《Greenplum走进济南》技术研讨会于7月3日成功举办,我们已经为大家整理了两篇演讲内容(《基于fdw的跨Greenplum集群数据库查询实现》,《基于Greenplum构建下一代数据分析平台》),今天,第三篇演讲内容是由Greenplum中文社区成员阿福带来的Greenplum问题定位与性能调优,相关PPT已上传中文社区网站的下载页面cn.greenplum.org/download,欢迎大家下载获取。
作为一名DBA,在实操的过程中,我也积累了一些运维的经验,今天通过这篇文章与大家分享一下,如果大家有任何问题,也欢迎加入我们文章底部的技术讨论群和我们交流。
本文将从两个方面为大家进行介绍,第一个方面是为大家介绍一些应用开发技巧,第二个从DBA的角度来进行一些问题定位和性能调优的经验分享。
一、应用开发技巧
公司内部通常业务开发团队会配一个DBA,那么在业务开发过程中出现问题时作为开发人员可能会第一时间找到DBA来处理相关问题。这里将通过一些简单的例子介绍,来帮助各位开发人员学会如何解决这些问题,从而来减轻DBA的一些压力。
01 Greenplum架构
首先为大家介绍一下Greenplum数据库的架构。之前也有很多文章专门介绍过Greenplum数据库的架构,具体大家可以参考这篇文章。Greenplum可以被认为是一个完整的黑盒子,提供统一的访问出入口:
- Greenplum数据库是一款MPP架构的集群,整个集群对应用程序提供统一的访问入库,访问永远只能通过Master节点接入,对客户/应用方来说,Greenplum集群是一个完整的黑盒子,只提供唯一入口;
- 基于这个概念,应用在做迁移适配时,也不需要做多节点改造,只需要将原来的Oracle/DB2访问串修改为Greenplum Master节点的访问串即可;

02 查询计划与数据分布概览
查询计划相对于物理架构图是一个更加逻辑的层面了。这里主要展示了三个概念。
- 执行计划
在做应用开发或者做数据库调优时,首先大家必须要看下图中间的查询计划。它的使用,如果大家对PostgreSQL比较了解会知道会用到explain [analyze]。执行完会看到查询计划的每一步。
- 数据分布
