Semi-join(半连接)是用来处理外表的记录是否在内表中存在与其匹配的行,而无需考虑匹配行的条数,半连接的返回结果集仅使用外表数据集,使用场景如:in、exists、>|<|= any等操作。本文将为大家详细介绍Semi-join在Greenplum中的三种实现方式。
Semi-join 是 Greenplum 的一种内部算子,用户无法直接在 sql 语句中使用, semi-join 算子可以用在 nestloop 、 hashjoin 以及 mergejoin 中。与普通 join 算子不同,外表一行数据只要在内表中找到与其匹配的行即可返回,无需将内表数据全部过滤一遍。
Semi-join在GPDB中有三种实现方式:semi-join算子、inner join (外表,unique(内表))、unique(inner join(外表,内表)),通过执行计划依次对每种方式进行介绍。
Semi-Join算子
Semi-join有nestloop semi-join、hash semi-join以及merge semi-join三种形式。外表每行数据在内表中进行探测,只要在内表中找到满足条件的记录,外表数据返回,继续处理外表中下一条数据,无需扫描内表中其余数据,以nestloop semi-join为例,如果第一行数据就符合条件,那么内表其他数据都不需要再扫描,普通nestloop算子每条外表数据都需要对内表做一次全表扫描。Semi-join内外表位置固定,受语义影响,不能交换位置。
建表并插入数据:
create table t1(tc1 int);create table t2(tc1 int);insert into t1 select generate_series(1,6);insert into t2 select generate_series(3,10);
通过调整enable_hashjoin、enable_nestloop、enable_mergejoin三个参数的值构造semi join的三种情况。



Semi-join算子的优点:实现简单,不需要增加额外算子。
Semi-join算子的缺点:Semi-join中内外表位置受语义限制,无法交换,但是join中有些场景小表做内表性能更佳,如hashjoin(小表做内表可以尽量避免使用外存)和nestloop(小表做内表可以将内表数据物化,不需要每次重复扫描)。
Inner Join(外表,unique(内表))
如果内表连接键数据没有重复,那么semi-join可以转换为inner join,因此可以将内表数据先去重,去重后的内表与外表进行inner join连接,实现semi-join的功能,inner join内外表可以交换,从而选择较优计划。
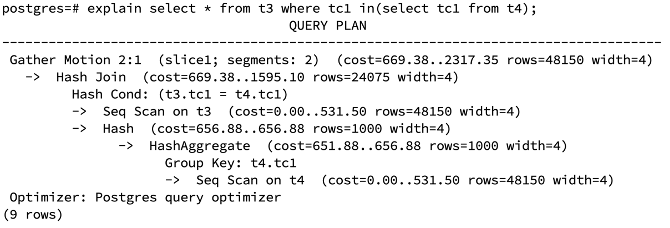
create table t3(tc1 int,tc2 int);create table t4(tc1 int, tc2 int);insert into t3 values( generate_series(1,100) ,generate_series(1,1000));insert into t4 values( generate_series(1,100) ,generate_series(1,100));执行10次”insert into t4 select * from t4;”向t4中插入重复数据。analyze t3;analyze t4;
去重后t4表数据量较小,被选择为内表:
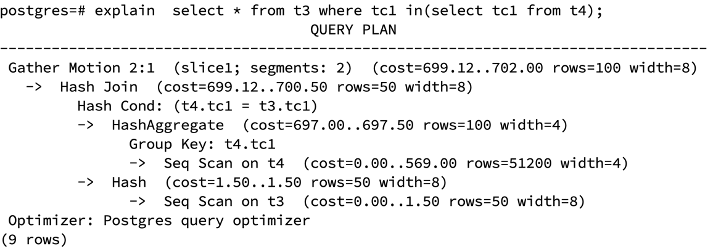
Delete from t3;Delete from t4;insert into t3 values( generate_series(1,10) ,generate_series(1,10));insert into t4 values( generate_series(1,100) ,generate_series(1,100));执行10次”insert into t4 select * from t4;”向t4中插入重复数据。analyze t3;analyze t4;
去重后的t4表数据量较大,做外表,小表t3做内表。
Unique(inner join(外表,内表))
以上两种方式在postgres单库中已经够用,而在MPP数据库中除了考虑连接顺序还需要考虑数据在节点间的分布,上述两种方式只能支持内、外表都按照连接键进行hash分布,或者外表是分布式表,内表复制的场景。无法支持外表复制而内表分布式的场景。
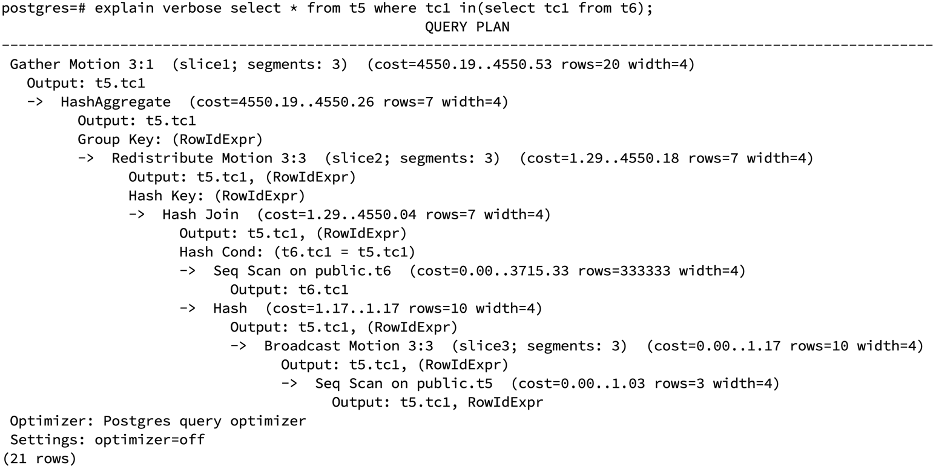
如果两个表t5和t6都是随机分布,外表t5数据量很小,而内表t6数据量很大。为实现semi-join,一种方式是两边均按照连接键重hash,一种是将t6广播,这两种数据转发的代价都相当大,若是inner join,可以采用广播t5的方式,但semi-join若是广播外表按照上述两种实现方式会得到错误结果,外表数据有重复。
因此MPP新增一种semi-join的实现方式,将外表数据进行广播,并对每条外表数据增加rowidexpr列,进行唯一标识,rowidexpr为int64的数据类型,为防止不同节点内产生相同的唯一标识,以节点编号segmentid作为该值的高16位,广播数据后,先做inner join然后对join后的结果按照rowidexpr列去重。
create table t5(tc1 int) distributed randomly;create table t6(tc1 int) distributed randomly;insert into t5 select generate_series(1,10);insert into t6 select generate_series(1,1000000);analyze t5;analyze t6;
以上就是semi-join在Greenplum中的三种实现方式,不同的方式适用于不同场景,需要根据代价pk选择出较优计划。


