2022年年初,Greenplum 7版本将正式GA(具体时间请以官方信息为准)。今年,Greenplum中文社区将和墨天轮社区合作,邀请原厂专家,开展《Greenplum 7 新版本大剧透》系列直播。第一场活动中,Greenplum原厂研发总监杨瑜介绍了Greenplum 7引入的多个激动人心的新特性和最新开发进展,包括各个组件和内核部分,让大家提前尝鲜。小编已经帮大家把精华内容整理成了文章供大家学习回顾,因为内容过长,内容将被分为“组件篇”和“内核篇”两个部分,内核篇将于下周通过公众号推送,欢迎关注。
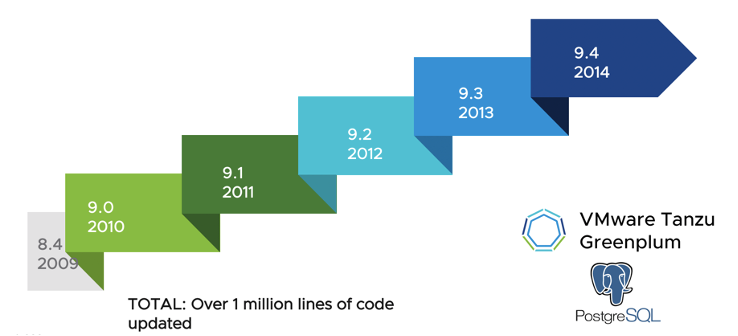
Greenplum7预计于明年初发布。在于2年前发布Greenplum 6版本中,Greenplum在速度、稳定性、和功能上都做了很大的提升。Greenplum 6版本中,内核由Greenplum 5版本的8.4升级到了PostgreSQL 9.4,做了6个大版本的升级,有超过1百万行代码的更新。而Greenplum 7版本将基于PostgreSQL 12,同样也经过了5个大版本的升级,Greenplum正紧跟PostgreSQL的升级步伐。
