本文作者Pivotal Greenplum工程技术经理王昊所在的Greenplum研发部门近期在帮助客户解决一个全局性能问题,并通过本文记录了分析过程和解决思路。我们在【实录】首次利用GPCC历史数据调优Greenplum 第一部分中帮助大家了解了GPDB集群的整体性能特征,在【实录】首次利用GPCC历史数据调优Greenplum 第二部分中分析了查询负载整体情况。今天,将为大家带来《首次利用GPCC历史数据调优Greenplum》系列的完结篇——分析数据表行数变化趋势供大家学习讨论。
第三部分,分析数据表行数变化趋势
在第一部分的末尾,我们怀疑的另一个方向就是用户的数据量是否发生了显著的增加。由于数据量增加可以直接导致磁盘IO变多,侧面上也能联系到“整体性能下降”的反馈。
GPCC4.9/6.1即将提供数据表大小的监控和变化趋势历史数据的功能,但撰写本文时,该功能还在研发中,本次客户的数据当然也不包括这些全新历史数据。
但是这并不意味着我们束手无策,这里我们介绍GPCC4.8的第三个历史表:gpmetrics.gpcc_plannode_history。这个表可以记录(1)Master上生成的查询计划树(2)查询执行时每个查询计划节点在每个Segment进程上运行的实际结果。

执行计划节点历史(gpmetrics.gpcc_plannode_history)是GPCC 4.x的新功能,以前的GPPerfmon并没有类似功能。这个表提供的信息非常丰富,因此也需要占用更多空间,为了平衡GPCC目前只对执行时间超过10秒的查询记录完整的计划节点历史。这个表的用途非常多,例如绘制图形化的执行计划树,在以前的介绍文章《新一代Greenplum监控管理平台》里有过介绍。
这里我们借助这个表的信息推算用户数据表大小及变化趋势。我们知道GP执行查询时通过Seq Scan节点进行表扫描;如果扫描节点的条件是空,则说明是一个全表扫描;在此基础上累加所有Segment 上同一扫描节点的输出的行数,即为该表的实际行数。
基于此下面的查询可以统计出所有的全表扫描的结果。
WITH master_nodes (tmid, ssid, ccnt, nodeid, rel_oid, relation_name) AS (
SELECT tmid, ssid, ccnt, nodeid, max(rel_oid), max(relation_name)
FROM gpmetrics.gpcc_plannode_history
WHERE ctime >= '2019-09-23' AND ctime < '2019-10-17'
AND node_type IN ('Seq Scan', 'Append-only Scan', 'Append-only Columnar Scan', 'Table Scan', 'Bitmap Heap Scan')
AND condition = '' -- 只统计没有过滤条件的全表扫描
AND segid = -1 -- MASTER记录的执行计划过滤出适合的query id + node id
GROUP BY tmid, ssid, ccnt, nodeid
),
table_rows (rel_oid, relation_name, hash_name, cdate, row_cnt, scan_cnt) AS (
SELECT rel_oid, relation_name, substring(md5(relation_name) FROM 1 FOR 12) tname
, ctime::date ctime, round(avg(row_cnt)) AS row_cnt, count(*) AS scan_cnt
FROM (
SELECT n.ctime, n.tmid, n.ssid, n.ccnt, n.nodeid, m.rel_oid, m.relation_name, sum(n.tuple_count + n.ntuples) row_cnt
FROM gpmetrics.gpcc_plannode_history n -- JOIN所有Segment的数据累加得到行数
INNER JOIN master_nodes m
