GPCOPY是新一代的支持Greenplum集群之间快速高效传输数据的工具。作为Greenplum集群数据传输的官方首选配套工具,GPCOPY除了具有高速稳定易用的特点外,还支持不同版本Greenplum集群之间的传输(当然支持同版本之间的传输)。GPCOPY支持从GP4.3.x到GP 5.x、GP5.x到GP6.x、甚至GP4.3.x到GP6.x的数据传输。它也同时支持同等规模集群和不等规模集群之间的传输。另外GPCOPY还支持数据的校验,支持事务,增加了数据传输的可靠性。GPCOPY目前还没有开源,最新版本2.1.0在3月9日正式发布上线,做了很多方面的提升,可以在官网https://network.pivotal.io/products/gpdb-data-copy/下载到。
一、新功能
1. 支持有外键的表、view以及有继承关系的表
GPCOPY是以表为单位从源数据库中把表的定义及表中数据复制到目标数据库中。
首先GPCOPY拷贝表是支持事务的,如果再拷贝过程中出错则回滚。例如如果目标数据库中不存在要拷贝的表,GPCOPY首先会创建目标表,然后把源表的数据拷贝到目标表,如果在拷贝数据的过程中由于某种原因出错了,则整个表的拷贝会回滚,被创建的目标表不会出现在目标数据库中。
其次,GPCOPY支持并行拷贝多个表。使用–jobs可以指定最多同时拷贝多少个表。–jobs的最大值是由运行GPCOPY机器的性能、源数据库的性能、目标数据库的性能等多个因素共同决定的。并行拷贝表使GPCOPY拥有出色的性能,但是数据库中有些表并不是相互独立存在的,比如有外键的表、view、有继承关系的表都需要依赖其它的表,此时并行拷贝表就会出现问题。在GPCOPY 2.1.0版本之前,这个问题一直存在,例如有两个表:
CREATE TABLE t(id INT PRIMARY KEY,name TEXT);
CREATE TABLE ft(item_id INT NOT NULL, foreign_id INT REFERENCES t(id));为什么会出现这个错误?
让我们先来看一下GPCOPY 在目标数据库创建表”ft“的步骤:
1)在源数据库使用pg_dump -t table_name 导出创建表”ft“的SQL。
2) 在目标数据库执行这些SQL语句创建表”ft“。
CREATE TABLE ft (
item_id integer NOT NULL,
foreign_id integer
) DISTRIBUTED BY (item_id);
ALTER TABLE public.ft OWNER TO gpadmin;
--
# Name: ft_foreign_id_fkey; Type: FK CONSTRAINT; Schema: public; # Owner: gpadmin
--
ALTER TABLE ONLY ft
ADD CONSTRAINT ft_foreign_id_fkey FOREIGN KEY (foreign_id) REFERENCES t(id);上面是创建表“ft”的SQL,里面会引用“t”这个表。但是GPCOPY是在目标端并行地、并且在不同事务中创建表“t”和表“ft”,此时表“t”并不存在,因此会出错。
在GPCOPY 2.1.0中,我们通过分析表之间的依赖关系,对于有外键的表、view、以及有继承关系的表,先拷贝他们依赖的表。如果被依赖的表拷贝成功,再拷贝这些表;如果被依赖的表拷贝失败,则这些表不会被拷贝。如上例所示,GPCOPY 2.1.0 会先拷贝表“t”,表“t”拷贝成功后再拷贝表“ft”。对于没有依赖关系的表,我们依旧并行地进行拷贝。
GPCOPY 2.1.0 做到了既能并行拷贝表的DDL和数据,又能处理表之间的依赖的关系。
2. 新增选项 dest-mapping-file
运行gpcopy –help可以看到对该选项的说明:
Use the host to IP map file in case of destination cluster IP auto-resovling fails意思是当GPCOPY遇到无法解析HOSTNAME的时候,可以把HOSTNAME对应的IP地址配置到一个文件中,通过dest-maping-file把该文件传给GPCOPY。
GPCOPY什么时候需要解析HOSTNAME?需要解析谁的HOSTNAME?
