作者:林少坤 Greenplum资深研发工程师
Apache Solr是一款基于Apache Lucene的高效文本检索引擎,它具有容错性(fault tolerant),高可用(highly availability),易扩展(scalability),分布式(distribution)等特点,在世界上著名的大型应用和网站中被广泛使用,如eBay, Instagram, Netflix等。
GPText是 Greenplum生态系统的一部分。它无缝集成了Greenplum数据库海量数据并行处理以及Apache Solr企业级文本检索的能力,为用户提供了一套易于使用、功能完备的文本检索、分析方案。
在GPText的调优过程中,笔者发现Solr 7在返回大量搜索结果时,响应速度下降异常严重。经测试,笔者将性能瓶颈定位在Solr 7对DocValues的读取上,大量分析后,发现这是由于Solr 7不合理的DocValues读取机制导致的。
本文将会对Solr的DocValues进行介绍,并详解Solr 7/Solr 8中DocValues的读取机制,以及如何对其进行优化。在笔者的测试环境中,优化后的Solr 7响应速度可以提升10倍以上!
Solr的搜索
GPText的典型用例
在正式讲解solr的搜索过程前,笔者先简单介绍一下GPText的典型搜索用例。
假设我们有一张名为test的表,该表有两个字段,分别为id和content,如下:

我们事先对该表建立了一个索引,名为“demo.public.test”(备注2)。此时,若想搜索含有“VMware”关键词的记录,则可以调用如下语句(备注3):
select id from gptext.search(table(select 1 scatter by 1),
'demo.public.test', 'VMware', null);结果如下:
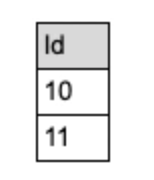
此时,若想搜索同时含有“VMware”和“Your”这两个关键词的记录,则可以调用如下语句:
select id from gptext.search(table(select 1 scatter by 1),
'demo.public.test', 'Your AND VMware', null);结果如下:
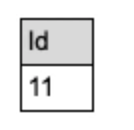
实际操作用例中,可能会将上述结果与原表“test”进行join以进行进一步分析。
备注1:https://lucene.apache.org/solr/
备注2:关于GPText的安装,索引的建立以及数据的导入,请参考https://gptext.docs.pivotal.i…
备注3:关于gptext.search函数各个参数的意义,请参考https://gptext.docs.pivotal.i…
Solr的搜索过程
在开始Solr的搜索过程前,我们需要先讲解两个概念:doc id和倒排索引。
Doc id是Solr为Solr中的每个文档(一个Solr的文档对应一条数据库的记录)所创建的一个内部标识符,该标识符是连续且唯一的。假设Solr中有10个文档,那么这10个文档的doc id就是0至9。Doc id与数据库中的主键功能类似,但与数据库的主键值未必相同。
以之前的test表为例,它在Solr中的存储是:

倒排索引(inverted index),是文档检索系统中最常用的索引方法,它存储了在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。在大部分的存储方式里,我们都是根据记录来查找属性。而倒排索引则相反,它是一种允许我们通过属性来查找记录的索引。