ON n.tmid = m.tmid AND n.ssid = m.ssid AND n.ccnt = m.ccnt AND n.nodeid = m.nodeid
GROUP BY n.ctime, n.tmid, n.ssid, n.ccnt, n.nodeid, m.rel_oid, m.relation_name
) dt
GROUP BY rel_oid, relation_name, ctime::date
HAVING avg(row_cnt) > 10000 AND count(*) > 10 -- 粗略过滤掉太小的表和不经常访问的表
)
SELECT tr.rel_oid, tr.hash_name, tr.cdate, tr.row_cnt, tr.scan_cnt
FROM table_rows tr
INNER JOIN (
SELECT rel_oid, relation_name, sum(row_cnt), rank() OVER(ORDER BY sum(row_cnt) DESC) rn
FROM table_rows GROUP BY rel_oid, relation_name, hash_name
) tor -- 按照表内的行数排序
ON tr.rel_oid = tor.rel_oid AND tr.relation_name = tor.relation_name
ORDER BY tor.rn, cdate
;结果比较长,下图截取了排名靠前的行
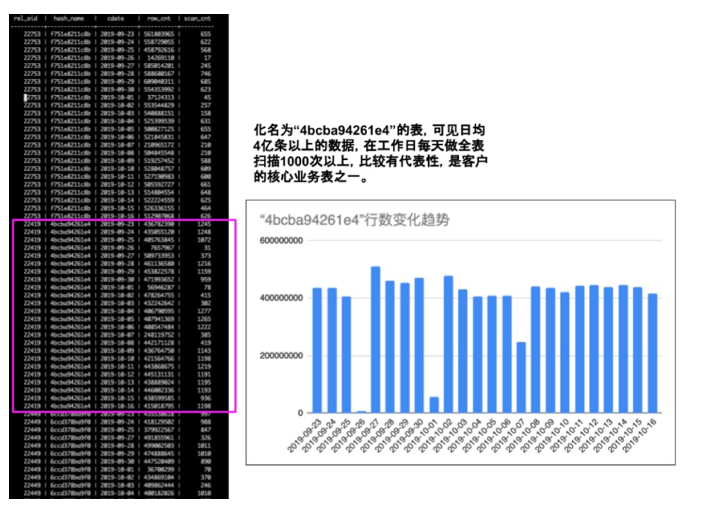
剖析
通过对一批主要的业务表进行统计,发现从9月22日升级到10月中旬期间,没有明显的数据量变化,故推断用户业务模型不存在显著的数据量增大现象,因此导致性能退化的可能性低。
第四部分,分析具体查询的查询计划
结合第二部分和第三部分的分析结果,我们基本排除了查询变多、数据量变大等因素,这时第一部分的现象(磁盘IO变多)还是悬案。通过汇总报告和客户进一步沟通,我们得到了重要的信息,性能下降的反馈主要来自于数据库用户f8da676。
在前面第二部分分析中注意到了该用户是短查询为主,而且对比GP4和GP5的数据,长查询的耗时有一定增加。客户自述该数据库用户是通过Web应用访问数据库。这种Web端的查询一般时间较短,对响应时间要求高,如果个别高频查询速度变慢确实会造成用户体验显著降低。
结合上述分析结果加上客户反馈的佐证,我们聚焦到f8da676的查询,钻取更细节的信息。首先的调查高频度重复发生的查询。在Web应用里有大量固化在程序里的查询,例如登陆、打开页面、查询这些操作。这种工作负载的一个特点就是相同的SQL语句大量查询重复发生,所以我们优先关注这些查询,按照累计的执行时间排序。在gpcc_queries_history表里又一个字段query_hash,我们对这个字段做group by就可以聚集重复的查询。(本案中客户不提供query_text,只能利用query_hash)
SELECT substring(query_hash FROM 1 FOR 12)
, count(*) cnt, sum(tfinish - tsubmit)::interval(0)
, avg(tfinish - tsubmit)
FROM gpmetrics.gpcc_queries_history
WHERE substring(md5(username) FROM 1 FOR 7) = 'f8da676' -- 限定我们要调查的用户
GROUP BY query_hash
HAVING count(*) > 500 -- 重复次数超过一定数量
ORDER BY sum(tfinish - tsubmit) DESC -- 按照累计执行时间排序
LIMIT 20; -- 取TOP2
substring | cnt | sum | avg
--------------+----------+-----------+-----------------
f19c3f3fa258 | 53903 | 133:55:28 | 00:00:08.944363
a0a59ee1ae70 | 205398 | 52:49:56 | 00:00:00.925986