除了内核,6版本中我们也引入了多个特性,例如复制表、物化视图、CTE的支持等。此外,针对短查询以及和大查询在一起的混合负载,Greenplum也做了大量的优化。
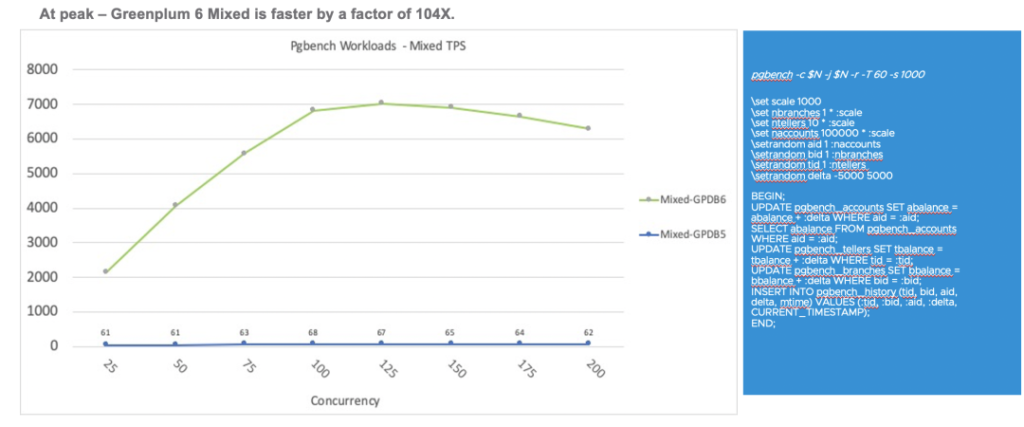
下图是一个5版本和6版本的对比测试结果。在5版本里,随着节点并发数的增加, Mixed TPS不会有明显的提升。在6版本里,有了近104倍的提升。当然,在7版本中,混合负载将得到更大的提升。
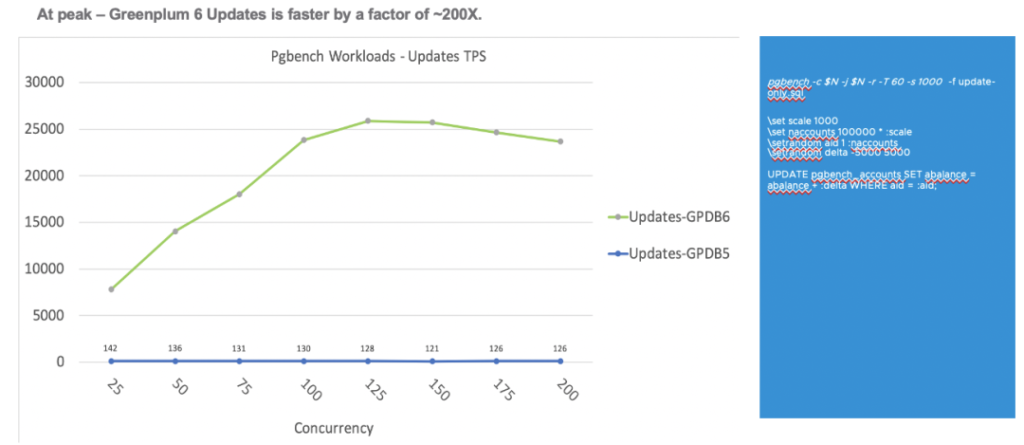
下图是6版本中,关于更新(UPDATE)操作的测试结果,相对于5版本也有接近200倍的提升。
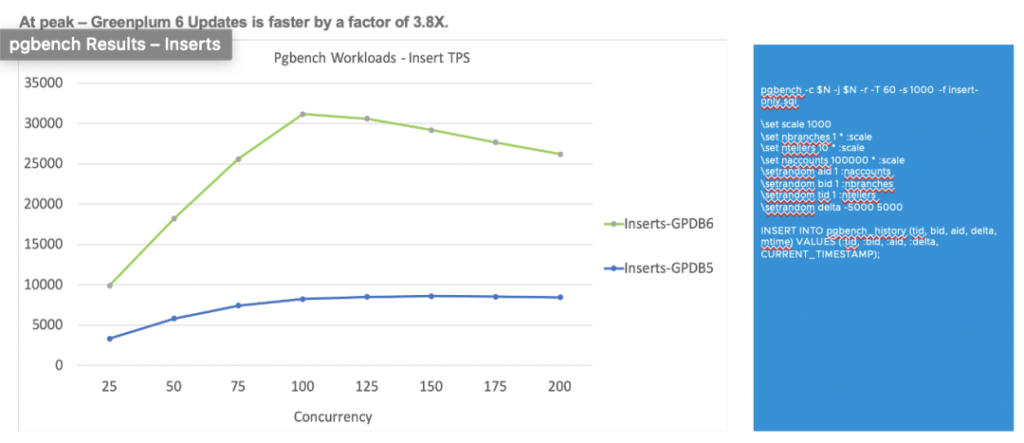
下图的插入(INSERT)操作测试中,6版本相对于5版本得到了3.8倍的提升。
