 0 | 16(2) | 16(2) |
| 8(4) | 8(4) | 0 | 0 |
| 0 | 0 | 4(8) | 4(8) |
| 2(16) | 2(16) | 0 | 0 |
| 0 | 0 | 1(32) | 1(32) |
| 1(64) | 0 | 0 | 0 |
第一次归并时,我们将顺串数除以2,每个顺串长度翻倍,因此文件3、文件4通过归并得到了16个顺串,每个顺串的长度是基础顺串的两倍。
第二次归并是以文件3、文件4为输入文件,归并后的结果是每个文件有8个顺串,每个顺串长度是基础顺串的4倍,这样不断的去应用归并算法。到第6次迭代的时候,文件3和文件4都只有一个顺串,且这个顺串是基础分开的32倍。我们再对文件3号、文件4这两个顺串进行一次归并,就可以得到一个顺串,且包含了全部的数据。
IO的次数是64 * 6 = 384 个基础顺串:每个顺串平均6次移动。那么有没有什么更好的办法呢?
Knuth提出了多项规定排除算法来解决这一问题。多项规定排斥算法为什么可以得到更少的顺串平均移动次数呢?我们首先看一下什么是多相归并算法。
Knuth 5.4.2D多相归并排序算法
- 初始化阶段,N+1个缓冲区,其中N个为输入缓冲区和1个为输出缓冲区。其中,每一个输入缓冲区包含若干个顺串,缓冲区顺串个数服从斐波纳切分布。
- 从每个输入缓冲区选取开头的顺串,组成N个顺串(可以存在空顺串)。对N个顺串进行归并排序,排序结果写入输出缓冲区的顺串。此时每个输入缓冲区的顺串数减1,输出缓冲区顺串数加1。
- 如果任何一个输入缓冲区的顺串数都大于0,重复第2步。
- 如果所有缓冲区的顺串数和大于1,选取顺串数为0的输入缓冲区作为新的输出缓冲区,将原输出缓冲区设置为新的输入缓冲区,重复第2步。
- 如果所有缓冲区的顺串数和为1,则该顺串就是排好序的元组,算法结束。
通过一个例子来帮助大家理解:
| 文件1 | 文件2 | 文件3 | 文件4 |
| 24 | 20 | 13 | 0 |
| 11 | 7 | 0 | 13(3) |
| 4 | 0 | 7(5) | 6(3) |
| 0 | 4(9) | 3(5) | 2(3) |
| 2(17) | 2(9) | 1(5) | 0 |
| 1(17) | 1(9) | 0 | 1(31) |
| 0 | 0 | 1(57) | 0 |
初始状态有三个输入文件,一个输出文件,3个输入文件的分布不是均匀的,分别有24个顺串,20个顺串,13个顺串。每个顺串的大小是一样的。
那么第一步合并的过程是先合并13个顺串,让文件3的顺串数变为0,此时输出文件4一共得到13个归并后的顺串,且每个顺串大小是基础顺串的三倍。文件1和文件2还剩下11个和7个没有被扫描过的顺串,基础长度是1。
第二次合并的过程中,我们会选取11、7、13中的最小值7,我们会合并7个顺串。此时文件1中还有4个没有被扫描过的顺串,文件2变为0,文件3作为输出,得到了7个合并后的顺串。
文件3中的每个顺串长度为5个基础顺串。文件4长度为三倍基础顺差的顺串。再往后合并的时候,会选择4进行一次归并…迭代下去,直到第6次,文件1、文件2和文件4作为输入文件,每个文件只有一个顺串,但每个顺串的大小已经不一样了,文件1中的这一个顺串的大小是17个基础顺串大小,而文件4是有31个基础顺串大小。
第六次合并,我们将1、2、4中的顺串合并到文件3中进行归并,生成了一个包含57个基础顺串大小、也就是包含全部数据的最终的顺串。
虽然归并的次数还是6次,但每一次归并的过程中,并不像多路归并需要读取全部的数据,可以只读取部分的数据。这就是为什么多项规定排序可以减少磁盘IO。
IO次数: 39 + 35 + 36 + 34 + 31 + 57 = 232个基础顺串:每个顺串平均4.07次移动。相对于两路归并,会大大减少IO,因此Greenplum使用多相归并排序。
三、Greenplum的排序算法
前面是介绍了Greenplum使用的内排序和外排序的原理,现在从实战部分我们看一下,Greenplum排序节点如何实现的?