第二个概念就是数据分布。下图中有个简单的例子。这里有两张表,一个是t1表,一个是t2表。每个表都有6条数据,在做数据入库时,由于Greenplum是分布式架构,因此数据会被打散到各个节点均匀分布。下图以3个节点作为例子,如果都以c1列作为分布键的话,数据会均匀分布到3个节点上,每个节点会有2条数据。均匀打散的数据有利于并行查询,例如本地hash join,由于节点间并行执行,会大大提高join的效率。
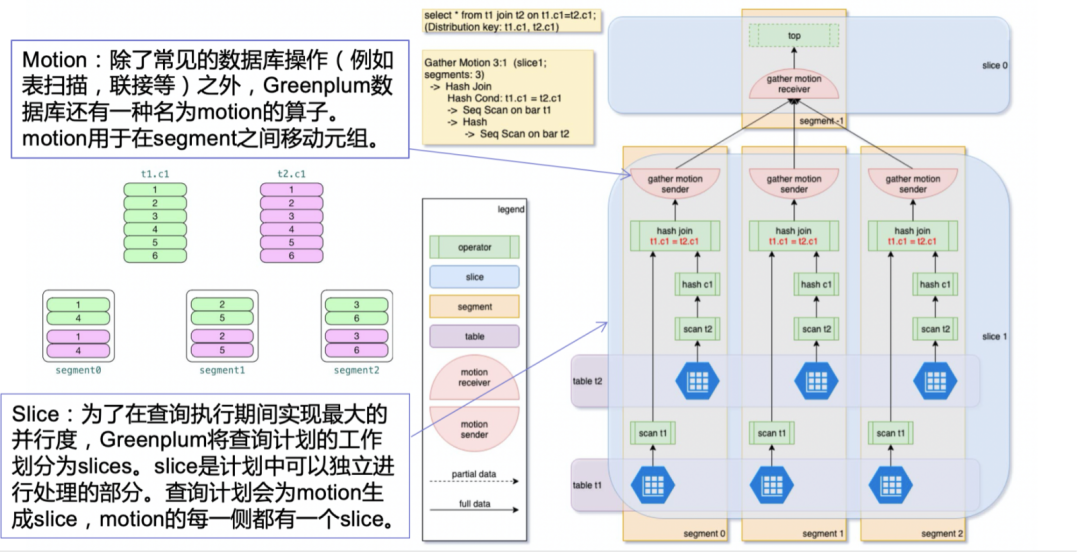
上图也为大家提到了2个概念,在执行查询计划从master下发执行时,会产生一些不同的操作,从而产生这样一些概念(motion/slice/gang的概念)。通过整个并行架构和处理方式,以及数据分片从而提升数据处理效率。
下图为大家详细介绍了分析查询计划。对于一个分布式架构的数据库,在看查询计划时,通常是从底部往上看。首先看优化器是什么,这里的GPORCA是由原厂打造的比较厉害的优化器。当然目前在某些场景下还是比较慢,但是随着业务复杂度以及业务数据量的增加,GPORCA会大大提升查询技能。
往上看会看到一些内存相关的信息,在上面就是我们需要关注的重点。Filter是过滤,通常是查询语句中的Where条件语句。Seq Scan是顺序扫描,这个一般是在做大数据量查询时,从存储层扫描数据。再往上看,每个节点所进行的操作,比如Hash join等,都会显示在这里。我们可以看到,每个阶段都会有一个cost,当我们判断查询计划的是否高效就是基于cost的值来进行。如果查询计划里某个cost值非常高,我们可以通过后续介绍的一些方法来看看是否能提高查询计划的效率,降低这些高cost的处理。
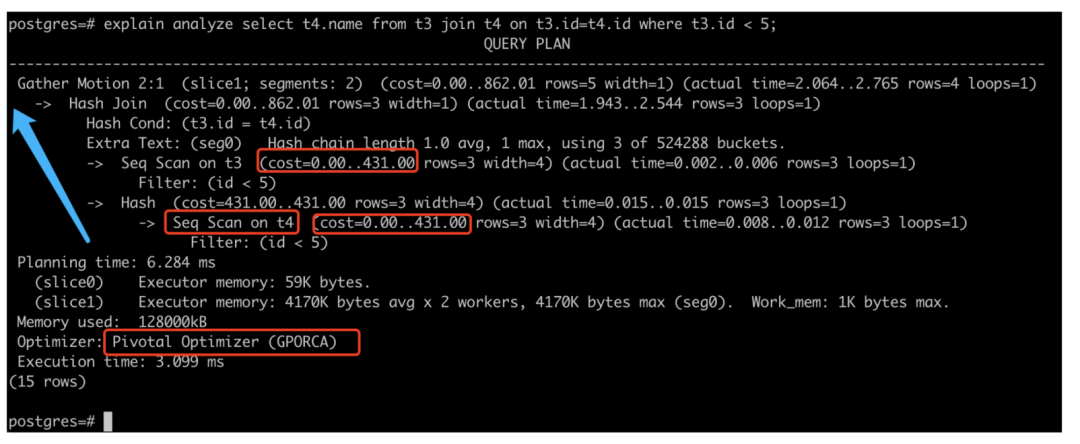
接下来,为大家介绍一些开发技巧
- 技巧一:模型设计
在数据分析/数据仓库模型设计中,星型模型/雪花模型是主推的设计模式,即大事实表+小维度表组成的模式。在join的时候,会以事实表为基础,用维度表来进行数据移动,这样的话,整个数据在移动的过程中,对网络带宽的消耗不会太高,从而可以把数据以最快的速率打散到与事实表相一致节点上,再做连接,这样会提升效率。当然数据量过多的话,需要进行一些调优再来解决这个问题。
