2021年9月25日及27日,由VMware联合Intel等众多合作伙伴举办的为期两天的大型开源社区活动——2021智能云边开源峰会(2021 Open Source AceCon)成功在线举办。
盛会邀请了多位来自开源领域的技术领导者及重要贡献者,分享“云原生、边缘计算、人工智能”三大热门技术趋势及洞察,携手共同推进开源技术创新和开源生态繁荣。Greenplum中文社区也积极参与到了此次活动中, 来自原厂的内核研发杨峻峰在会议中发表演讲,介绍了Greenplum在当前的云热潮中,如何为各行各业提供云上的解决方案,助力生产环境中日益丰富的AI科学计算任务。 相关ppt欢迎前往Greenplum中文社区网站(cn.greenplum.org)下载专区获取。
对数据库行业了解的小伙伴都知道,Greenplum是一款有着丰富特性和扩展的数据库产品。但实际上,Greenplum 早已不再是一个单纯的”数据库”,我们的目标是将其打造成一个强大的大数据平台,满足用户的全方位的分析需求。
Greenplum是一款可以大规模横向扩展(MPP架构)的并行数据库,以PostgreSQL为内核,运行标准的SQL语句,能够很好的支持ACID特性。Greenplum提供了更丰富的特性,种类繁多的扩展使其满足各行各业的库内数据分析需求和复杂任务。此外,Greenplum可以灵活的将其部署在任何本地或者任意的云环境当中。
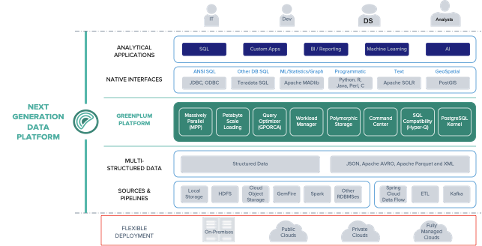
Greenplum自开源以来陆续正式发布了两个大的版本:5版本和6版本,分别使用了postgres内核8.3和9.4。即将发布的Greenplum 7将基于PG12, 内核升级工作我们已经完成,现在正在进行打磨和清理工作,把它打造一个性能优异的稳定版本。选择PostgresSQL作为内核,使Greenplum可以完全集成两个庞大社区的集体智慧,打造出更优异的产品。Greenplum原生支持的特性就已经远远多于很多新生产品。

要想把Greenplum打造为一个强大的数据库分析平台,需要把数据全部联通,Greenplum的数据联邦使这一切成为了可能。
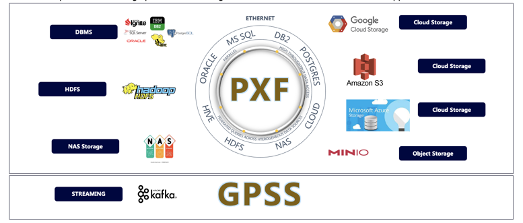
Greenplum提供了丰富的数据接口,可以方便的直接读取或者写入结构化和非结构化数据,并提供并行的提取和加载外部数据来对大数据分析场景下的任务进行了优化。外部数据可以从任意其他的服务来获取,例如云存储,其他的数据库等等。这里我们有两个重量级的扩展组件,一个是PXF,通过外表实现了简易的接口,并行的操作外部数据。另外一个就是GPSS,提供kafka连接器,可以流式的进行数据处理工作。此外,Greenplum提供了丰富的文件格式支持。
另一个数据联邦的重要新特性是用户可以在多个Greenplum集群部署,实现单集群查询其他集群的数据。
这么做有以下几个好处:
- 避免数据复制
- 公司部门和用例之间高度隔离
- 通过创建集群到集群的连接来提高数据承载量和并发的可扩展性
Greenplum在查询优化阶段实现多种优化,通过感知到对端集群的配置和数据的统计信息,可以尽可能的将对端集群的查询推到对端集群并行执行,也可以将连接和谓词尽可能的下推到对端集群执行,来减少数据在两个集群之间的传输。
Greenplum提供并开源了Madlib这个基于SQL的数据库内置的可扩展的机器学习库。很多小伙伴对python上的各种AI库较为熟悉,Madlib实现了类似的功能,而且提供了SQL的接口,也就是说,用户可以用select + 函数名来调用这个库。这就意味着,所有的数据调用和计算都在Database内完成而不需要数据的导入导出。由于应用在大规模并行处理的数据库内,它的可扩展性也非常好,能够处理较大量级的数据。

Madlib具有强大的数据分析能力。图分析也是它的专长。随着各行各业数据化转型的推进,大量文本信息被收集起来等待处理。因此对于文本数据,Greenplum通过GPText这一组件,提供了文本数据的提取,索引,检索和自然语言处理的能力。通过和Madlib的联合,Greenplum还可以对文本数据进行聚类,情感分析等处理。
除了扩展组件之外,Greenplum还提供了数据分析的语言扩展。Greenplum原生的有SQL标准的UDF,UDA支持。扩展的语言包括pl/pyhton、 R、 Perl、 java、 c、 c++等。为了安全性,Greenplum对这些语言支持容器化,使其运行在容器中。对于R语言,Greenplum还额外封装了GreenplumR库。使用这些扩展语言,用户无需额外学习数据库的知识,对于数据科学家来说无需额外的负担。
Greenplum还提供了Spark链接器,方便使用Spark的用户处理库内数据Spark 代码中引用 Greenplum 数据源。Spark 和 Greenplum 都是多节点并行引擎,通过网络高速并行传输数据。从Greenplum直接加载数据到Spark进行处理,处理之后,将结果集从Spark写入Greenplum以实现数据持久化,无需将数据导出和复制到位于 Greenplum 之外的文件。
下面给大家介绍下Greenplum的云战略。我们的目标是使客户可以在任意适合的环境部署 Greenplum,来提供我们的数据分析服务。目前 Greenplum 支持bare-metal,私有云和公有云的部署,后面我们会深度基于VMware的基础设施,提供更高效实用的方案。
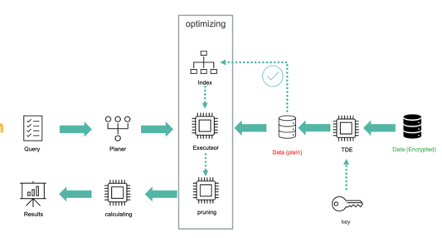
云上的部署更能解决很多在实体机部署中的种种痛点。在云上环境,我们离不开数据的安全性。因此我们正在做透明加密这个新特性来做到:
- 防止数据中心操作员访问磁盘上的数据,
- 防止单个密钥丢失危及所有数据
在实现上,我们将提供
- 磁盘上的表文件、系统文件的加密
- 主密钥将存储在外部 KMS 服务器上。
- 对象密钥将存储在 GPDB Master 上
- 多级密钥层次结构
- 支持密钥轮换
(以最终发布为准)
云环境的资源和查询的管理监控分析也是很重要的,在扩展组件Greenplum Comman Center的新特性中,将添加更丰富的资源和查询管理监控的新特性。
我们正在与VMware的VSphere进行深度的结合,提供基于OVA的部署方案。来实现自动部署,减少运维。使得部署升级Greenplum更加的安全便捷。
作为一款开源产品,Greenplum的开源版可以供大家免费使用、学习和了解其设计思路以及功能实现的具体细节,并对它进行二次开发。欢迎大家参与到我们的社区来。