那么之前的执行器的直播内容中,我们也有介绍过,执行器迭代三部曲,一个是初始化,一个是执行,一个是做清理工作。
1. TurpleSort
那么在初始化的时候,排序调用的是ExeclnitSort这个函数,它主要是负责初始化SortState的结构体。
| 类型 | 字段 | 说明 |
| ScanState | ss | 查询状态信息 |
| bool | randomAccess | 排序后的元组是否需要随机访问 |
| bool | bounded | 是否是TopK查询 |
| int64 | bound | TopK查询中K的值 |
| bool | sort_Done | 排序步骤是否完成 |
| GenericTupStore* | tuplesortstate | 根据排序算法类型,指向Tuplesortstate或者Tuplesortstate_mk |
| bool | delayEagerFree | 某个Segment的排序节点输出最后一条元组后是否可以提前释放内存 |
执行器迭代三部曲的第二步是执行,调用的是ExecSort。该函数从下层Outer节点读取所有元组,并传递给tuplesort模块进行排序。

TupleSort是排序节点的核心,算法主要阶段:
- 第一阶段初始化TupleSort,通过调用函数tuplesort_begin_common,生成Tuplesortstate。Tuplesortstate用于描述排序所需的信息
- 第二阶段插入元组,每次调用函数puttuple_common,会根据当前TupleSort的状态,选择将元组插入到不同的位置。
- 第三阶段负责实际的排序逻辑,通过调用函数tuplesort_performsort,实现对已经存储好的输入元组进行排序。根据当前TupleSort的不同状态,输入元组可能存储在内存或者文件中,TupleSort会选择使用不同的算法进行排序。
- 第四阶段负责输出排序后元组,在排序完成之后,每次调用函数tuplesort_gettuple_common,即可获取排序后的元组。同样,根据当前TupleSort的不同状态,算法选择不同的方式返回有序元组。
下图是TupleSort的状态机,当ExecSort将元祖输入到TupleSort,TupleSort是TSS_INITIAL的状态,当数据量越来越多时,如果符合Top K 条件,会切换到BOUNDED状态,则会使用堆排序算法,如果数据持续增多,超出工作内存,则状态会切换成BUILDERUNS,这就是元组插入状态的三个状态。插入完所有元组后,ExecSort会执行PerformSort,在排序阶段,如果状态是BUILDERUNS的话,就会执行外排序算法去规避顺串。
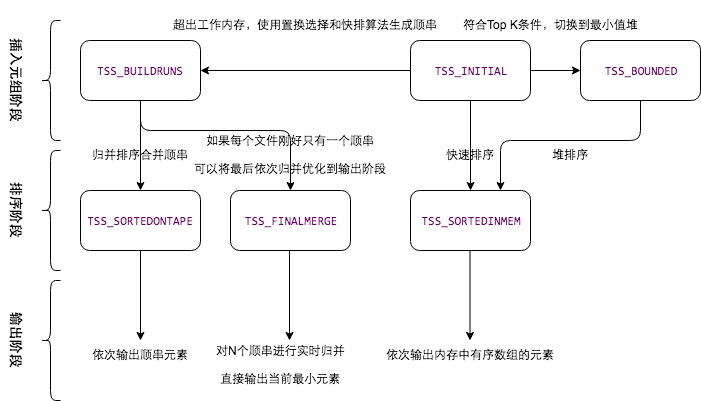
这里有一个优化的状态叫FINALMERGE。为什么对外排序还需要一个额外的状态?在归并的时候,在倒数第二次归并时,如果每一个输入文件只有一个顺串,我们就可以在去排序好元组的时候,直接从n个文件里去用最小的元素进行一个比较,从而减少一次磁盘IO。FINALMERGE这个状态是对外层排序的一个优化。
2. 多键排序
多键排序是Greenplum特有的一种排序方式,它的优势主要是对具有相同前缀的字符串进行高效排序。在现实世界里,拥有相同前缀的字符串是非常常见的,比如URL都以https://为前缀,每个具体站点也拥有自己的前缀,比如Greenplum站点的每篇文章都以 https://cn.greenplum.org/ 为前缀。对这些字符串进行排序的时候,多键排序优势明显。
