4月17日,我们举行了《Greenplum内核揭秘》系列直播的第一场《架构解读》。在本次活动中,来自Greenplum全球总监杨瑜介绍了一些包括数据库、数据库管理系统、关系型数据库、关系模型等基本概念;详细解读了Greenplum的整体架构、存储管理、索引、查询执行、事务与日志等内容;直播室里气氛热烈,大家都纷纷表示,此次活动演讲内容干货满满,收获多多。没有参加活动的小伙伴也不要气馁,这篇文章帮你牢固掌握本次直播的所有要点。
很高兴为大家直播《Greenplum内核揭秘》系列的第一场。本系列一共有十场直播,会对Greenplum的不同模块深入讲解。今天我将为大家详细解读Greenplum架构。在讲Greenplum的架构之前,我们先来看看数据库管理系统。
数据库管理系统
数据库管理系统的诞生是基于对数据有效管理和查询的需求。在没有数据库管理系统之前,采用的是基于文件的存储。在以下的例子中,两张表分别代表了酒吧的信息和不同酒吧的销售信息,如果将这两类信息分别采用文件存储,为了统计每个店的啤酒销售额度,我们可以用两个for循环来完成。
这个操作虽然代码很短,但算法复杂性很高。除了算法的效率很低,用文件存储还有其他问题:
- 数据的一致性:例如销售记录中对应的酒吧在酒吧文件里并没有出现、导致无效数据存在;
- 对记录的修改:特别是字符串类型的变长属性的修改变得不容易维护;
- 查询的复杂、冗余和低效:每次查询都需要写遍历程序,遍历程序运行时间和空间负责度高;
- 对技术要求很高
- 除了上述提到的情况外,还有很多其它问题

于是数据库管理系统应运而生。很多人都会用数据库来简称数据库管理系统,事实上,数据库和数据库管理系统是两个概念。数据库指的是一堆有效组织的,相关联的,便于高效存储和查询的数据的集合。而数据库管理系统是一种软件,用于管理数据库里的数据,除了能提供基本的增删改接口,还能提供高效的查询语言。针对数据的建模,会有不同的建模方法,包括基于Document,对象,KV等,而基于关系模型作为底层数据模型的数据库管理系统就被称为关系型数据库管理系统,Greenplum也是一种关系型数据库管理系统,简称关系型数据库。