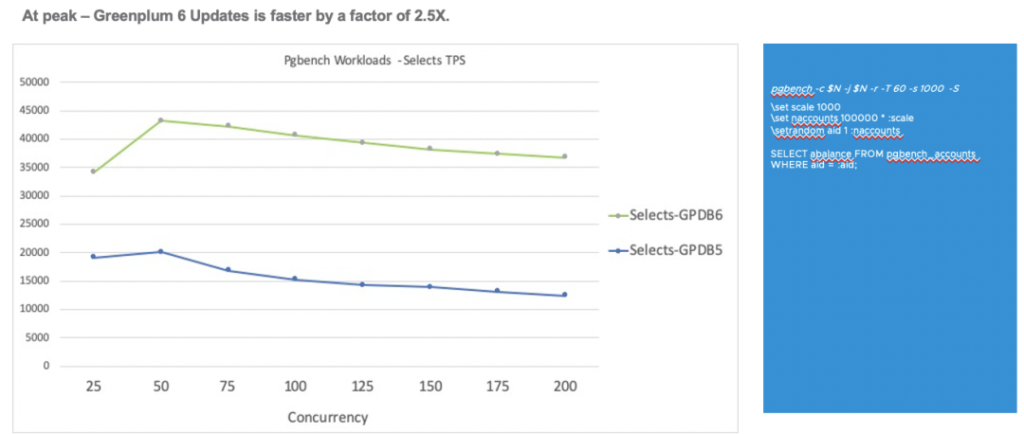
下图是一个只读查询(SELECT)的测试结果显示,6版本相对于5版本提升了约2.5倍。
6版本中,资源管控和内核升级为性能提升带来了很大的红利。随着7版本中内核升级至PostgreSQL 12,我们相信也会给Greenplum的性能带来更大的提升。
Greenplum Command Center
回顾完6版本中的相关内容,我们来聊一下,Greenplum商业版组件和内核server上我们都正在做或计划做哪些工作。
01 Pause
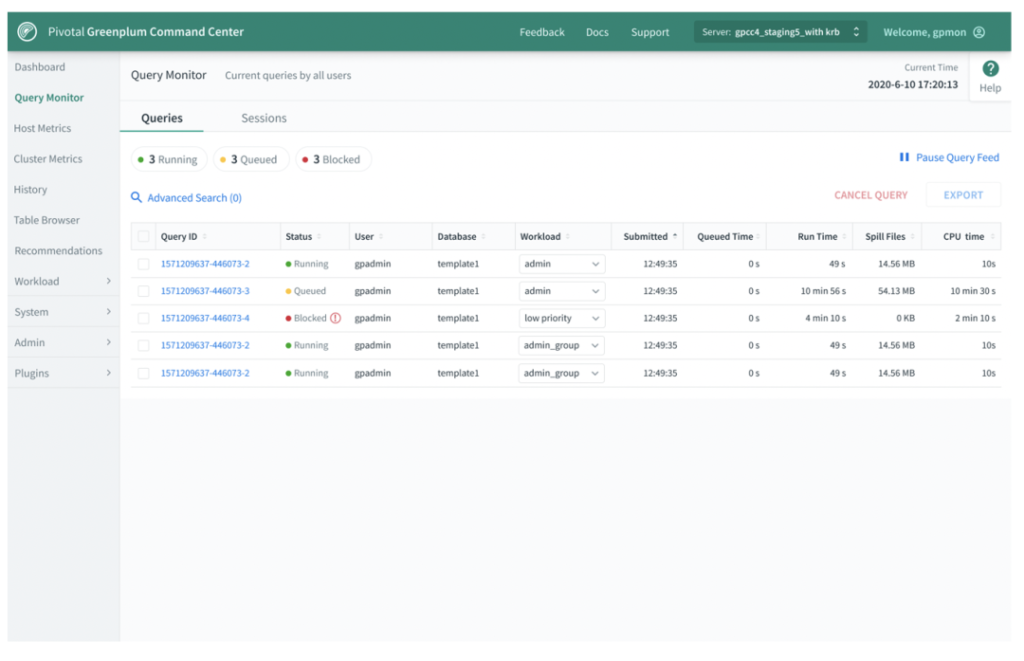
GPCC设计了众多非常贴心的功能。在正常情况下,GPCC的展示页面会展示所有当前执行的query。当执行的query非常多时,展示页面可能会不断刷新,执行query的展示结果在不断刷新。
如果用户想仔细查看页面中的信息细节时,会希望页面暂时刷新。此时,用户便可以点击“Pause Query Feed”按钮。一旦点击按钮,页面可以认为是处于一个相对静止的状态。此时,用户便可以浏览页面细节。一旦恢复,页面便可以继续执行query。