仍以之前的test表为例,我们为该表的content字段在Solr中建一个倒排索引,则该索引如下,
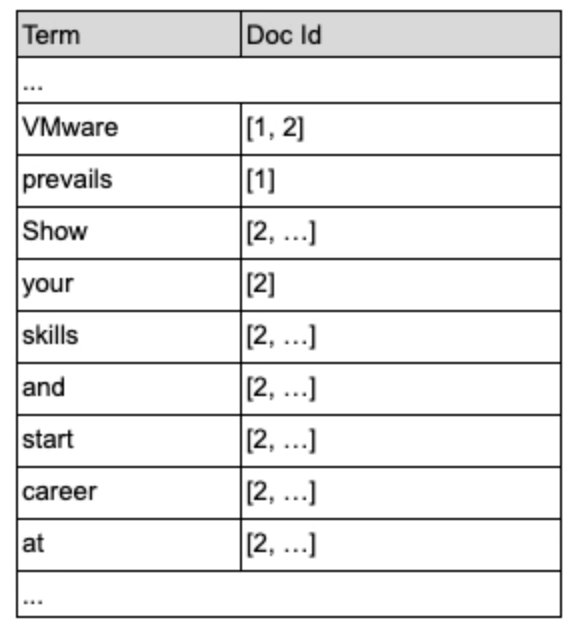
其中,“VMware: [1, 2]”表示“VMware”这个词出现在doc id为1和doc id为2的两个文档中。
在执行如下SQL语句后,GPText会向Solr发出请求:查找在content中包含VMware这个词的所有记录,并返回其id。
select id from gptext.search(table(select 1 scatter by 1),
'demo.public.test', 'VMware', null);Solr端接收到请求之后,会在自己维护的倒排索引里面去寻找包含“VMware”这个词的文档。此时,Solr将会发现doc id为1和2的两个文档符合条件。接着,Solr会去查找doc id为1和2的两个文档对应的id值。如果我们配置了Solr按列存储,那么就从列存(在Solr中称为DocValues)中去读取id,否则,就从行存(在Solr中称为Stored Fields)中去读取id。(Solr的按行存储和按列存储可以同时配置。)
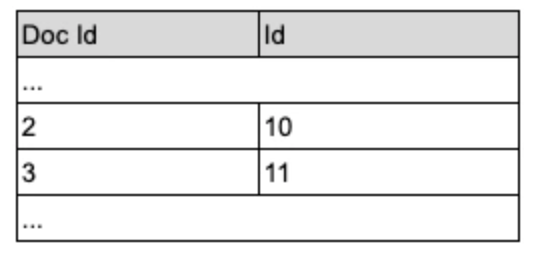
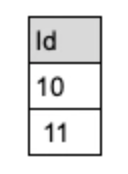
若在Solr中如上表配置了按列存储,则从该存储中读取doc id为1和2的文档对应的id值,即10和11。
在从列存或行存中获取到id之后,Solr会将如下结果返回给GPText:
Solr的DocValues
DocValues介绍
如上文所述,DocValues就是Solr里的列存(column-oriented fields),它存储了文档到对应的列(field)的值的映射。
既然Solr已经有行存了,为何还需要使用列存呢?这和在关系型数据库中使用列存的道理相同:
- 每一列中的所有值拥有相同的数据类型,因此可以使用更加高效的压缩算法。
- 更高效的压缩算法意味着更少的数据量,因此可以大大减少I/O的代价。
- 较少的I/O代价可以大大提高排序(sorting)、分组(grouping)、聚合(faceting)等需按列读值的操作的速度。
Solr 7对DocValues的读取
Solr 7将65536个DocValue当作一个block来存储。在每个block头会存储该block的长度。我们若需要知道某个block的位置,则需要知道上一个block的位置以及上一个block的长度,换言之,想要定位某个block的位置,我们需要从第0个block开始一个block一个block遍历。
如下图。
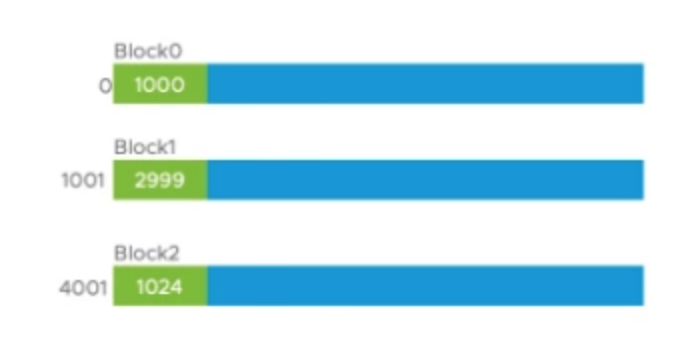
每个block前的数字表示该block的起始位置。每个block的绿色部分表示该block的长度。如果我们要定位Block2,则需要知道Block1的起始位置和长度。想知道Block1的起始位置,又需要知道Block0的起始位置和长度。由于Block0的起始位置为0, 长度为1000,因此Block1的起始位置为1001(0 + 1000 + 1)。知道Block1的起始位置(1001)后,我们可以读取Block1的长度(2999),并计算出Block2的起始位置为4001(1001 + 2999 + 1)。
代码如下:
for docID in docList {