关系型数据库有几个重要关注的技术点,例如数据是如何定义和存储的,如何保证数据的完整性,包括数据的一致性,事务和并发的控制等,如何支持用户易于使用的查询接口。

Greenplum整体架构
接下来我们看看Greenplum是如何解决上述问题的。首先我们来看看Greenplum的整体架构。Greenplum是基于Postgres的开源分布式数据库,从拓扑结构上看,它是单机Postgres组成的数据库集群。但不限于此,Greenplum对外提供统一的数据库接口,让使用者感觉就在使用单机数据库一样,并且,Greenplum对集群处理做了大量优化。

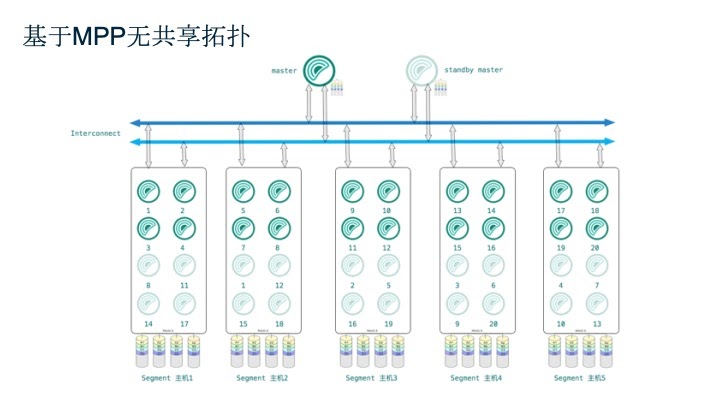
从物理拓扑结构来说,Greenplum数据库是典型的Master-Segment结构,一个Greenplum集群通常是由一个Master节点、一个Standby节点和多个Segment节点组成,节点之间通过高速网络互连。Master是整个数据库的入口,终端用户连接Master执行查询,Standby Master会为Master提供高可用支持。Segment节点是工作节点,数据都存在Segment上,Mirror Segment会为Segment提供高可用支持。
下图中的每个方框就是一个物理机器,为了能获取物理机器最好的性能,一个节点可以灵活部署多个Segment进程。在查询过程中,当Master节点接收到用户发起的查询语句时,会进行查询编译、查询优化等操作,生成并行查询计划,并分发到Segment节点执行。Segment执行完毕,会将数据发回Master节点,最终呈现给用户。
了解了Greenplum的架构,我们再来看看在Greenplum上,数据是如何存储的。在Greenplum上,每个物理机器上会对应多个磁盘,每个磁盘上会挂载物理磁盘,每个磁盘上会存有多个数据分片。Greenplum上数据的组织会采取如下策略
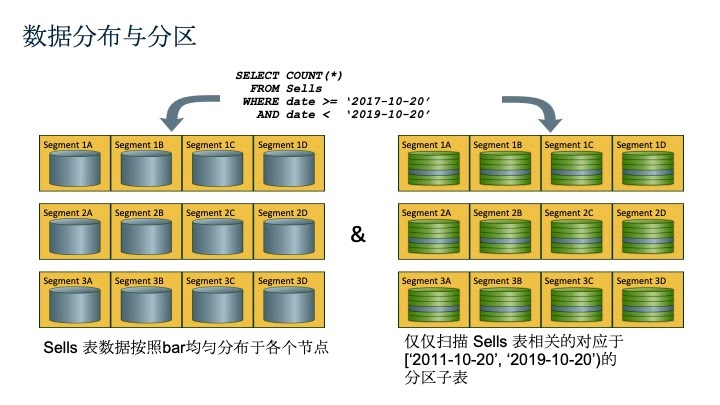
- 首先,数据会按照设定的分布策略均匀的分布在各个Segment上。Greenplum支持的分布策略包括哈希分布、随机分布和Greenplum6版本中新增加的复制分布。这个操作我们称为数据的分片