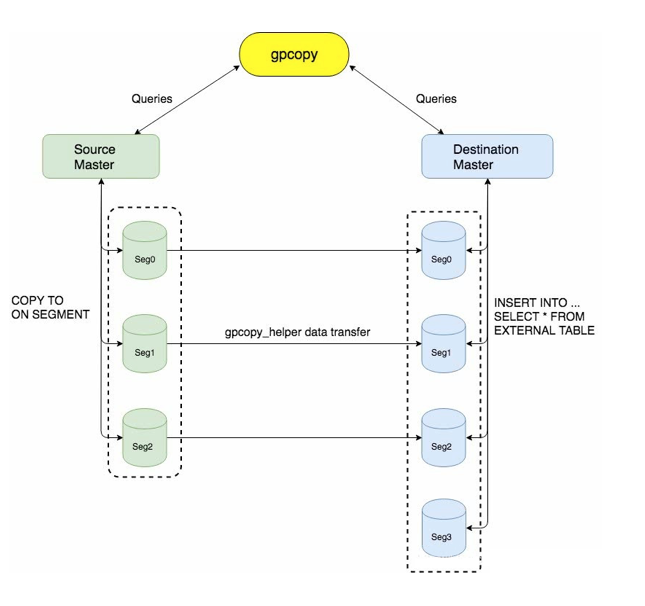
接下来用上图来解释这两个问题。
GPCOPY 在源数据库和目标数据库之间主要是通过segment到segment相互传输数据。源端和目标端的segment往往不在同一个host上,通过gpcopy_helper实现跨机器的数据传输。运行在源端segment上gpcopy_helper负责发送数据,运行在目标端segment上的gpcopy_helper负责接收数据。gpcopy_helper发送数据的时候,需要知道接收数据的gpcopy_helper的地址,即目标segment的IP地址。
2.1.0版本之前GPCOPY 没有dest-mapping-file这个选项,那么它是怎么获取目标端segment IP地址的,以及存在什么问题呢?
首先查询目标数据库中gp_segment_configuration 表,获取segment的HOSTNAME 。源端不能直接使用该HOSTNAME,需要其对应的IP地址。所以GPCOPY会在在目标集群的master上查询该HOSTNAME对应的IP地址(GPCOPY已知目标端master的地址,master知道segment HOSTNAME对应的IP)。但是有时目标端master只配置了segment HOSTNAME对应的私有IP地址, 源数据库和目标数据库并不在一个集群中,导致源端的gpcopy_helper和目标端的gpcopy_helper无法通信。
为解决该问题,GPCOPY 2.1.0 增加了dest-mapping-file 选项,当GPCOPY通过以上方法无法获取segment公有IP的时候,用户可以通过配置文件设置;或者当目标端的segment没有public IP的时候,可以设置一个用来做数据转发的IP地址。
GPCOPY 2.1.0 新增dest-mapping-file选项可以帮助用户解决源数据库和目标数据库之间的通信问题。
3. 减少端口占用
如前面提到, GPCOPY 可以同时运行多个job,每个job 负责拷贝一个表。GPCOPY 2.1.0之前的版本,每个目标表都有独立的gpcopy_helper进程用来接收数据,每个gpcopy_helper进程分别占用不用的端口。因此会出现如果设置的job数量很多,则占用的端口会过多的情况。GPCOPY 2.1.0 实现了多个gpcopy_helper进程可以复用同一个端口来接收数据,从而减少了端口资源的占用。
4. 增加进度展示及统计信息
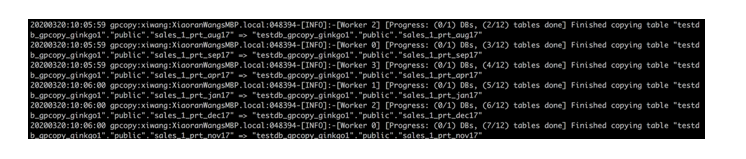
每个表拷贝完成时,GPCOPY都会展示出当前的拷贝进度:总共多少表需要拷贝,已有多少表完成拷贝。

当所有表拷贝完成时,GPCOPY会如上图一样显示本次拷贝总共花费的时间,总共传输的数据量及平均传输速度。
5. 优化命令行
2.1.0版本,GPCOPY 命令支持单字符的option。
二、架构
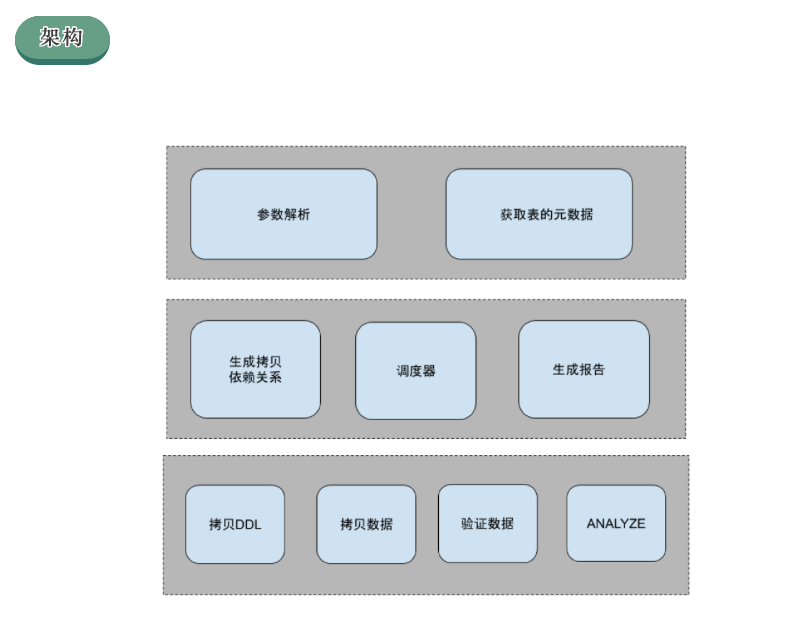
GPCOPY的架构图如上图所示,大概包括三层:1)最上层负责参数解析及获取要拷贝的表的元数据,为进行表拷贝做准备。
2)中间层即第二层负责分析表之间的依赖关系,生成拷贝依赖关系,并负责调度拷贝任务。
3)最底层也即第三层,负责一个表的拷贝。包括拷贝表的DDL、拷贝数据、数据验证及对表进行ANALYZE。
第一层比较好理解,不做过多解释。第三层是拷贝一个表必须的,第二层是并行拷贝多个表所必须的,接下来将自底向上进行详细介绍。
1. 拷贝一个表
- 拷贝DDL