多键排序算法本质上是快速排序的扩展。假设待排序数组为a,数组元素是长度为K的字符串,MultiKey Sort和快排类似,也是一种“分而治之”的思想。每次划分时需要在prefix+1的位置选取一个基准元素。
之后进行划分的时候,基于基准元素把数组分成三部分,第一部分是和基准元素相等的,另外一部分是比基准元素小的,第三部分是比基准元素大的。那么这样就可以生成了三个子序列,从而可以递归的去处理这三个子问题。
递归时需要注意的一点是,对于第二个子序列,在当前prefix+1的位置,它的基准元素是一样的,因此下次排序的时候,可以忽略基准元素,直接跳到每个字符串的第prefix+2的字符进行比较。

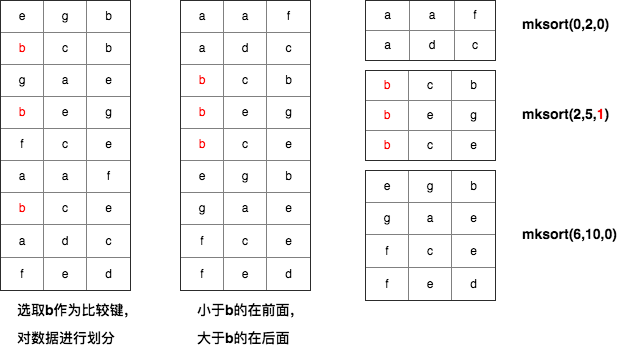
下面通过一个例子,介绍一下多键排序算法的流程。多键排序使用函数mksort(begin, end, pos)对从begin到end的字符串数组进行排序,且排序键从第pos个字符开始,即可以跳过pos之前的前缀。假设字符串数组长度为n,那么调用函数mksort(0,len-1,0)即可完成对字符串数组的排序。
如下图所示,多键排序首先随机选取排序键(假设是b),并按照排序键对字符串进行排序,比b小和比b大的字符串,都会递归调用mksort,并且排序键仍然从第0个字符开始。首字母为b的字符串递归调用mksort(2,5,1),由于可以跳过前缀b,排序键从第1个字符开始。算法递归进行,越到后面,跳过的前缀数越多,字符串比较的代价也越低。
四、排序在Greenplum中的应用
排序在Greenplum有非常广泛的应用:包括Group Aggregation、Merge Join、Distinct Aggregation、和Sorted Motion。
1. 分组聚集
Greenplum的聚集节点使用两种聚集方式:哈希聚集和分组聚集。分组聚集应用了排序的思想,如果数据基于分组键有序,那么聚集可以拆解为若干个朴素聚集的组合。
下图的执行计划是这条Query,求学生分年级的平均分。在Greenplum中需要两阶段来完成。
SELECT avg(score) FROM student GROUP BY grade;
第一阶段是在每个segment上,通过分组,使用分组聚集,对一年级二年级三年级的学生分别生成一个聚集后的结果。再在第二阶段聚集,把每一个segment上结果进行一个合并。
2. 归并连接
连接也是很常见的一个操作,Greenplum连接算法包括:嵌套循环连接,哈希连接和归并连接。归并连接同样应用了排序的思想,如果数据基于排序键有序,那么两个表的连接可以通过归并的方式,仅遍历一次数据,就完成连接操作。
下图是对学生以及他参加的课程这样两个表做一个连接。
SELECT * FROM student, class_enroll where student.id = class_enroll.sid;

如果确保student和enroll有序,就可以使用归并连接。那么什么时候有序呢?除了添加显示的sort节点,通过索引或者通过两个merge join的输出和另外一个表去做join,就可以认为这个merge join的输出也是有序的。
3. Distinct聚集
第三个应用是Distinct聚集,聚集中的去重操作,同样也可以基于排序完成。它是如何实现的呢?