02 Firter
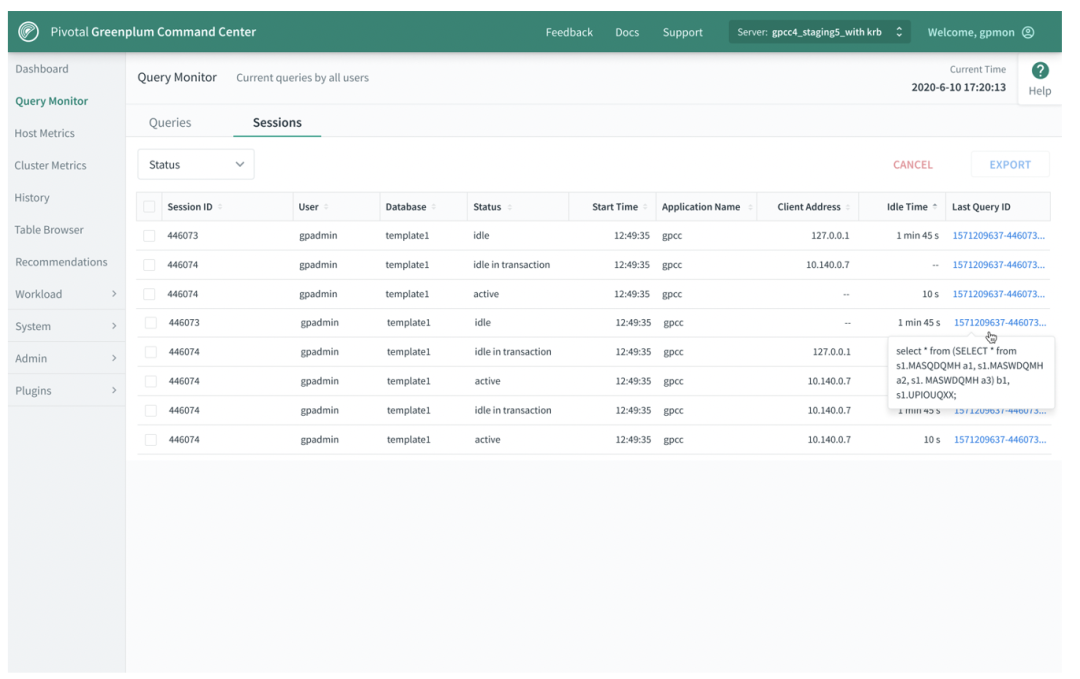
除了Pause功能,GPCC还将提供一个过滤(filter)的功能。用户可以在高级搜索里指定 query,GPCC可以根据query的segment等多个信息进行过滤。当把鼠标放到Query ID上时,同时还会显示一个浮动窗口,更友好的展示Query的详细信息。用户在使用时将更加方便。
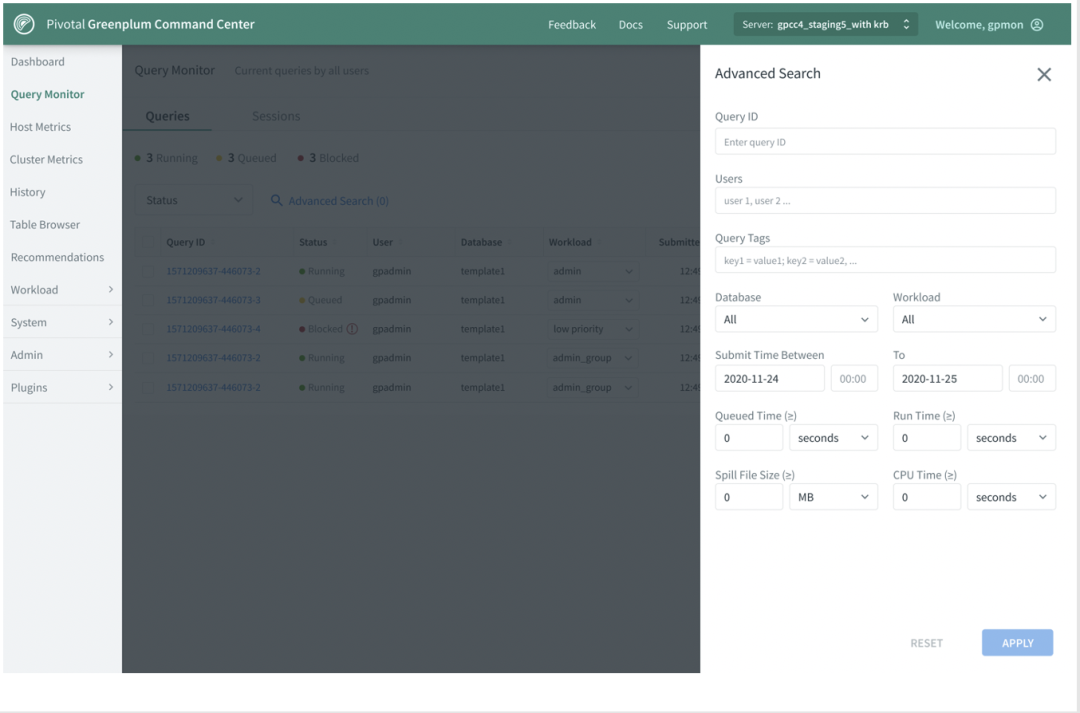
比如下面的例子中,用户可以根据查询提交起止时间进行过滤选择。例子中做的过滤显示了2020年11月24号这个时间窗口内提交的查询。除此之外,用户还可以指定其他过滤条件,比如数据库、用户、Query ID等。
03 Session View
有时,会存在某些session很长时间闲置的情况。这种长时间闲置的会话会继续占用系统资源,包括连接数,进程资源、内存等。我们希望GPCC能够更加智能的管理这类session的生命周期。