- 然后,对于每个节点上的数据,可以再次通过数据分区将该节点上的数据划分为更小的子集合,从而在查询时代价更小。这个操作我们称为数据的分区
我们用上面的“酒吧”的例子来进行讲解,左边是数据的分片处理,Sells表按照某个列(“bar”)来进行分片,分到不同的节点上。每个节点再按照“date”来分区,分到小子表里,通过图中的查询语句,只需要扫描图中蓝色的部分就可以完成查询任务,大大减少数据的扫描量。
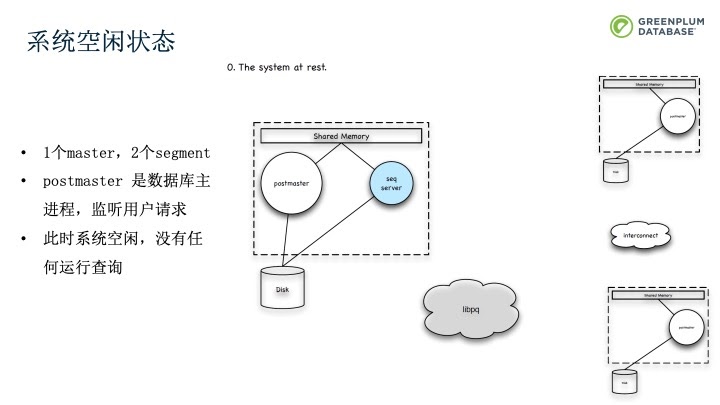
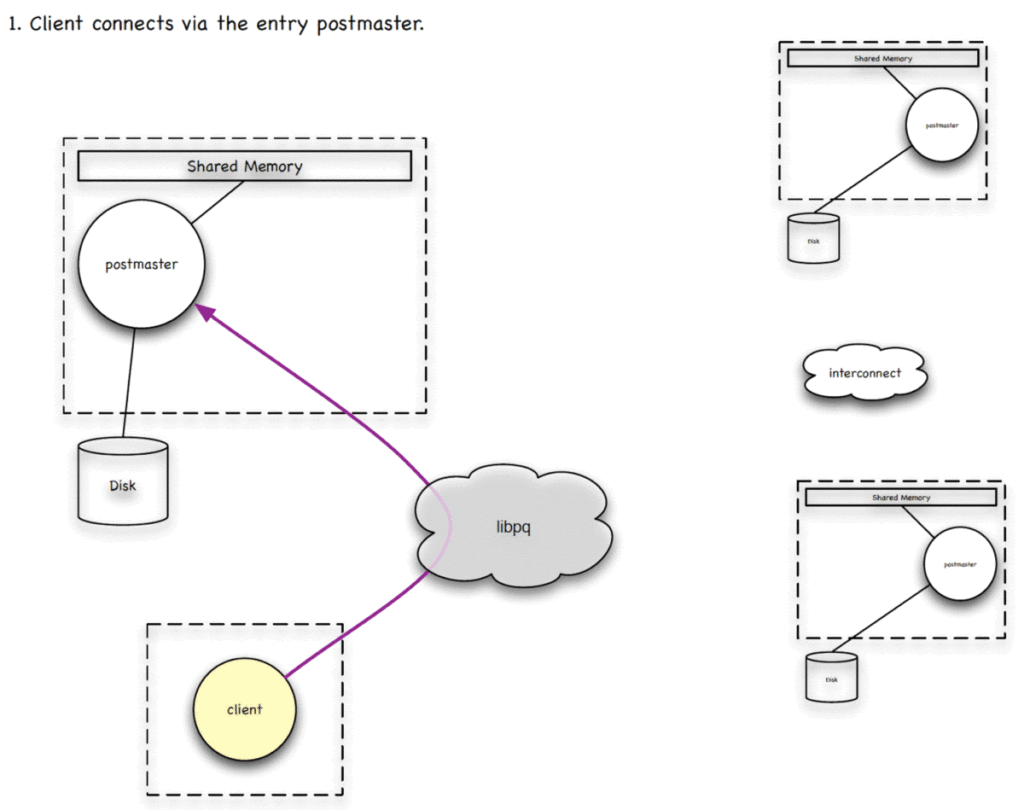
接着,我们来看看Greenplum的服务流程,下面的例子中,左边是一个Master节点,右边是两个Segment节点。前面提到从拓扑结构来看,Greenplum是由单机Postgres组成的数据库集群,例子中总共有三个Postgres进程。当客户端有请求时,会通过Postgres的libpq协议链接到Greenplum的Master节点。Master上的postmaster进程监听到连接请求后,会创建一个子进程(QD)用于处理该客户端所有的查询请求。QD和原来的master之间会通过共享内存来进行数据的共享。
然后是QD与各个Segment间建立连接。QD可以看作为每个Segment的客户端,QD进程会发连接请求到所有的Segment节点上,并通过libpq协议和每个Segment建立连接请求,Segment上的postmaster进程监听到QD的连接请求后,也会创建一个子进程(QE)以处理后续的查询请求。QD的全称是Query Dispatcher,是一个分发器,而QE是Query Executer,是处理查询的。所有的QD和QE进程会共同来完成客户端发送的查询请求。
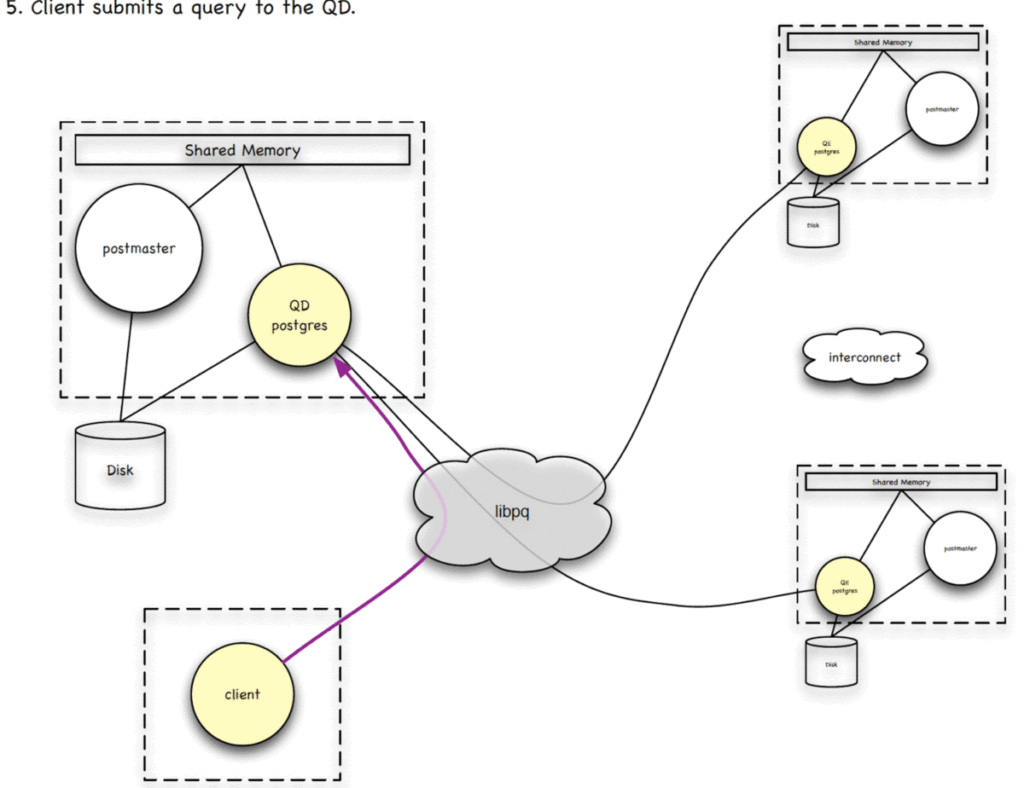
