起初,Web应用开发者青睐MongoDB的主要原因是它支持“无模式”的数据建模:以JSON文档的形式。 这对于之前大量被关系数据库的严格模式限制所困扰的开发者来说,是一个非常受欢迎的解脱。 然而,多年来MongoDB的两个令人担忧的问题是数据持久性和ACID事务支持。 MongoDB一直在采取一种渐进的方式来解决这些问题,并在最新的4.0版本提供了多文档事务支持。 在这篇文章中,我们将回顾这个渐进过程中的细节,并重点阐述MongoDB在事务型并需要高性能(低延迟和高吞吐)的应用程序环境中不足之处。
MongoDB的发布历史
1.0 发布(2009)
正如1.0发布公告中所强调的,起初MongoDB并非被设计为一个具有自动分片和复制功能的分布式数据库。它的初始设计仅适用于单主,主/从和副本对【Replica Pair】环境。 这种方式与当时流行的MySQL/PostgreSQL数据库所提供的特性非常相似。 而MongoDB当时的重点是为Web开发者提供一个JavaScript的数据存储服务 。
2.0 发布(2011)
MongoDB在2.0版本中添加了副本集【Replica Set】(提供了3节点故障自动转移机制,取代了2节点副本对)和Sharded Clusters(每个分片【Shard】被建模为副本集,多个副本集使用单独的配置服务器来协调)概念。 然而,当时却出现了多个关于MongoDB丢失数据的报告。 特别是2011年11月的这篇文章,它引起了MongoDB社区的巨大惊愕。 MongoDB的最初设计意图是让应用程序开发者来自行设置写入级别(通过writeConcern参数,默认为0),不引入日志【journaling,redo log】(在基准测试中能提供更快的写速度),并使用基于集合锁【collection-level locks】的全局并发控制方案,但却事与愿违。 正如MongoDB的HackerNews上的回复所示 ,开发者正在将MongoDB的使用场景由简单的单节点JavaScript应用推广到了需要线性可扩展性和高可用性的关键应用领域,同时在持久性【durability】和性能方面又不希望有任何妥协。
尽管MongoDB是按照CAP定理的可用性和分区容忍性(AP)来设计了复制架构,但它却将自己作为一款CP数据库推向市场,这导致用户/客户的迷惑与不满。 如下所述, 2013年(v2.4.3)和2015年(v2.6.7)的 Jepsen分析【译注:A framework for distributed systems verification, with fault injection】证实了这一缺陷:MongoDB存在数据丢失的情况。
Mongo的一致性模型在设计上就是有缺陷的:“强一致”读不仅可以看到过期的文档版本,而且还可以读取到不应存在的写入数据【译注:中间态数据】。 前者(据我所知)是一个与Mongo文档中声明的一致性所相反的新结果。而后者则一直是Mongo记录在案的问题。 我们还注意到之前Jepsen帖子中所提到的结果:几乎所有写级别【write concern】都允许数据丢失。
3.0 发布(2015)
MongoDB将其持久性和性能的大部分问题归结为其底层MMAPv1存储引擎。 MMAPv1是一个基于BTree的存储引擎,它无法扩展到多个CPU内核,并发性能差(使用了集合级锁)且不支持磁盘空间压缩。 这样带来的最终结果就是,MMAPv1在写繁重的工作负载中的性能表现极差。 为了缓解这些问题,MongoDB于2014年12月收购了WiredTiger,并使其成为3.0版本(2015年3月)的可选存储引擎。 在3.2版本(2015年12月)中,WiredTiger替换了MMAPv1,成为默认存储引擎。 但是,数据复制却继续使用v0协议,于是数据丢失仍然是用户的一个主要问题,尤其是在多数据中心环境中。 Jepsen分析留意到了以下内容:
协议v0仍然受到仲裁用户的欢迎,特别是对于三数据中心部署的场景,其中一个数据中心会一直充当作仲裁者。 具体地说,当两个数据中心被分区且仲裁者可以看到两者的情况下,协议v1允许仲裁者在两个数据中心的选主投票过程中进行角色反转【译注:仲裁者和普通成员之间的身份切换】,然而协议v0可以抑制这种反转行为。 在这两种协议版本中,为了保持两个数据中心的写入可用性,用户将无法选用多数派写级别【majority write concern】。 这意味着当跨数据中心的分区恢复后,可能会丢弃掉自一个数据中心的成功写入。
3.4 发布(2016)
MongoDB将其默认的复制协议从不安全的v0更新为3.2版本中更安全的v1,紧接着是3.4版本中的主要错误修复。 尽管实际的数据复制仍然是异步的(副本集中的从属服务器从主服务器中复制),但现在采用了Raft分布式共识协议来对副本集进行选主。 结果就是,由于从属服务器现在可以通过Raft被自动选举为新的主服务器,所以当主服务器宕机或者产生网络分区时,写入不可用时间变得比以前更短。
除了上述的复制协议更改之外,MongoDB采用多数派读级别【majority read concern】来解决3.2中的脏读【dirty reads】问题(读到不正确的数据),采用可线性化读级别【linearizable read concern】来解决3.4中的陈旧读【stale reads】问题(未读取最新数据)。 这些特性使得MongoDB 3.4通过了Jepsen测试 。 但是,正如我们将在接下来的章节中看到的那样, 开发者为在MongoDB上进行可线性化读取而支付的隐性成本是低性能,如高延迟和低吞吐。
4.0 发布(2018)
在MongoDB十多年来宣扬非规范化文档数据建模的好处以及避免对多文档ACID事务的需求之后,MongoDB最终在最近发布的4.0版本中添加了单分片内的ACID事务支持。 只要全部文档都存在于同一个分片内(比如,存储在副本集的单个主节点上),那么对这多个文档的更新就会有ACID事务保证。 不过真正的多分片事务目前还不支持,它可以让开发人员不再关心文档到分片映射关系。这意味着MongoDB Sharded Cluster在部署上尚不能利用目前的(单分片内的)多文档事务功能。
单分片事务在MongoDB中是如何工作的呢?