目前GPCOPY基于pg_dump实现拷贝表的DDL。首先在源端使用pg_dump -t 导出源表的DDL,然后在目标数据库执行该DDL来创建表,并对创建表涉及的schema、sequence 、权限等做了处理。
- 拷贝数据
把数据从源表拷贝到目标源有两种模式,一种是master之间拷贝,另外一种是segment之间拷贝。当数据量比较小的时候建议使用master拷贝数据,否则使用segment拷贝数据,模式选择可参考 –on-segment-threshold 选项使用说明。
无论是哪式拷贝模式,主要的步骤大致如下:1)使用copy 工具把数据从源表中导出。2)然后gpcopy_helper把数据从源master/segment传递到目标端master/segment上3)最后再使用copy工具把数据导入到目标表中。
当使用segment模式进行拷贝数据的时候,使用的是copy on segment命令将数据导入导出到segment上,但是该命令将数据导入到表的时候不支持重分布。因此当数据在目标需要重分布时候,使用临时外部表代替copy 命令将数据导入表中。
- 验证数据
该模块用于验证拷贝到目标表中的数据是否正确。有两种数据验证方法:md5xor 和 count。 md5xor是比较严格的数据验证方法,会把源表和目标表中的每行数据都计算在内,因此该方法比较耗时。而count方法则相反,只简单的对比源表和目标表中的数据条数,比较简单也不严格。用户可根据自己的需求选择验证数据或者不验证,或者选择不同的验证方法。
- ANALYZE
gpdb中提供了ANALYZE命令用于更新数据库中表的统计信息。GPCOPY中也提供在拷贝完一个数据表后自动调用ANALYZE命令的功能。
2. 并行拷贝多个表
在本文前面已经提到有外键的表、view、有继承关系的表,这些类型的表不是独立存在的,它们依赖于其它的表。这种依赖关系对于并行拷贝多个表造成了很大的困难。GPCOPY主要通过以下几个模块解决该问题。
- 生成表之间的拷贝依赖关系
对于数据库,表之间的依赖关系有很多种,比如有外键的表是表中的某一列引用另外一个表的一列,通过pg_constraint可获取该依赖关系;view则是一个表依赖于另外一个表或者多个表,通过pg_depend和pg_rewrite可获取该依赖关系;有继承关系的表(包括partition 表)则通过pg_inherits来获取该依赖关系。但对于GPCOPY来讲,只有一种依赖关系,即拷贝依赖关系:一个表依赖于另外一个表,被依赖的表需要先拷贝。
该模块通过查询源数据库的catalog,分析表之间不同的依赖关系,最终生成表之间的拷贝依赖关系。
- 调度器
调度器主要负责两个工作:第一,保证表的拷贝顺序符合表之间的依赖关系;第二,控制拷贝表的并发度。
怎么才能使拷贝顺序符合表之间的依赖关系?思路很简单,没有任何依赖的表或者其依赖的表全部拷贝完成,则调度拷贝该表,否则该表不会被调度。
- 生成报告
该模块比较简单,收集并行执行的表拷贝的结果,生成拷贝进度信息及汇总信息。
三、未来规划
GPCOPY的官方文档可以参考https://gpdb.docs.pivotal.io/GPCOPY/2-1/index-GPCOPY.html。在接下来的版本,GPCOPY还会支持增量传输,进一步提高性能。也希望广大用户多多反馈,多提宝贵意见。
本文作者
王晓冉,现任Greenplum研发工程师。
研究生毕业于中国科学院软件所软件工程专业。目前主要负责gpcopy的研发工作。此前参与了gpkakfa的研发及Postgres Merge工作。