准备工作做好后,查询是怎么进行的呢?客户端将查询请求发给Master上的QD进程后,QD进程会对收到的查询进行处理,包括解析原始查询语句、优化器生成分布式查询计划等,并通过libpq协议发送给各个Segment上的QE进程。QD和每个Segment上的QEs会建立interconnect连接。需要注意的是,libpq主要用于控制命令和结果返回,而 Interconnect用于内部数据通信。
每个QE进程会执行分配给它的查询子任务,并将结果返回给QD,QE之间也是是通过Interconnect交互数据,没有libpq链接。QE和QD之间通过Libpq协议进行状态更新和管理,包括错误处理等。最终QD会将收集到的查询结果进行汇总,并通过libpq返回给客户端。
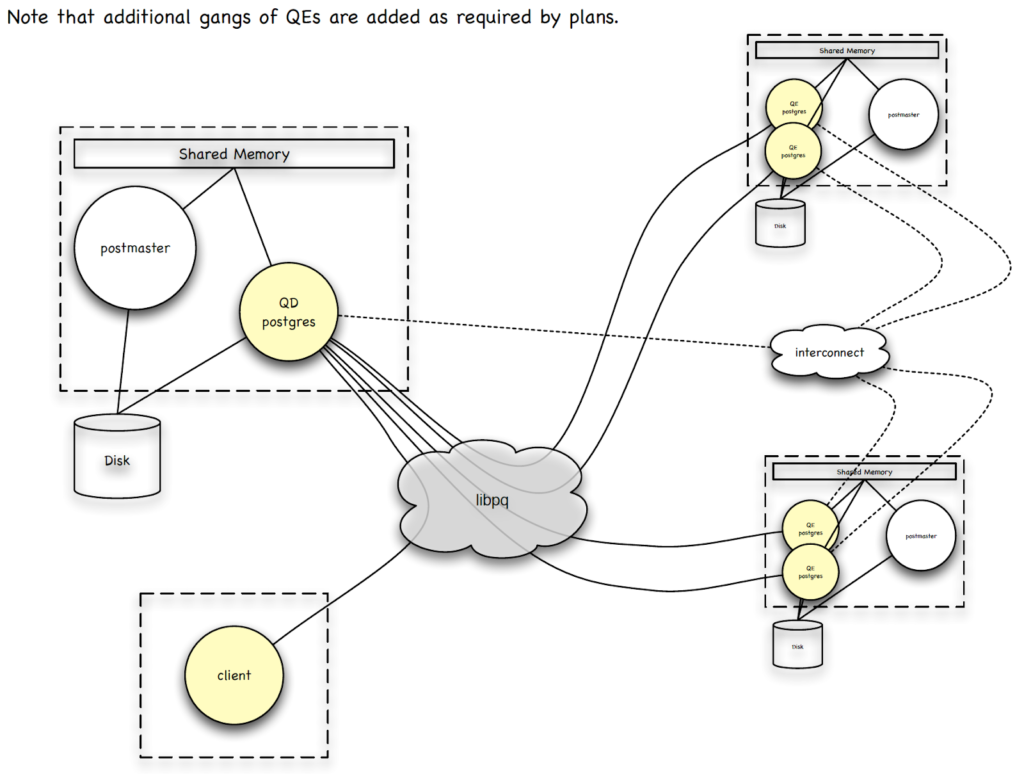
在执行比较复杂的查询时,比如先select两个表然后再将两个表做JOIN运算,此时整个查询就被分为了两层,第一层数据读取出来,再进行中间的数据交换,第二层会将相同的链接键的值放在一起进行JOIN,最后再将JOIN的结果返回给客户端。PostgreSQL是进程模型,为每个查询创建单个进程进行处理。为了提高CPU利用率,Greenplum实现了Segment内算子之间的查询并行化。用户查询在单个Segment上可以有多个QE,QE之间通过Interconnect交互数据。
存储管理
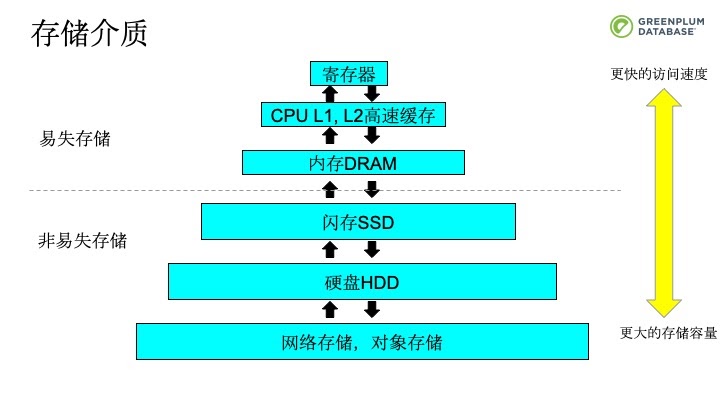
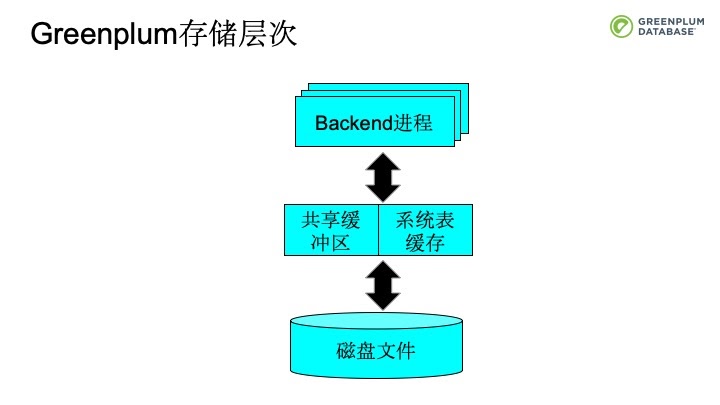
讲完了Greenplum的架构,我们再来看看Greenplum的主要功能模块。首先我们来看看Greenplum的存储管理。教科书里经常会提到存储金字塔。在金字塔分布中,越往上走容量越小,但越来越快,越往下走,容量越大,但越来越慢。内存以上的存储是易失存储,很快但容易丢失数据,这就是易失存储。而非易失存储相对慢,但是不易丢失数据。
大家在大学的操作系统课程中可能会学到,在写程序的时候,我们会通过cache或者buffer来访问文件。 Greenplum的进程中通过共享缓冲区域来作为中间的内存buffer。Beckend进程会和中间这一层直接打交道。而共享内存中的buffer会和磁盘文件做交换。
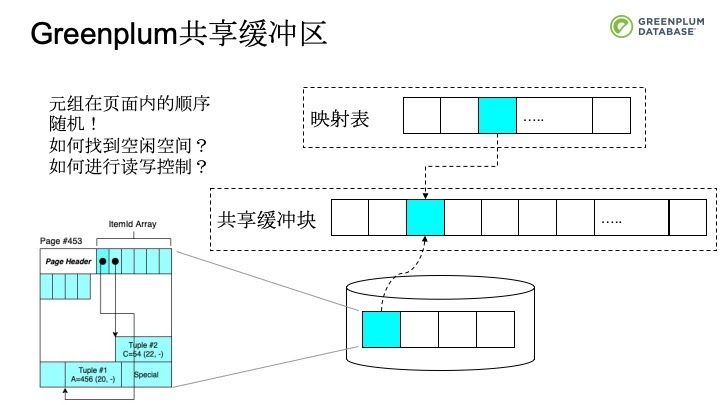