3e8124b89ecc | 1166734 | 50:45:45 | 00:00:00.156629
645323facf3d | 51237 | 39:53:02 | 00:00:02.802317
864a2dace31e | 10591406 | 32:56:50 | 00:00:00.011199
e15e361b69e2 | 2079284 | 29:42:11 | 00:00:00.051427
91085d8d4f7b | 15485 | 26:40:19 | 00:00:06.20077
e7c1dd315794 | 54448 | 20:03:46 | 00:00:01.326516
59e587262761 | 44803 | 12:10:03 | 00:00:00.977689
57630afb6ab7 | 225377 | 09:53:57 | 00:00:00.158123
203de5f2a3d7 | 42702 | 09:27:24 | 00:00:00.797241
cbb3d6598b1d | 55918 | 09:25:43 | 00:00:00.60702
7e6d6491c0f1 | 268018 | 09:19:58 | 00:00:00.125357
bbc6d3151ae2 | 27763 | 09:17:16 | 00:00:01.20432
c6f57e4d2bf6 | 267741 | 08:35:38 | 00:00:00.11555
0172117cf4e2 | 435072 | 07:58:14 | 00:00:00.065952
5b492fd46683 | 107781 | 07:57:19 | 00:00:00.265714
5c5ffc59b6f9 | 64307 | 07:48:24 | 00:00:00.437028
f811d0f43ec0 | 42565 | 06:49:33 | 00:00:00.577295
bd4c80a9d9f2 | 267741 | 06:33:46 | 00:00:00.088241剖析
这个结果里排名第一的查询f19c3f3fa258非常抢眼,它满足三个重要的特征:
1. 重复次数足够多
* 日均2000次以上,要么是某些任务周期性调度,要么是由UI页面人工操作时触发的
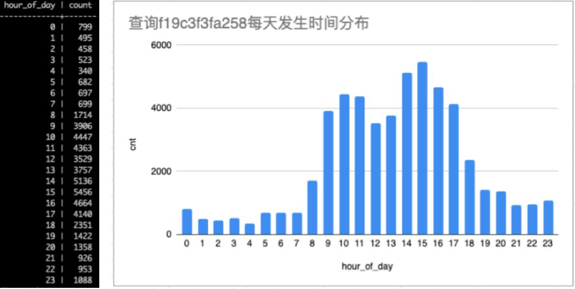
* 我们通过下面SQL了解该查询每天发生的时间
SELECT extract(hour FROM tfinish) AS hour_of_day, count(*)
FROM gpmetrics.gpcc_queries_history
WHERE substring(md5(username) FROM 1 FOR 7) = 'f8da676'
AND substring(query_hash FROM 1 FOR 12) = 'f19c3f3fa258'
GROUP BY 1
ORDER BY 1;* 不难看出这个查询是每天白天数量多,应该是人工操作触发的
2. 累计执行时间非常长,达到133小时55分钟
* 我们通过以下SQL得知,在f8da676用户下的全部查询累计也只有1300小时左右,单独这一个查询就占了10%的执行时间。
SELECT sum(tfinish - tsubmit)::interval(0)
FROM gpmetrics.gpcc_queries_history
WHERE substring(md5(username) FROM 1 FOR 7) = 'f8da676';
sum
------------
1320:34:013. 该查询的平均执行时间偏长,达到8秒之多。这种量级的查询如果出现在业务系统中,与那些毫秒级的短查询不同,足以引起用户的体验降低。
综合上述三点,我们认为f19c3f3fa258这个查询非常值得怀疑,有着很高的分析价值,应该马上着手调查。
定位到具体查询之后,我们通过查询计划继续了解该查询的更多细节。
第一步,通过gpcc_queries_history, 我们找到这个执行较长的一次的query ID:
SELECT tmid, ssid, ccnt, (tfinish - tsubmit)::interval(0)