- 技巧二:存储模型的选择
存储模型的选择上,这里简单列了一些技巧:
- GPDB默认创建堆表,这与PostgreSQL数据库是一致的;
- 当表上频繁存在insert、update或delete操作时,选用堆表;分区表上的堆分区也同样适用此规则;
- 当表上频繁存在数据批量加载操作,极少有insert、update或delete操作时,选用AO表,能加速查询性能;
- 大的事实表,可以采用分区表的形式,分区根据查询逻辑进行定义是采用行存还是列存储;下面有一个行存和列存的对比供大家参考。
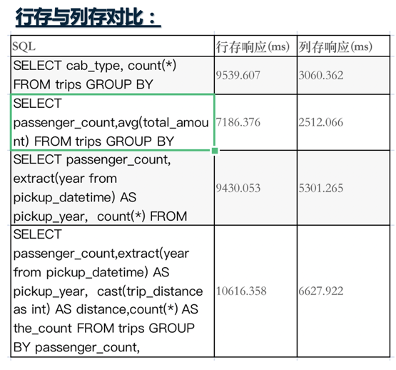
- 大的事实表,查询场景上列数较少的统计分析场景,选用列存表性能更优。
- 高压缩比模型选择用来节约存储空间;
- 低压缩比模型选择用CPU换取IO时间;
- 技巧三:分布键的设计
这里涉及两个概念:分布和分区。分布是一个物理的概念,是指当某条数据来了,经过hash后,应该放到哪个节点上。而分区是一个逻辑的概念,一个表做了分区后,每个节点上都会存在所有的分区,也就是说在做某个查询时,每个节点都会同时查询同一份分区。在查询时,通过分布键再去筛选,在分区里查询某一个数据。
下面列了一些分布键选择要点:
- 首先要显式的指定每一个表的分布键,不要采用默认选项;分布键尽量选用唯一度高的,可以保证分布均匀;
- 很少采用随机分布,只在确实无法决定一组能使数据均匀分布分布键时才做这种决定;
- 尽量选用单列作为分布键,只有在单列无法完成较均匀分布的情况下才选用双列;如果双列仍然不能分布均匀,就选用随机分布;
- 尽量不要选用where查询条件中频繁出现的列作为分布键;
- 不要选择日期或时间戳作为分布键;
- 多个表设计时,充分考虑分布键,达到多表关联可以做本地join的情况是最理想的。
下面是分区的使用技巧:
- 好的分区可以在查询中过滤到大部分无关数据;
- 只在大表上做数据分区,小表没有必要做,过度分区会导致查询缓慢;
- 尽量选用范围分区而少选用列表分区;
- 分区的选用和裁剪在以下操作符上有效:=, < , <= , >, >=, and <>;
- 通过EXPLAIN查看SELECT查询是否做了分区裁剪;