那么在共享缓冲区里会发生什么呢?Greenplum是按块来组织数据,图中的虚线方块就是共享内存区。映射表会通过块号去找到共享缓冲块对应的块。如果发现内容是无效的会通过下层的文件操作将数据加载到共享缓冲块中。如果有效,就会直接读取。
Greenplum会将变长数据在每个文件块内从后往前存储,在页头存的是定长的指针,指向了块尾部真正数据的块内偏移。通过指针可以快速的查找第n个数据。中间区域是空闲区域,数据会从后往前的生长,Item Id会从前往后生长,中间区域会保留连续的空间减少碎片。
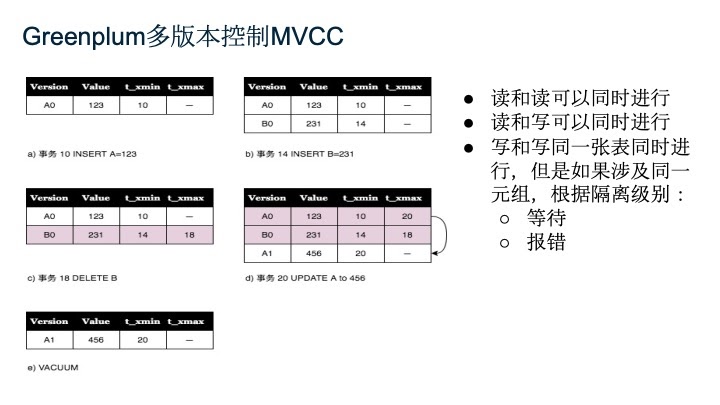
对于Greenplum,读和读是可以同时进行的,读和写也是可以同时进行的。为了让读和写可以同时进行,Greenplum提供了多版本的控制机构MVCC,来提高并发度。当插入数据时,会保存两个隐藏字段:xmin和xmax,分别表示插入事务和删除事务的编号。
在下面的例子里,图(c)对B0数据执行了删除,于是在对于该数据增加了xmax值18。如果是事务17在运行中,由于事务17在事务18之前,因此对于这个操作是看不见的,因此B0值对于事务17仍然可见,事务17不会认为数据已经被删除。而对于事务19来说,B0就已经被删除了。而UPDATE会拆成两个操作:DELETE和INSERT。例如例子中的图(e)。而如果写和写同一个表中同时进行,并且涉及同一元组,就会根据隔离级别进行处理。当被删除的元组对于当前所有的运行事务都不可见了,VACUUM会回收磁盘空间。
索引
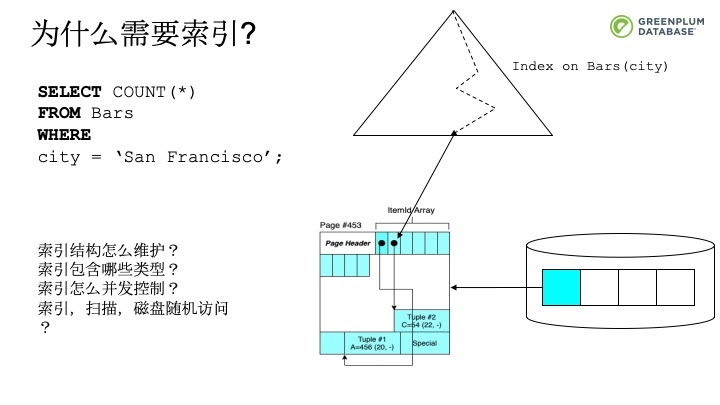
通过索引可以加快元组的读写。索引通过值来找到元组存储的物理位置,从该位置而将元组读出来。比如下面的例子中,索引中记录了city为‘San Francisco’元组位于第453个文件块的第2个元组。跟扫描相比,索引并不是每次都比顺序扫描要快,比如,对于性别建立索引没有多少意义,因为几乎一半的数据都会被扫描到。所以,什么时候采用顺序扫描,什么时候采用索引,这是查询优化器需要替我们做的事情。另外,索引结构如何维护?索引有哪些类型?如何进行并发控制?索引是不是一定比扫描好?这些内容,我们会在《内核系列直播》中的索引专题中和大家分享,欢迎关注。