针对这个需求,用户可以制定一个规则。通过Workload Manager,可以创建规则,规定GPCC在超过某个规定时间后,自动将session 关闭。创建规则后,后台可以进行检查,一旦发现query idle时间过长,闲置的情况,就会自动将资源回收。这样便不再需要人为的干预,自动进行资源的释放。
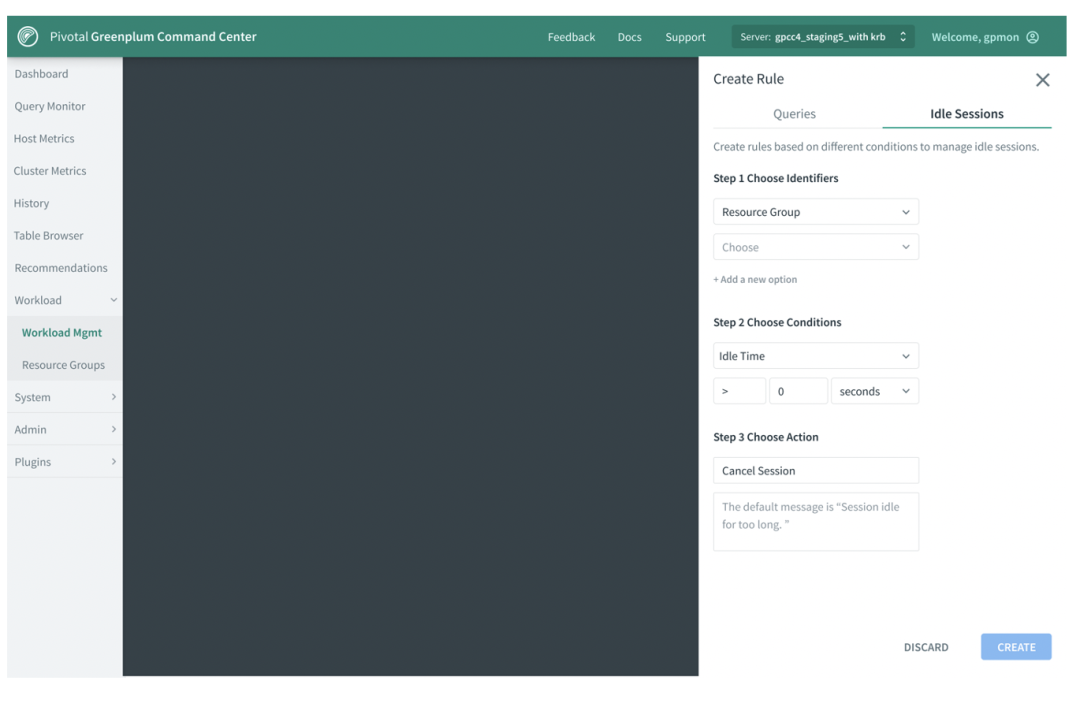
其中Query Tags是Workload Mgmt的功能,在Workload Mgmt中,可以在query上定义一个text,即一个标签。通过某个特定标签的过滤,用户可以选择展示标签对应的内容。
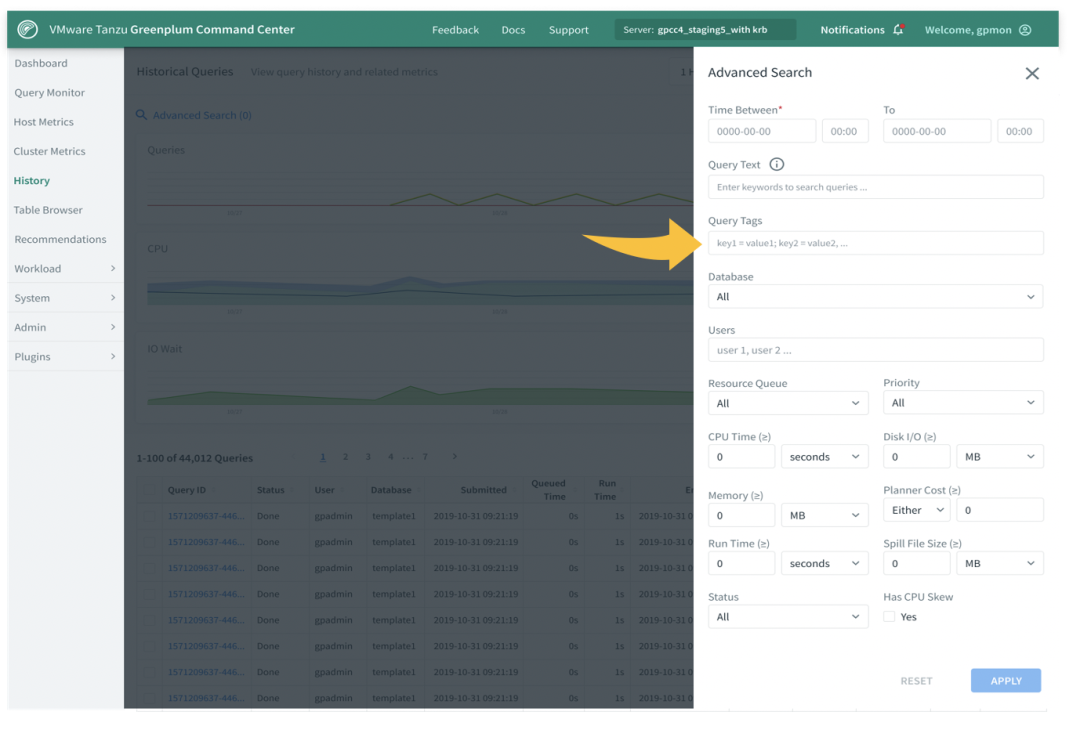
下图的例子中,通过query tag搜索便可以找到key1=value1;key2=value2对应的query,并将query的实时的动态展示出来。
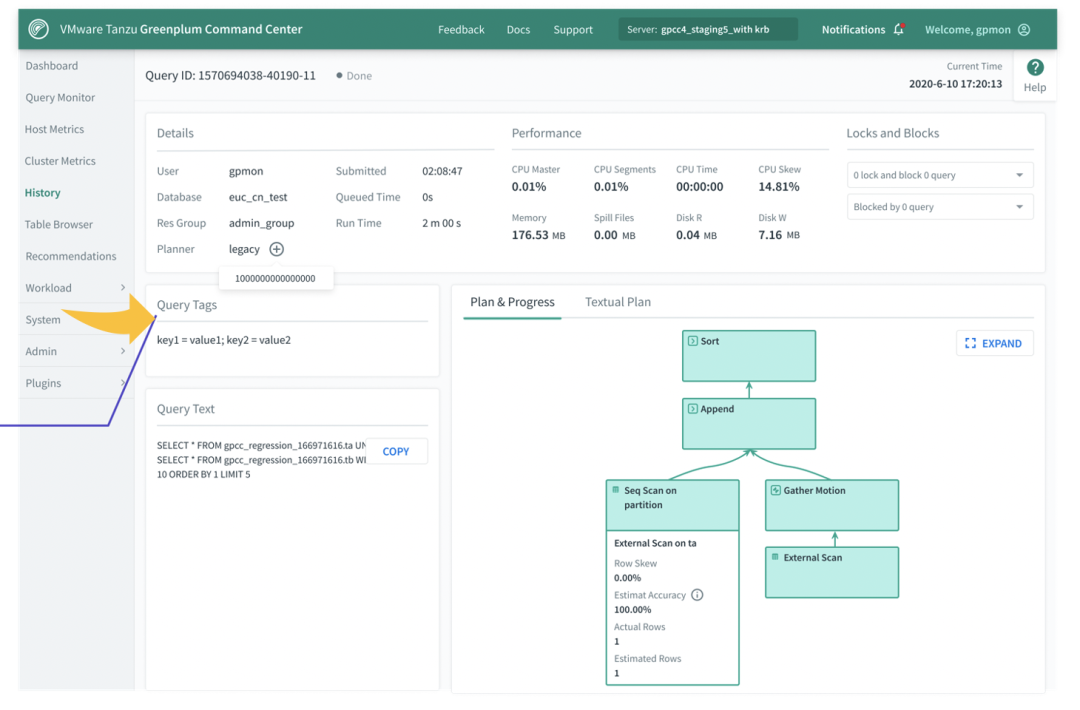