正如我们在上一节中所看到的,MongoDB的事务演进之路已经持续了十年,这其中经历了许多曲折。 鉴于其最初设计为单节点写入,在演进之中(即使是对单个分片操作的上下文中)必须替换存储引擎和复制协议,这不应该让人感到意外。 接下来让我们回顾一下单分片事务在MongoDB 4.0中的实际工作方式。 下图展示了一个具有2个MongoDB客户端的电商应用程序 – 客户端1执行一个更新事务,客户端2读取客户端1的事务更新的记录。
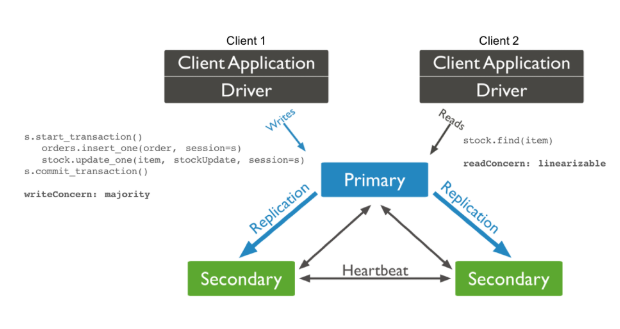
MongoDB 4.0 的事务示例
假设订单下单成功,客户端1将一个新的order文档插入到订单集合中,同时还需要更新item的库存信息(存储为另一个集合的文档中)。 显然,这两个操作必须以符合ACID事务的方式来完成,因此在操作前后需要使用start_transaction和commit_transaction语句。 如MongoDB文档所述,唯一能对数据持久性进行保证的写入级别是多数派写(writeConcern: majority )。 这意味着大多数副本(在此示例中为2)应在主节点确认写入客户端成功之前提交更改。 于是事务将保持阻塞状态,直到2个从属节点中的至少一个成功通过异步复制从主节点提取更新,不过异步复制容易受到不可预测的复制延迟的影响,尤其是在负载较重的情况下。这使得MongoDB的单分片事务写入速度比其他的事务型NoSQL要慢,例如YugaByte DB,它使用了基于Raft的同步复制,并将其推广到了数据复制(不仅仅用于选主)。
假设在客户端1对主副本进行事务提交之前,客户端2尝试读取了同一item的库存信息。 正如之前我们在使用YugaByte DB克服MongoDB分片与复制限制一文中所强调的那样,在MongoDB中保证强一致读的唯一方法是使用linearizable read concern(而不是majority read concern) 。 即使写事务支持快照隔离级别并且上一个数据快照已经在主副本上可读,非事务性写(没有用start_transaction和commit_transaction包围)也无法得到相应的保证。 而可线性化读【Linearizable reads】可确保读到真正被提交的数据,无论是使用事务写还是非事务写来更新数据。 以下是MongoDB文档的具体引用:
与“多数派”读级别【majority read concern】不同,“可线性化”读级别【linearizable read concern】会与从属节点们确认:读操作是从一个能够应答确认”多数派”写级别的主节点来读取【译注:需要检查是否出现了网络分区:避免从一个旧的主上进行stale read】。 因此,可线性化读级别的读取速度可能明显慢于“多数派”【majority】或“本地”【local】读级别。
在高性能事务应用环境中,咨询其他副本以提供强一致性读取是MongoDB中第二个也是更重要的减速源。 在跨地理分布式部署中,由于每个节点可能完全位于不同的地理区域中,所以延迟会变得更糟。而事务型NoSQL(例如YugaByte DB)不会遇到此问题。 YugaByte DB依赖于基于Raft的同步数据复制,其中跟随者副本由领导者副本同步更新。 这意味着YugaByte DB可以直接由分片的领导者副本来提供强一致读取,因为它可以保证保持客户端可以看到的最新值。
对二级索引的影响