desiredBlock = docID / 65536
blockIndex = 0
blockPosition = 0
while (blockIndex <= desiredBlock) {
blockLength= file.readInt(blockPosition)
# file.getBlock不产生实际I/O
block = file.getBlock(blockPosition, blockLength)
blockPosition += (blockLength + 1)
blockIndex++
}
result.append(block.readValue(docID % 65536))
}
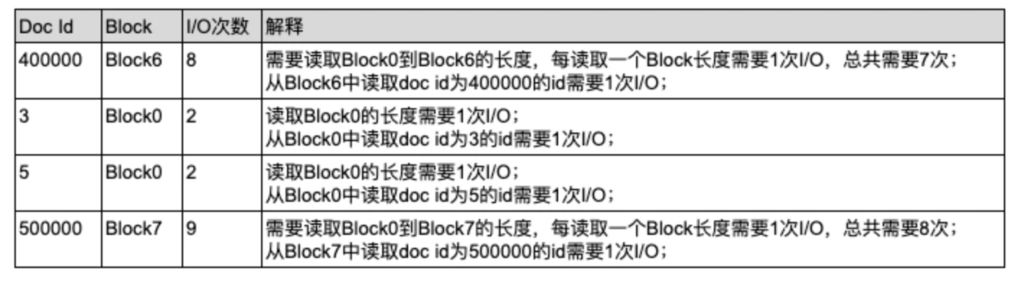
return resultSolr 7每读取一个DocValue后都会从零开始重复同样过程去读取下一个DocValue,即便下一个DocValue在同一个block内。
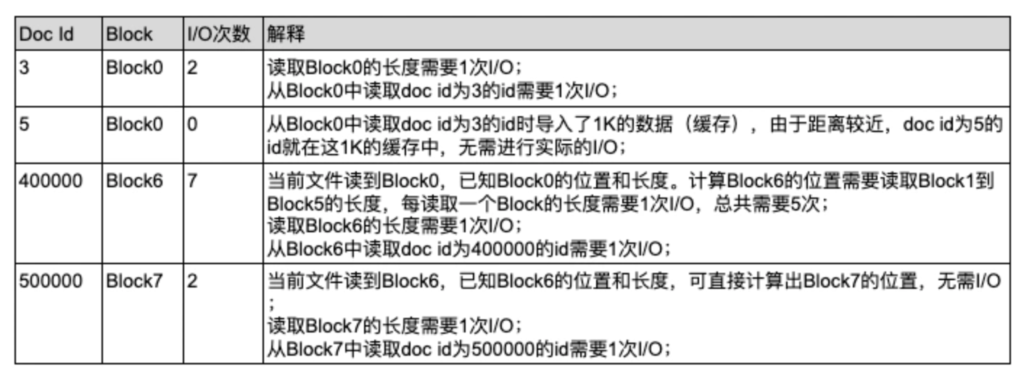
假设我们用Solr 7去读取doc id为[400000, 3, 5, 500000]对应的id(每个id是一个DocValue),则需要的I/O次数总共为21次。
Solr 8对DocValues的读取
Solr 8和Solr 7类似,依旧将65536个DocValue当作一个block来存储。在每个block头依旧会存储该block的长度。但Solr 8会在文件头存储一个metadata,该metadata中会存储每个block的起始位置。因此,我们可以直接从metadata中读取指定的block位置。
如下图。
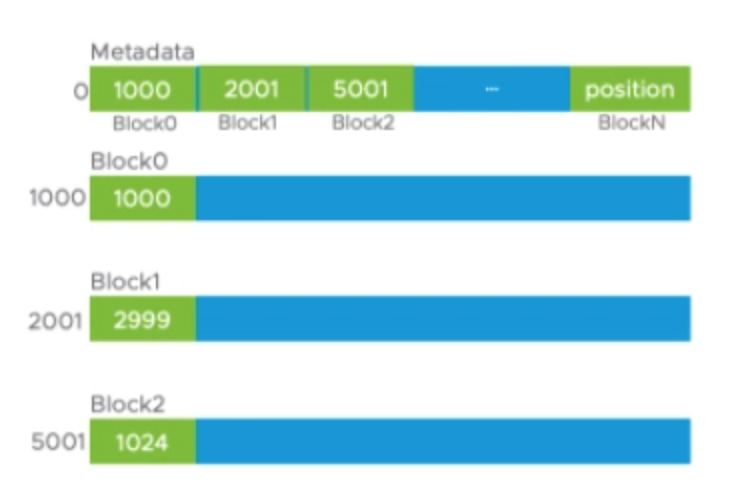
若想定位Block2,直接从metadata中读取位置信息即可,无需同Solr 7一样从Block0开始遍历。
代码如下:
for docID in docList {
desiredBlock = docID / 65536
# 回到文件头读取desiredBlock的位置
blockPosition = file.readLong(desiredBlock * 8)
blockLength= file.readInt(blockPosition)
# file.getBlock不产生实际I/O
block = file.getBlock(blockPosition, blockLength)
result.append(block.readValue(docID % 65536))
}
return result和Solr 7一样,Solr 8每读取一个DocValue后都会从零开始重复同样过程去读取下一个DocValue,即便这俩DocValues在同一block内也是如此。
若我们用Solr 8去读取doc id为[400000, 3, 5, 500000]对应的id,则需要的I/O次数总共为12次。

优化DocValues的读取
对I/O次数的优化
从上述Solr 7和Solr 8读取DocValues的过程中,我们可以发现一个非常大的的问题:每读取一个DocValue后,都得重头开始读取下一个DocValue。这不仅会极大增加I/O的次数,也会使得磁盘缓存失效(Solr的磁盘缓存是1KB。换句话说,每次读文件时都读取1KB的数据。若下次读的文件数据已经在这1KB中,则无需真正去读磁盘)。
返回的结果集内结果的顺序与数据在文件中的位置并不相同,这就给我们从当前位置往下读文件造成了困难。