- 不要使用默认分区,默认分区在任何情况下都会被查询,有时候会拖慢查询性能;
- 分区键和分布键不能是同一列。
下面是数据分布与分区的图形化的展示。
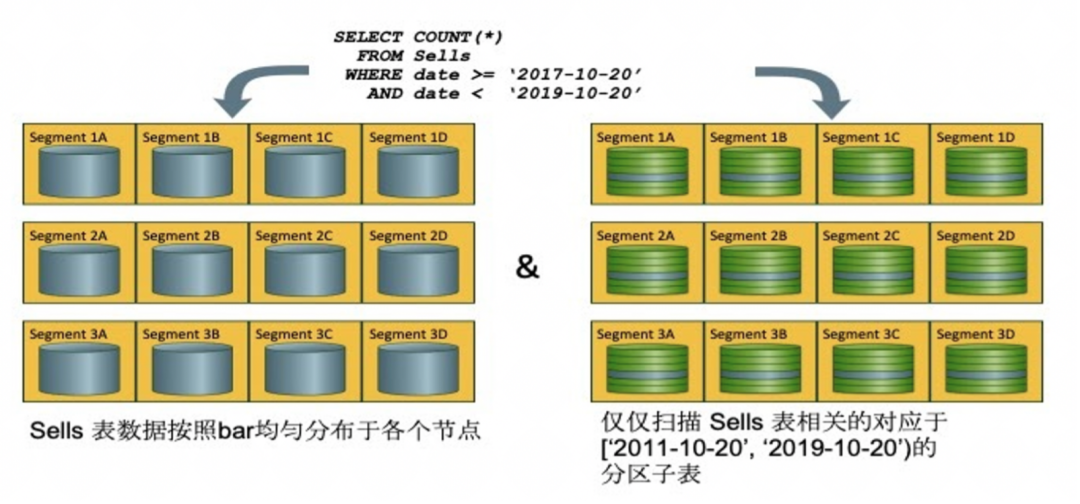
数据导入后,会在每个节点上打散分布,所有节点的分片组成了一个完整的数据集。右侧是一个分区表展示图,本次查询只查了部分分区。
下图为大家演示了一个分区表的实例。
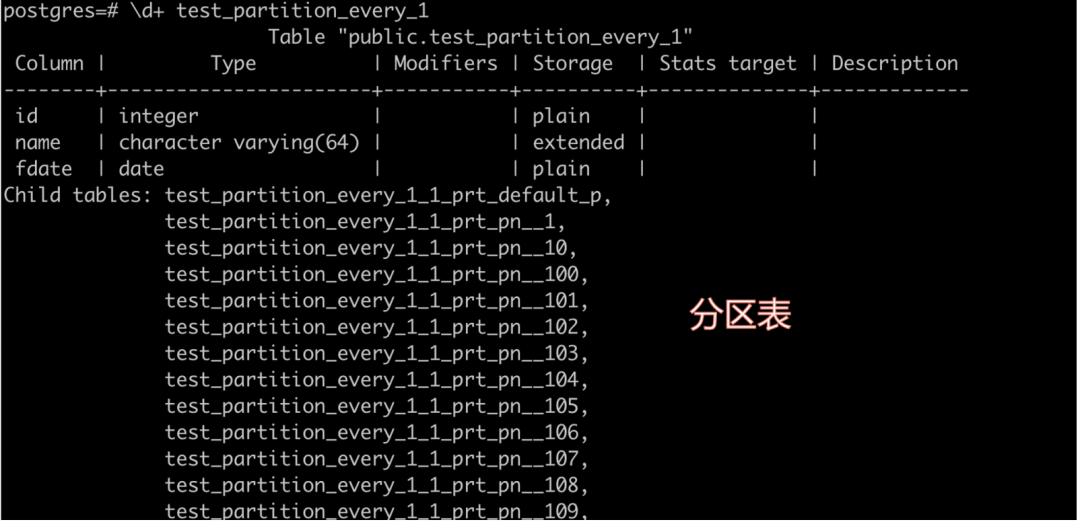
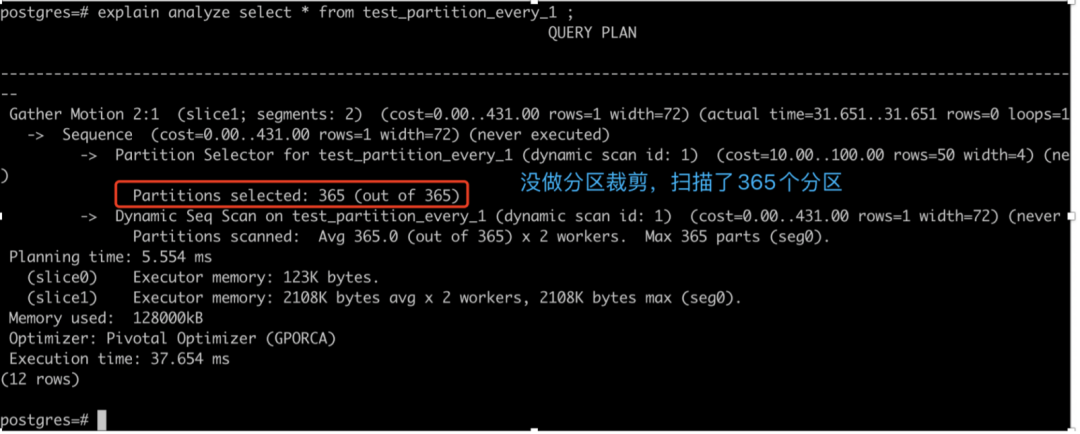
下图是一个没指定做分区裁剪的例子。没做分区裁剪,在做查询时,就从365个分区里把所有的分区都进行了扫描。如果做了分区裁剪,就会从中只选出一个分区进行扫描。
- 技巧四:什么时候用索引
对于一些对Oracle 或者SQL Server比较熟悉的人,可能习惯于一旦数据量大,就加索引。但在MPP数据库里,索引的使用需要谨慎。
- 虽然GPDB支持索引,但是大部分分析型场景下不推荐使用索引;因为分析型场景下,需要扫描大量数据;
- 只有在扫描单条或很少几条数据时,才使用索引;
- 增加索引后,进行充分的测试,并通过EXPLAIN ANALYZE确保索引被正常使用,如果索引不能对性能提升产生推动作用,尽快删除;
- 不要在经常被更新的列上创建索引;
- 批量装载数据前删除索引,装载完成后重建索引;
- 大的分区表上创建索引会自动给分区增加索引,删除索引时,需要分别删除主索引和所有分区上的索引;分区表上的索引不要创建在分区键上;
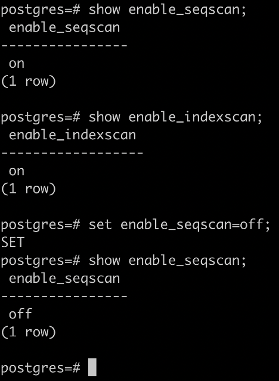
- 强制索引扫描GUC:set enable_seqscan=off;
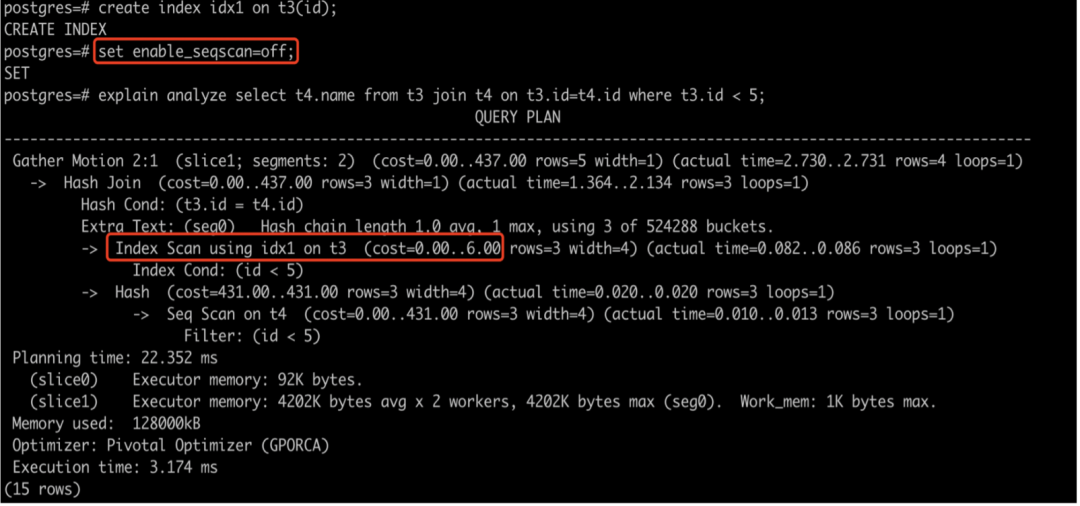
下面的例子中,我们关掉enable_seqscan后,就会去寻找索引,在这里,我们创建了个idx1的索引,这个代价就比较低。
二、
问题定位与性能调优
在第一部分,我们介绍了一些应用开发的技巧。接下来我们将从DBA的角度通过几个问题来介绍一些出现问题时如何做问题定位和性能调优。
01 MVCC和锁