二级索引与主键更新保持一致通常需要多文档事务,例如,主键在document1中更新,而二级索引元数据在document2中更新。 MongoDB不支持全局二级索引,尽管所有的二级索引元数据是全局方式统一存储,但是它只支持本地二级索引,即二级索引也需要在本地的分片中(比如document1和document2在同一个副本集中)。 需要注意的是,当开始对主键进行写入时,本地索引不会紧跟着保持一致。 这需要以滚动方式来手动构建本地索引 。 特殊情况下(例如唯一索引)要求在索引完成之前停止所有新写入 。
随着4.0中单一分片事务的引入,很自然地期望MongoDB能弃用当前的带外索引方式,转而提供一种完全强一致并在线的本地索引更新方式。 但是,索引方式在4.0版本中保持不变。
MongoDB事务中的隐藏代价
MongoDB添加的单分片事务是一个值得欢迎的变化,它改善了过去几年中出现的持久性问题或强调不需要ACID事务的情况。 但是为了保持最初设计的分片与数据复制体系结构的完整性 ,它牺牲了其事务对需要严格延迟与吞吐量需求的高性能应用的适用能力。 使用MongoDB 4.0单分片事务的应用必须要处理好以下问题。
缺乏水平可扩展性
MongoDB Sharded Cluster中没有事务支持,这意味着无法将一个有事务需求的3节点副本集系统转换为一个可提供水平写伸缩性的完全分片系统。 对于许多快速增长的在线业务来说,这是一个致命的问题,因为它们无法接受单个主节点上的写入能力。
高延迟
如上一节中所述,在执行确保持久性的持续写入并同时执行强一致性的持续读取时,MongoDB在写入和读取操作上都遭受到高延迟影响。 于是应用开发者们现在需要强制引入一个单独的内存缓存服务(如Redis)来减少读取延迟。 但是他们又不得不处理数据在缓存和数据库之间的不一致问题。 如果数据量足够大且查询的数据无法完全被内存容下时,那么仍需要被访问的数据将会频繁地从缓存中逐出。 这将会导致大多数读操作依然要访问数据库,这意味着无法通过缓存来达到最初的低延迟目标了。 与此同时,数据层的运营复杂度却成倍增加了。
低吞吐
一个副本集只能由单个主节点来提供写入操作。 这意味着即使是互不相关文档的写入操作也必须通过这个主节点。 从属节点可以潜在为读操作服务,这有助于提供更大的读吞吐量,但在写操作的上下文中完全无法使用。 于是在具有大量写的工作负载上,计算和存储资源会大量浪费,因为3节点副本集中的2个从属节点没有贡献与其资源消耗所匹配的能力。 而主节点上的更多争用操作将会降低整个集群的吞吐能力。
总结
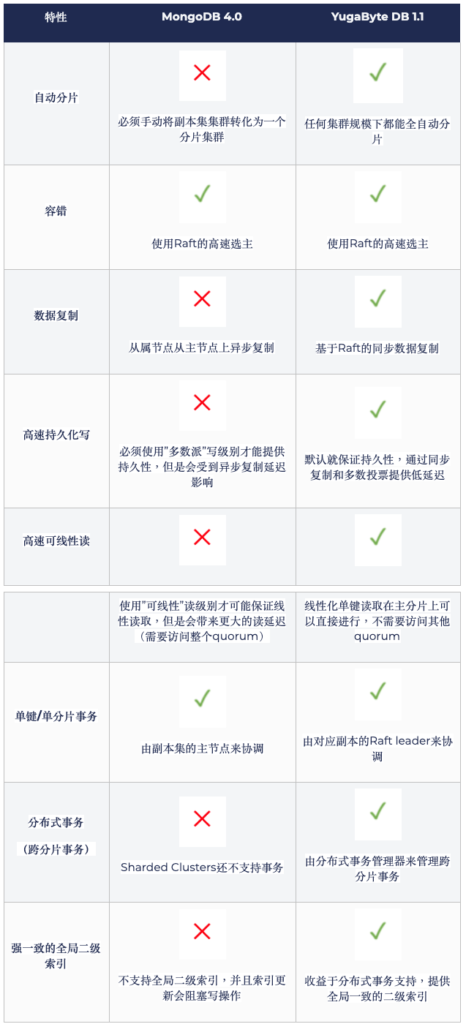
MongoDB 4.0 对比 YugaByte DB 1.1
尽管MongoDB在过去几年中提高了事务处理能力,但它在系统架构上仍然不如YugaByte DB等现代事务型数据库。 目前在MongoDB上使用事务意味着放弃高性能和水平可伸缩性。 在YugaByte中,我们认为不应该强迫快速增长的在线服务接受这样的妥协。 如上表所示,我们构建了YugaByte DB,同时提供了事务,高性能和线性可伸缩性保证。 一个3节点YugaByteDB集群支持单分片和多分片事务,并能按需(单区域或跨区域)无缝扩展,在保证低延迟读的前提下提高写吞吐量。
原文作者:Sid Choudhury VP, Product of yugabyte.com November 1, 2018
译者:马洪旭,Pivotal资深研发工程师 & Apache HAWQ committer,热爱开源技术,目前从事全文检索和数据库等相关的研发工作。
原文链接: https://blog.yugabyte.com/are-mongodb-acid-transactions-ready-for-high-performance-applications/