查询执行
现在,对于元组的增删查改都可以支持了,但这远远不够,为了方便用户的使用和提供更为强大好用的功能,Greenplum提供了执行引擎。在执行查询时,SQL语句经过解析器,会将字符串的SQL语句解析成结构化的树,通过优化器做出最有效的执行计划,并有执行器执行生成查询结果。
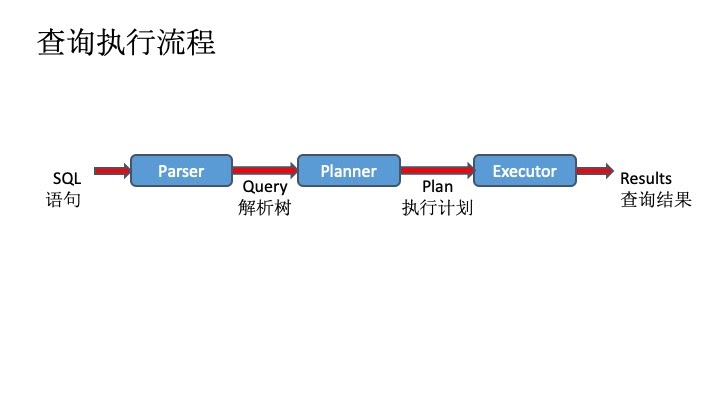
下面的例子中的SQL语句对两个表进行了连接操作。在Greenplum中,执行器是通过迭代器的方式来执行查询计划的,即自顶向下,每次一条元组的方式。每个执行器节点向上提供下一条元组,向下获取下一条元组。一条语句可能存在多条查询计划,比如前面讲到的顺序扫描和索引扫描,查询优化器会足够聪明选择代价最小的执行计划。在例子中,最下面是对两个表的扫描操作,扫描结束后,为了执行Join,需要将Bars表按照名字进行元组的重分布,让具有连接条件的Bars元组和Sells元组能够汇聚在一起。由于Sells已经按照bar分布,所以这里不需要再对Sells做重分布。最后,做完投影运算后,需要把结果汇聚到QD节点,这是由最顶层的Gather Motion来完成的。
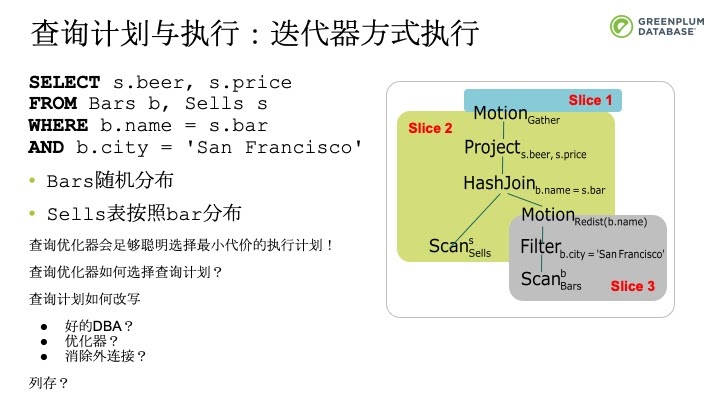
如果采取索引扫描,一个存在的问题是索引执行的元组在文件中,导致磁盘的随机访问。
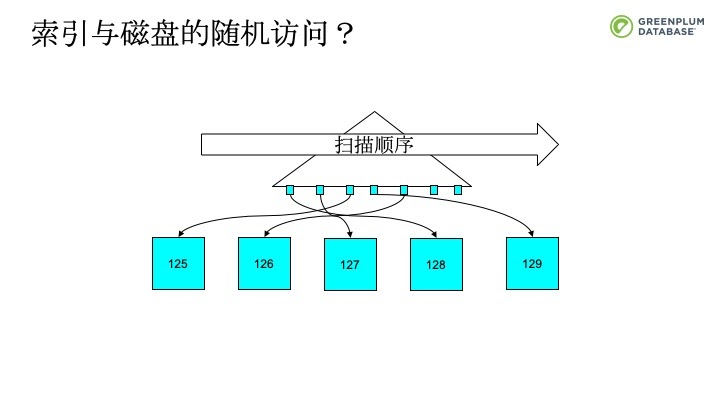
一种解决办法是Greenplum Cluster操作。Cluster操作会按照索引的顺序将文件中的元组重新排序,这样按照索引扫描顺序时,就可以按照顺序的方式访问磁盘。
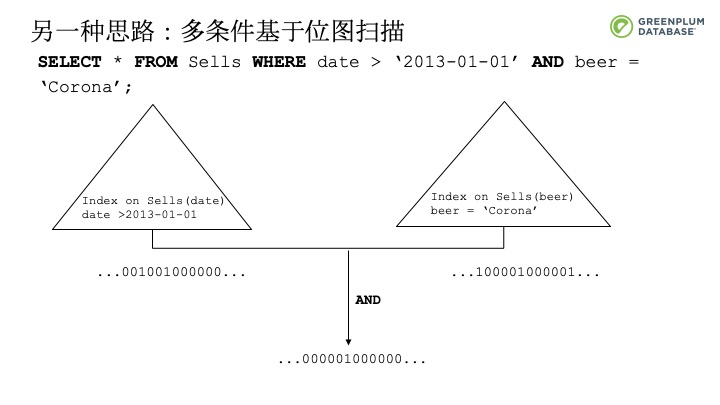
另外一种解决办法,特别是如果是多个条件的情况下,可以基于位图来扫描。在下面的例子中,“date”中有一个索引,“beer”有一个索引,根据查询条件可以获得每个条件的位图信息,位图中记录了哪些元组是否满足查询条件,满足查询条件的元组用位图中的1来表示。两个查询条件各自对应的位图,通过位图AND操作得到最终待扫描位图。基于位图扫描就可以用顺序访问的方式来访问文件。