以我的经验来说,在三分之一的情况下,出现的问题都绕不开MVCC和锁机制。
- MVCC
MVCC,全称是Multi-version Concurrency Control,即多版本并发控制;MVCC存在的目的,是在高效性和正确性之间找到一个平衡点;区别于串行化、一味追求高效的坑;相关的文章可以参考这篇文章。
并发访问中涉及的操作包括读操作和写操作。其中,由于同一份数据可以同时支持多人读取,因此读操作和读操作是不会冲突的。同一份数据的写操作和写操作则一定会发生冲突,此时便需要用锁来解决。读操作和写操作有时候也会出现冲突,MVCC可以很好的解决这一冲突,其优化的目标是读操作不会阻塞写操作,写操作也不会阻塞读操作。
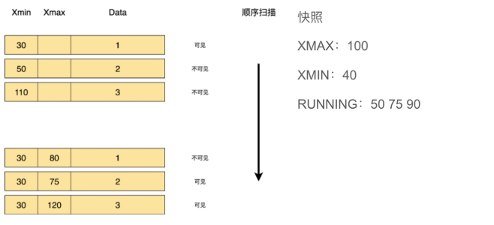
控制的机制可以参考下图。每一条记录里,隐藏字段中会有xmin和xmax这两个字段,用这两个字段和快照中的字段做比较,来展示事务是过期的、正常运行的还是未提交的。下图中,和快照中的数据做对比,xmin都是30,小于快照中的xmin 40。xmax 80,小于快照中的xmax 100,Running Array没有,因此,这个数据便已经被删除了。第二行中的75,正在Running,因此它是可见的。120大于快照中的xmax 100,此事务未被提交。
- 锁
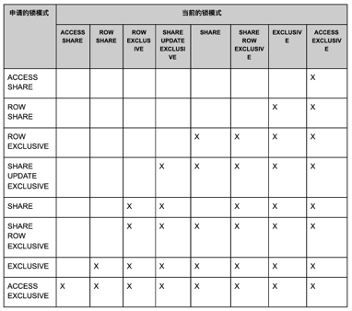
关于锁,大家需要注意的是锁和锁之间是互相冲突的。任何一个事务在数据库里发起后,都会生成锁,生成的锁会被用来支持自己的查询并排除其他的操作来操作正在运行的数据。下面是两个较为突出的锁冲突:
- “ACCESS SHARE”只与“ACCESS EXCLUSIVE”冲突;只读查询操作都将获取这种类型的锁;
- “ACCESS EXCLUSIVE”与其他所有锁冲突,ALTER TABLE, DROP TABLE, TRUNCATE, REINDEX, CLUSTER, VACUUM FULL操作均会申请该锁。
02 问题定位
在遇到问题里,如何定位问题,我总结了一些思路供大家参考:
- 遇到问题不要慌,一定是有原因的,不要急于采用kill -9、重启集群或重启机器等方法来强制处理;这种处理方法通常会导致数据库宕机时间远远大于耐心分析解决的时间;