FROM gpmetrics.gpcc_queries_history
WHERE substring(md5(username) FROM 1 FOR 7) = 'f8da676'
AND substring(query_hash FROM 1 FOR 12) = 'f19c3f3fa258'
ORDER BY 4 DESC
LIMIT 3;
tmid | ssid | ccnt | interval
------------+--------+------+----------
1569340966 | 42118 | 18 | 00:03:49
1569340966 | 518345 | 30 | 00:03:23
1569340966 | 46178 | 10 | 00:03:18第二步,用query ID找到这个查询的执行计划(这里对出现的表名进行了脱敏处理)
SELECT nodeid, parent_nodeid AS pnid, node_type, rel_oid, relation_name, condition
FROM gpmetrics.gpcc_plannode_history
WHERE tmid = 1569340966 AND ssid = 42118 AND ccnt = 18
AND segid = -1 AND sliceid = 0
ORDER BY nodeid;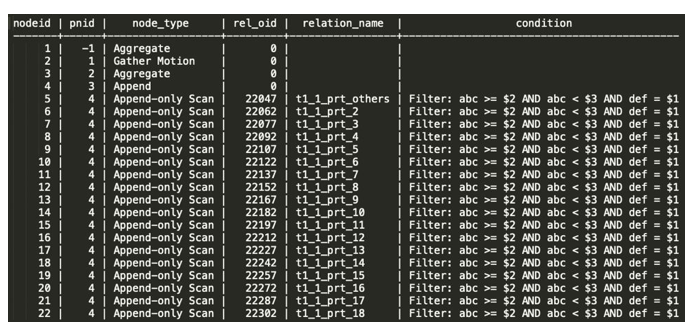
第三步,通过nodeid和parent_nodeid之间的父子关系,恢复这个查询的计划树
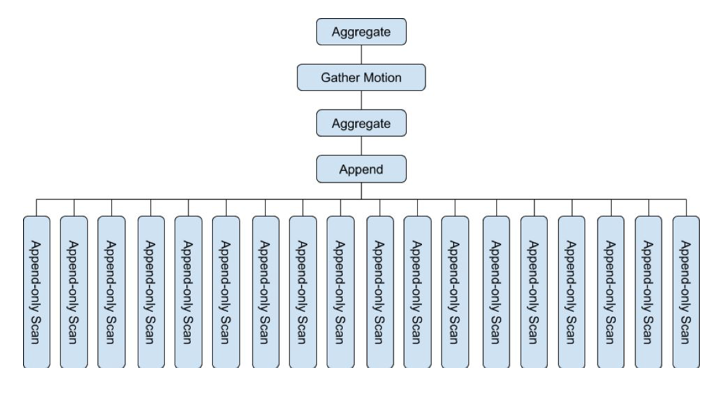
这个查询树展示的非常清晰
1. 这是一个简单的单表查询,对表t1扫描加聚集,扫描时应用了范围过滤条件 $2 <= abc < $3 和等值过滤条件 def = $1。
2. 典型的两阶段聚集,现在Segment上本地聚合一次,再Gather Motion到Master上全局聚合一次。这是GP常规的执行计划。
3. 这个查询对AO表t1的18个分区进行了扫描。
我们不清楚t1表一共有多少分区,也不清楚分区键和分布键各自是什么。一种怀疑就是列abc就是分区键,planner优化器应该根据abc列上的范围条件进行分区裁剪,从而减少扫描的分区数。猜测某些原因导致没能正确进行分区裁剪。
抱着这种猜测,通过进一步跟客户,我们得到了t1表的定义DDL(已脱敏)。果然abc是分区键。该表一年一个分区,共18个分区。
CREATE TABLE t1 (
… -- 此处省略若干行
abc timestamp without time zone NOT NULL,
… -- 此处省略若干行
)
WITH (appendonly=true, orientation=row) DISTRIBUTED BY (...) PARTITION BY RANGE(abc)
(
START ('2002-01-01 00:00:00'::timestamp without time zone) END ('2003-01-01 00:00:00'::timestamp without time zone) EVERY ('1 year'::interval) WITH (tablename='t1_1_prt_2', appendonly=true, orientation=row ),
START ('2003-01-01 00:00:00'::timestamp without time zone) END ('2004-01-01 00:00:00'::timestamp without time zone) EVERY ('1 year'::interval) WITH (tablename='t1_1_prt_3', appendonly=true, orientation=row ),
… -- 此处省略若干行
START ('2016-01-01 00:00:00'::timestamp without time zone) END ('2017-01-01 00:00:00'::timestamp without time zone) EVERY ('1 year'::interval) WITH (tablename='t1_1_prt_16', appendonly=true, orientation=row ),