步骤1:延时执行转移函数,tuplesort_putdatum(peraggstate->sortstate, value, isnull);
一个聚集的操作需要执行转移函数。例如求sum的时候,需要把当前状态值加入原组在相关列的值,例如元组1的分数加上元组2的分数,加上元组3的分数,这样的加法就是sum的转移函数。但如果要做distinct的时候,就不能再简单的进行加法,因为需要过滤掉相同的值。。
步骤2:排序, tuplesort_performsort(peraggstate->sortstate);
因此基于排序去做distinct的聚集的时,就要在执行转移函数的时候进行一个延时处理,把当前要加的元祖列的值存入到一个TurpleSort里。遍历所有元组后,要对TurpleSort中的列进行排序。
步骤3:去重
排序之后再做一个去重加上执行转移函数的操作,如果当前元组distinct键和上一个元组相同,或者同为NULL,则跳过当前元组。否则执行转移函数。
是通过排序加延时执行转移函数的方式,Greenplum就非常巧妙的实现了Distinct的聚集。
4. Sorted Motion
在分布式环境下的一个特有的排序应用,就是在Motion的时候。
Greenplum在跨Slice需要通过motion节点来传输数据。Motion的Receiver需要接收多个Sender的数据,虽然每个Sender的数据保证有序,但Receiver端也需要保证数据全局有序。
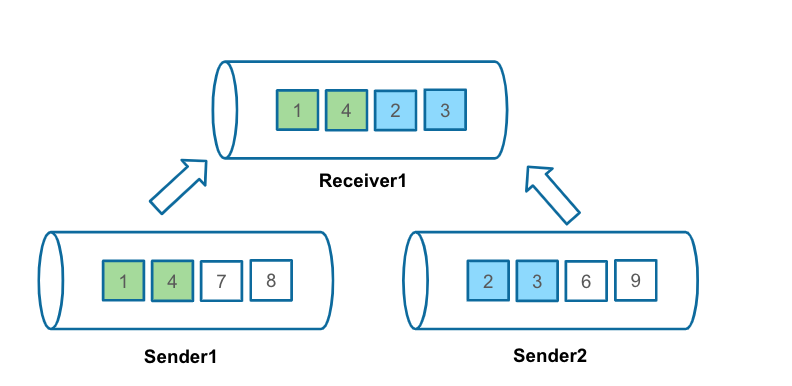
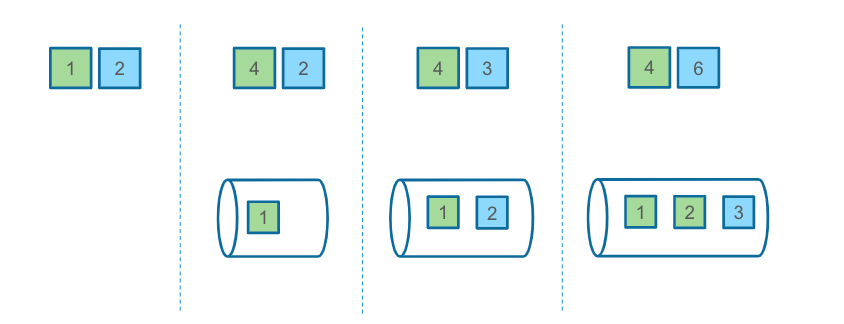
因此需要在Motion之间做一些额外的处理,也是应用归并的策略。首先读取每个Sender的第一个元素,之后在Receiver端进行归并排序。
最后做一个总结,本文介绍了排序中使用的内排序算法,包括快速排序和堆排序,以及当数据量超过内存需要使用外排序算法时,Greenplum考虑的几个点:
- 生成尽可能大的顺串
- 高效比较多个顺串的最小值
- 减少IO次数
接着我们介绍Greenplum特有的多键排序以及排序在Greenplum中除了order by之外的一些典型应用场景。如果大家想动手试一试排序,那么大家可以先从源代码开始,下载Greenplum进行编译。
在Greenplum开源社区有非常详尽的readme教你搭建Greenplum的环境。如果你希望收到Greenplum的一些Pull Request或者Issue的更新,也可以去关注Greenplum项目或者Start。如果你希望为Greenplum社区做贡献,欢迎fork一个自己的分支,尝试提一些PR。