Greenplum里元组的连接(JOIN)操作主要有三种,第一种是Nested Loop Join,和之前说的文件存储类似,即两个循环叠加起来,将内外的扫描匹配,返回结果。这里可能的一个变种是,内层循环有可能用到索引而不是顺序扫描,让执行效率更好。

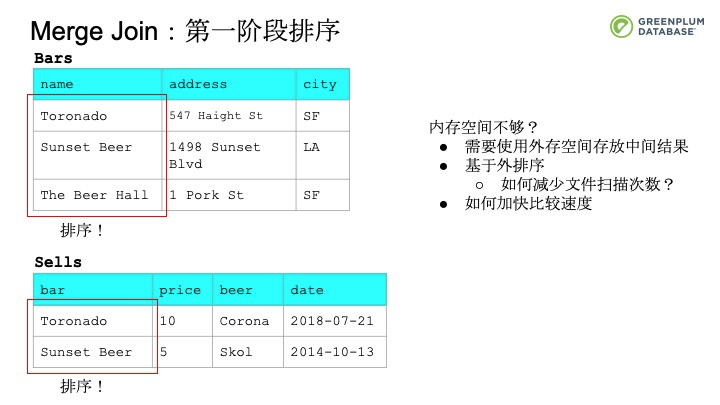
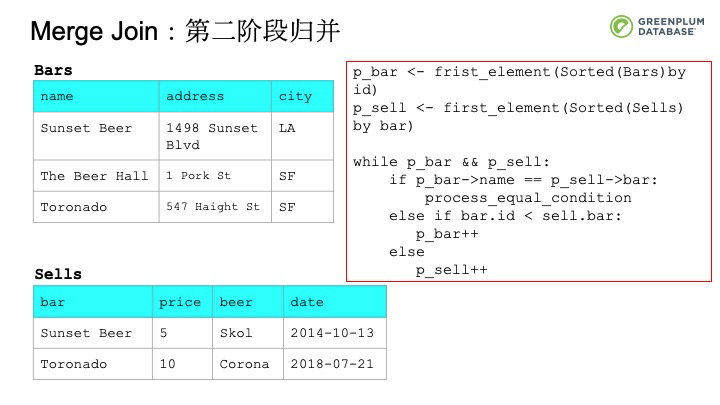
第二种就是Merge Join。Merge Join有两个阶段,第一阶段是根据连接条件将待连接的元组分别排序。然后在第二阶段基于排好序的元组进行归并操作。
第三种方式是Hash Join。在Hash Join时,一般是将一个表作为查找表,另一个小表作成Hash表。Hash表如果足够小,可以放在内存里。每次查找时,对查找表进行扫描,看看当前元组是否在Hash表中有匹配项,有的话,直接返回,没有就跳过。但是存在的问题是,如果Hash表如果过大怎么办?需要将哪些元组存放到外存中?Outter待匹配的元组发现需要匹配的Hash表元组在外存怎么处理?这些问题我们会在5月22日的直播《Greenplum内核揭秘之执行引擎》中为大家揭晓答案。

事务与日志
如果Greenplum在修改文件的过程中进程挂了,如何保证数据的一致性呢?数据库课程中经常提到一个经典问题就是:从A账户向B账户转账100,如果A账户减少了100后系统重启崩溃,此时会不会发生A减了100,而B账户没有加100?Greenplum通过事务来保证操作的原子性。

另外一个问题是事务间的隔离性问题,一个事务处理转账,另外一个事务给银行账户加息(这里是2%的利息)。如果转账事务和加息事务同时进行,如果按照图中的错误序列进行操作就会出现问题,最后会发现少了2块钱!利用事务的隔离性就可以解决这类头疼的问题。这些将会在今年内核直播系列中的《事务专题》中为大家详细讲解。

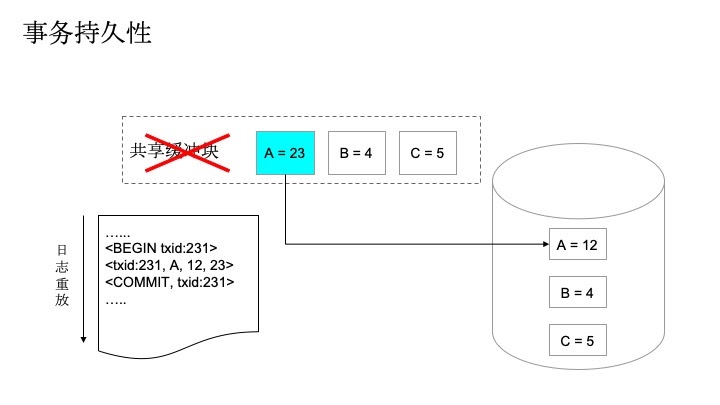