除了这里详细描述的功能,GPCC后面还会设计更多更加智能的功能,例如分区键的自动辅助检查,以及分布键设置的不合适,导致的查询性能问题和数据倾斜。GPCC后续会通过对查询结果的分析,发现某些键值设置不当,会自动为用户做键值以及分区的推荐。
此外,还有一些用户提到在使用资源组时,在展示用户资源消耗时,例如CPU、内存、磁盘等,能否根据分组的方式来展示,让系统管理员看起来能够一目了然,更加便捷的了解每个资源组的资源消耗,使用量等情况。
Greenplum GPSS
我们再来看一下GPSS。GPSS组件主要可以帮助用户进行数据的加载(LOAD)和卸载(UNLOAD)。
01 和Prometheus的深度集成
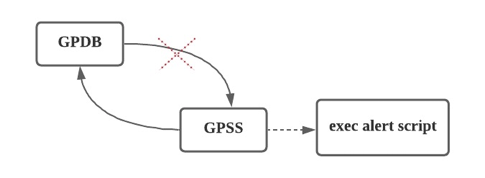
GPSS在Greenplum 7里很重要的一个功能是,提供和Prometheus的深度集成。在GPSS里,我们会利用JOB把外部数据源导入到Greenplum里,或把Greenplum的数据卸载到外部数据中。