- 首先看一下数据库是否还能继续使用,如果可以,尽快断开前端连接,避免新进入的查询对数据库造成更严重的影响;
- 然后通过观察数据库活动查询视图(pg_stat_activity)、锁视图(pg_locks)、数据库日志(gpAdminlogs/pg_log)来查找问题的蛛丝马迹,结合前面介绍的MVCC和锁原理知识,结合数据库模式设计与日常运维逻辑之间的处理关系,来最终解决该问题。
- 下面,我们来看几个问题定位调优的例子。
例子1
问题现象:
现场人员反馈,前端某一简单查询报表前两天查询还挺快的,这两天查询突然变慢了,而且越来越慢。
问题调查:
反馈的该业务表为分区事实表,每天凌晨数据入库;入库有支撑两种业务,一种为统计分析出报表到其他表;一种为前端网页程序提供简单查询。
解决办法:
- 首先查看该表上是否为前端查询提供了针对的索引,如果未提供,尝试使用索引;
- 如果已经提供索引,请尝试从执行计划下手查看是否正常走索引;
- 查看凌晨数据入库逻辑中是否有索引重建及统计信息收集操作,如果没有,请增加后处理。
例子2
问题现象:
现场人员反馈,基于某张表的查询全部超时,客户投诉严重。
问题调查:
反馈的业务所涉及的表是分区表,没有索引,均为批量入库操作,日常分析型查询响应时间均在秒级,今天的查询卡住属于突发现象。
解决办法:
登陆数据库,查看活动查询视图是否正常:select * from pg_stat_activity;
1)有锁 – 查看锁存在原因,八成因为入库晚正在执行truncate分区表等操作;
2)无锁 – 如果活动视图显示一切正常,那极有可能是segment节点由于某些非常规操作,存在锁表的孤立进程
例子3
问题现象:
新开发的业务,在一张分区表上运行缓慢;该表上的其他查询业务均正常。
问题调查:
该表数据量比较大,也做了有效的分区;开发提供的查询业务属于统计分析语句,不需要索引的参与。
解决办法:
首先第一反应就应该是:没走正常的分区裁剪;
通过EXPLAIN ANALYZE查看开发人员提供的语句是否正常;如果不正常,需要针对性的做查询语句调优,通常情况下,这种问题出现在业务开发与数据库设计不匹配上。