每次写数据时,会先改内存,再写磁盘。在下面的例子中,A先在内存中被修改成了23,提交后,如果系统挂了,此时A的修改就丢了,重启时就会发现A依旧等于12,因为修改还没有来得及写回磁盘。当然,要求每次修改都写磁盘可以防止这类问题发生,但是会有效率问题。Greenplum提供的日志功能就能很好的解决这类问题。日志详细记录了对于数据库的修改流程。日志记录是按照顺序访问的,并且提供了逻辑时间线的概念,效率相对于磁盘的随机访问会高很多。
前面讲到,Greenplum中,数据是存在多个Segment上的,因此要确保在写入数据时,所有Segments上的数据要么都要写入成功,要么都写入不成功。不能接受的是,部分成功,部分不成功的情况,出现数据的不一致状态。这里需要提到一个经典的算法:两阶段提交算法。顾名思义,该算法包含两个阶段,在第一阶段,做prepare,让所有节点投票是否都可以提交,如果所有节点回复为yes时,便会在第二阶段进行提交。否则,只要有一个节点不回复yes,全部节点进行回滚
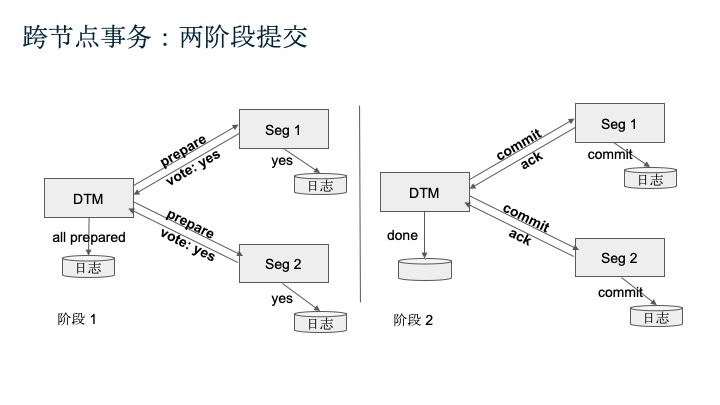
下面看看错误处理的情况:
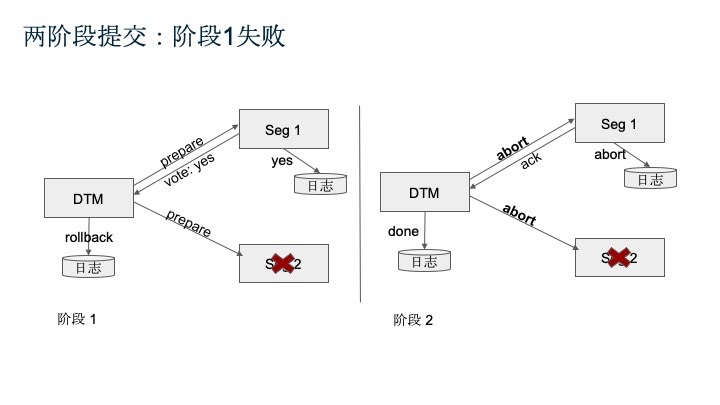
- 第一种情况是错误发生在第一阶段,有节点不能提交,后续操作只需在第二阶段回滚即可。
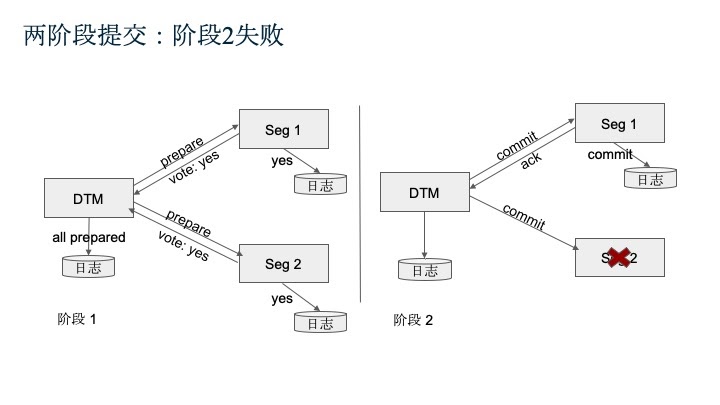
- 如果在第一阶段所有节点都回复了Yes,但是第二阶段出现问题,此时DTM管理器就会对失败的节点进行继续提交,直到成功。所有的提交信息都会被DTM存入日志,通过这些信息可以恢复出事务的状态信息,以便找出下一步需要做什么。
如果大家对Greenplum感兴趣,可以从下载Greenplum源代码开始,走出Contributor的第一步。从Github中可以下载Greenplum,下载后先编译源码,编译过程中把Debug信息打开,优化关掉。
源码下到本地后,源码的检索查询我本人用的是cscope进行,大家可以根据自己的情况而定,选择自己喜欢的源代码分析阅读工具。源代码中比较重要的目录结构如下图所示,大家可以在对应后面的直播课程章节中进行查看。