JOB的数量通常非常多,用户会想知道在执行query的时候各个JOB的状态,有没有挂掉,执行进度和已加载数据量,以及一些资源指标,例如加载中消耗的CPU,内存,磁盘占用等,这些都是可以通过Prometheus来展现。同时,可以通过脚本来进行控制异常触发时的行为,比如加载中如果出现JOB异常,可以发邮件给系统管理员。
02 对不同加载方式和数据格式的支持
数据加载可以配置不同的加载方式和数据格式,可以执行流式或者跑批的方式,也可以支持各种主流的数据格式。
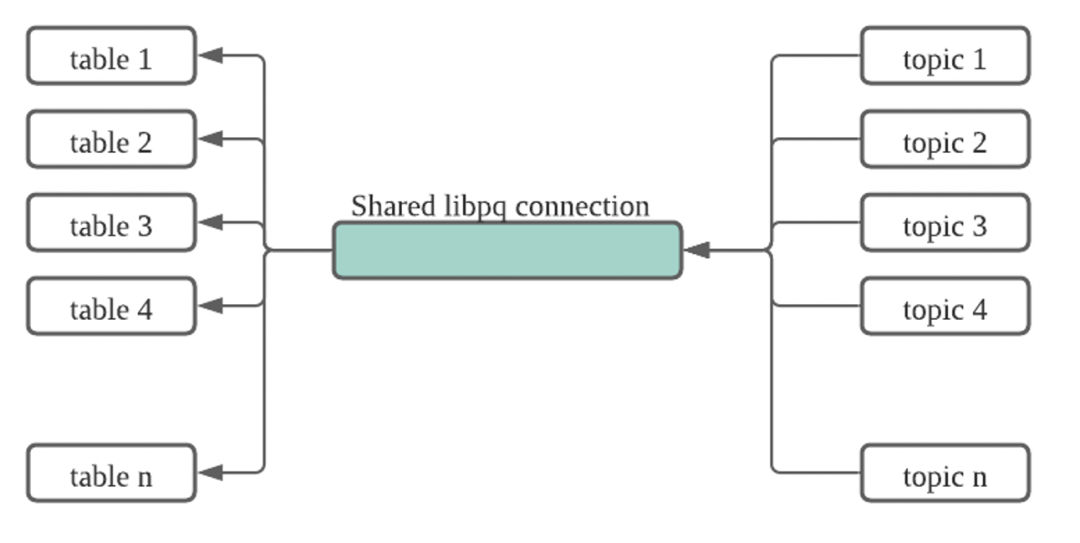
03 共享Session
在之前的GPSS版本中,对每一次加载JOB,资源管理通常不够细致。每次加载JOB都会创建一个对GPDB的连接,如果表格较多,连接数就会非常大。Greenplum的连接数是有限的。对于Greenplum的集群来说,可能一边在做加载,同时需要跑一些定期的作业,不能因为加载影响Greenplum的作业运行。在新的版本的GPSS中,我们希望做到连接能够共享,用池化的方式来节省连接资源。