START ('2017-01-01 00:00:00'::timestamp without time zone) END ('2018-01-01 00:00:00'::timestamp without time zone) EVERY ('1 year'::interval) WITH (tablename='t1_1_prt_17', appendonly=true, orientation=row ),
START ('2018-01-01 00:00:00'::timestamp without time zone) END ('2019-01-01 00:00:00'::timestamp without time zone) EVERY ('1 year'::interval) WITH (tablename='t1_1_prt_18', appendonly=true, orientation=row ),
DEFAULT PARTITION others WITH (tablename='t1_1_prt_others', appendonly=true, orientation=row )
);至此我们高度怀疑这个查询没能正确利用GP的分区裁剪功能,每次查询都对十几年来的全部数据进行了扫描,造成查询时间长达8秒。而且这个原因也能充分佐证磁盘IO增多的现象。
第五部分,原因分析和后续处置
定位到了问题查询和现象,我们的工程师很快发现
1. 客户提交的查询使用了JDBC
JDBC在提交查询时会时使用Prepare … Execute 方式。Prepare一个带参数的查询时GPDB会先生成一个执行计划,由于此时参数未知,GPDB可能没法应用分区裁剪或DirectDispatch这样的优化。当执行Execute时,参数才会告知GPDB,这时GPDB会判断直接使用Prepare生成的查询计划还是重新生成一个更优的查询计划。本案例中捕捉到的慢查询都是没有重新生成执行计划,因此没能按期望应用分区裁剪。
在老版本GP4上,并没有直接使用Prepare语句生成的执行计划的功能,因此所有查询计划都是在Execute时重新生成的。这本来是一个GP4的问题,在GP5得到了改进,即可以采用Prepare预生成的查询计划以加速执行,但是本案例中反而导致了Prepare出的低效查询计划被采用了。
2. 客户关闭了ORCA
在上面情况中,即便采用了没有分区裁剪的执行计划,ORCA也能克服这个问题。因为ORCA会生成动态分区扫描的计划,这种优化技术将分区裁剪的决定权下放到执行器的执行阶段,因此不会收到Prepare语句的影响。但因为客户环境下ORCA默认关闭了,才暴露出了这次的问题。
经验证,升级JDBC驱动,增加适当的调试参数后,问题基本得到解决。除了这个查询之外,我们可以预期的是其他查询将也可以应用分区裁剪、DirectDispatch这些优化,集群的整体响应速度和磁盘负载应该一并好转。
后记
我在2018年底杭州的PG大会上做过一个报告,大胆提出了要通过查询历史数据改进数据库自动化运维的观点,原报告见《为您详细讲解Greenplum 5 智能化运维》。经过将近一年的时间,终于有机会在实际生产中运用,颇为欣慰。
这个案例中展示的很多分析手段、分析角度都是比较独特的,在以前我们作为GP的原厂研发人员也未曾使用过。我希望基于这样的案例拓展对用户查询负载的认识,逐步从这些分析方法中筛选出有效的套路,进而落实到智能化运维产品中。这个愿景目前看来充满机遇和挑战,一旦能够实现,相信会带来广阔的应用价值。
关于作者
王昊,Pivotal Greenplum工程技术经理
曾任职于Teradata SQL实验室。长期从事分布式数据仓库的研究,深谙高并发MPP数据库之美,作为Greenplum内核研发团队的核心成员,主持全新一代自治数据库平台GPCC的规划、设计和开发,奠定了Greenplum在自动化运维领域的领先地位。同时凭借丰富的工程经验和行业洞悉,为中国研发团队在分布式引擎、ETL工具、扩展组件、质量保证等多项领域提供创新输入和人才培养。