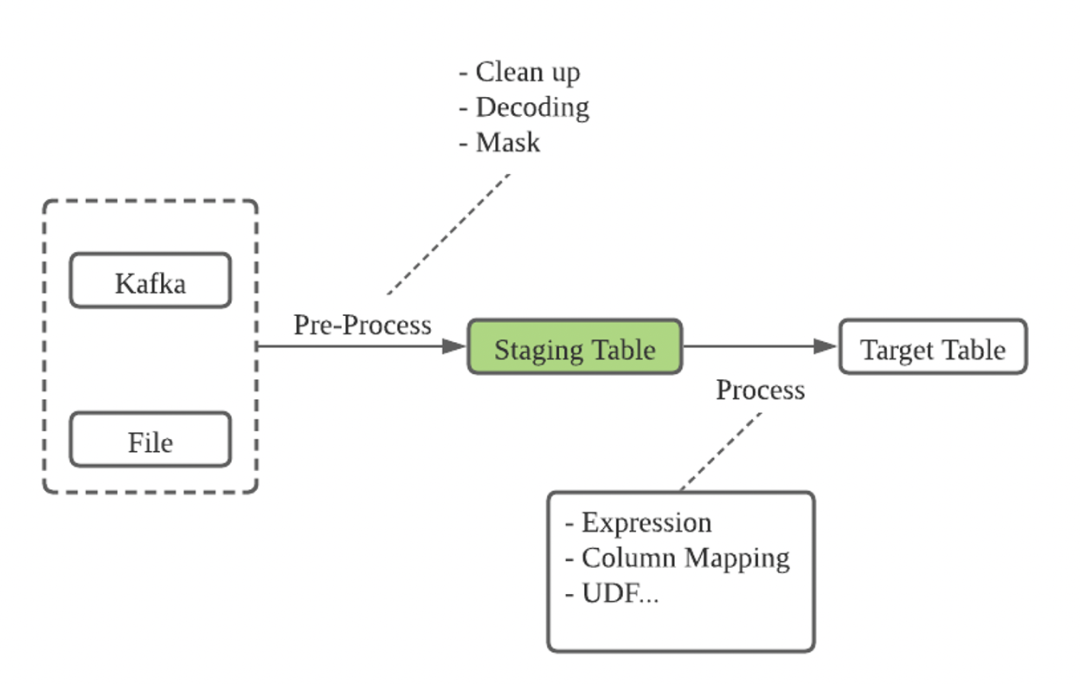
04 预处理
正在做的功能是希望在GPSS里做到更多的预处理。GPSS会利用staging Table在数据加载进来后,做一些深度清洗和预处理,或者是解码decoding,目标数据过滤等工作。GPSS会通过中间表的方式来预存一些中间数据,在中间做一些映射和过滤。不再需要用户先将数据加载到一个表里,再去写一个转换函数完成转换。
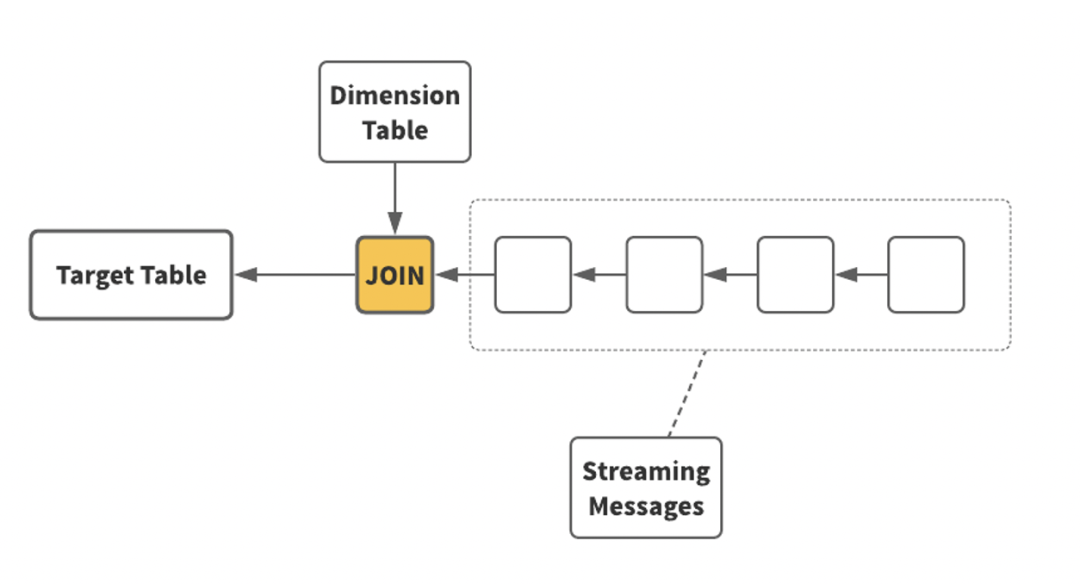
05 和其他维度表的连接
数据加载进来后,通常希望能跟其他维度表进行连接操作。了解GPLOAD的小伙伴可能知道,GPLOAD中没有这类操作,更多的是将数据直接加载到对应表里。在GPSS里,我们希望对数据进行拼接转换后,再加载到目标中,这样会使用户使用起来更加简单。
Greenplum的每个商业组件都在不断迭代,期望给用户带来更加优质的产品体验。文章的下半节,我们将为大家介绍Greenplum 7内核的功能更新,欢迎关注!