为了解决这个问题,我们可以先对返回的结果根据doc id进行排序,之后再根据排好序的doc id顺序去读取对应的id(DocValue)。此外,每次读取完一个id后无需从头开始,而是可以从当前位置往后读取。最后,根据原始的doc id顺序进行返回即可。对于Solr 7,优化后的代码如下:
# DocIdPositionMap 是一个map<int, int>的类型
# key是doc id,value是该doc id在docList中的位置(下标)
sortedDocList, DocIdPositionMap = sort(docList)
blockIndex = 0
blockPosition = 0
for docID in sortedDocList {
desiredBlock = docID / 65536
# 排好序后,desiredBlock是只增不减的
while (blockIndex <= desiredBlock) {
blockLength= file.readInt(blockPosition)
# file.getBlock不产生实际I/O
block = file.getBlock(blockPosition, blockLength)
blockPosition += (blockLength + 1)
blockIndex++
}
id = block.readValue(docID % 65536)
position = DocIdPositionMap[docID]
result[position] = id
}
return result根据优化后的算法,在Solr 7 中,读取doc id为[400000, 3, 5, 500000]对应的id(每个id是一个DocValue)需要的I/O次数为11次。(排序后,按照doc id为[3, 5, 400000, 500000]的顺序进行读取)
对于Solr 8,优化后的代码如下:
# DocIdPositionMap 是一个map<int, int>的类型
# key是doc id,value是该doc id在docList中的位置(下标)
sortedDocList, DocIdPositionMap = sort(docList)
blockIndex = -1
for docID in sortedDocList {
desiredBlock = docID / 65536
if (blockIndex != desiredBlock) {
# 回到文件头读取desiredBlock的位置
blockPosition = file.readLong(desiredBlock * 8)
blockLength= file.readInt(blockPosition)
blockIndex = desiredBlock
# file.getBlock不产生实际I/O
block = file.getBlock(blockPosition, blockLength)
}
id = block.readValue(docID % 65536)
position = DocIdPositionMap[docID]
result[position] = id
}
return result根据优化后的算法,在Solr 8中,读取doc id为[400000, 3, 5, 500000]对应的id需要的I/O次数为9次。(排序后,按照doc id为[3, 5, 400000, 500000]的顺序进行读取)

到此为止,我们可以得出该优化算法的优点:
- 减少I/O的次数。对于Solr7来讲,减少的幅度十分巨大。
- 提高缓存命中率。
但该优化算法也是有缺点的:
- 需要排序以及保存一些中间数据,会略微提高对内存的占用。
- 使用一个Map对象(即代码中的“DocIdPositionMap”)来保存doc id与其原始位置的映射。因此当返回的数量较大时会产生大量对象,甚至导致GC(垃圾回收)成为瓶颈。(每个key和value都是一个对象,因此当返回200万条记录时,会产生超过400万个对象)
对GC的优化
如上文提及,由于我们的优化算法用一个Map对象来保存doc id与其原始位置的映射,导致当返回的较多记录时产生了大量对象,甚至产生了可观的GC时间。因此,我们需要消除这个Map对象,通过其它方法来记录某个doc id对应的原始位置。
一个Solr replica的最大文档数量为2147483519(Integer.MAX_VALUE – 128),因此doc id和每个文档的返回位置必然可以用一个int类型的值来表示,无需担心溢出问题。所以我们提出了这样的解决方案:
- 用一个long类型的值来保存一个doc id和它的原始位置,其中高4字节为doc id,低4字节为原始位置。
- 对这些long值进行排序。显然,对long值进行排序的结果与直接对doc id进行排序的结果一致。
- 根据排序后的顺序依次进行id的读取。读取前先将这些long值还原为对应的doc id和它的原始位置。
- 根据doc id读取id后,根据它的原始顺序进行返回。
如果说对GC优化前的代码如下:
# DocIdPositionMap 的每个key/value都是一个对象
sortedDocList, DocIdPositionMap = sort(docList)
for docID in sortedDocList {
id = docValuesReader.read(docID)
position = DocIdPositionMap[docID]
result[position] = id
}
return result那对GC优化后的代码就是:
for docID in docList {
combinedValue = ((long) docId) << 32 | docList.currentPosition()
combinedList[docList.currentPosition()] = combinedValue
}
# 由于一个int数组和一个long数组在java中只是一个对象,所以整个combinedList就一个对象,不会对GC产生较大影响
sort_in_place(combinedList)
for combinedValue in combinedList {
docID = (int) (doc.docId >> 32)
position = (int) (doc.docId & 0xFFFFFFFFL)
id = docValuesReader.read(docID)
result[position] = id
}
return result从原理可知,对GC优化后,我们大大减少了产生的对象数量。由于减少了大量的对象,因此这些对象的对象头(Header),类指针(kclass),对齐填充(Padding)等本该使用的内存都能被节省下来。所以,我们还一定程度上减少了内存的使用。
实验结果
以下实验皆基于一个维基的真实数据集,总共有933069618条数据。该实验的硬件配置如下:
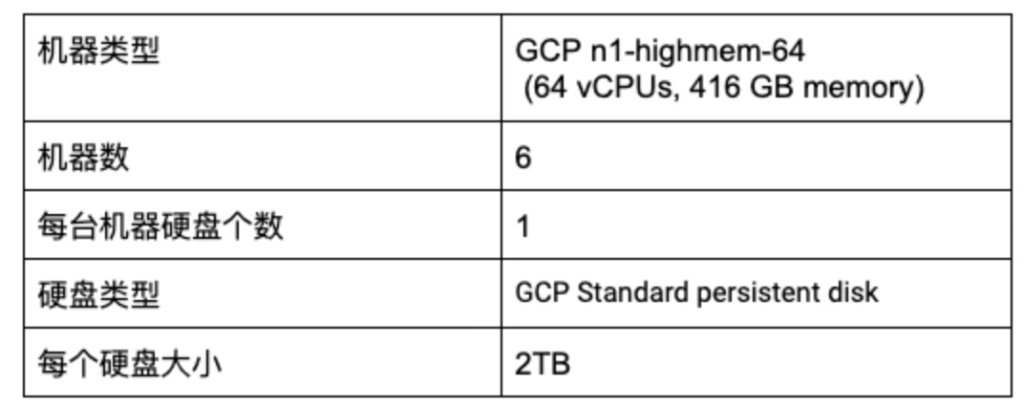
实验的Solr集群配置如下:
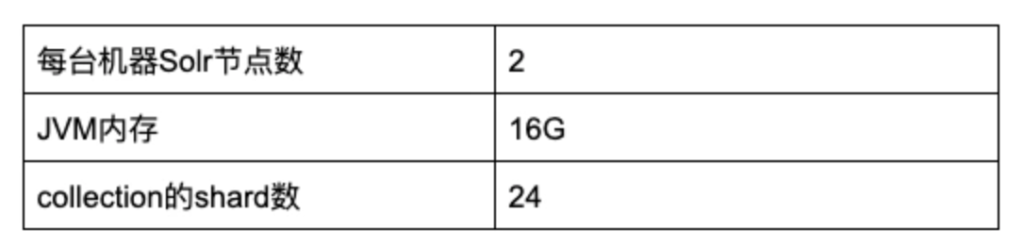
实验使用的query信息:

优化效果
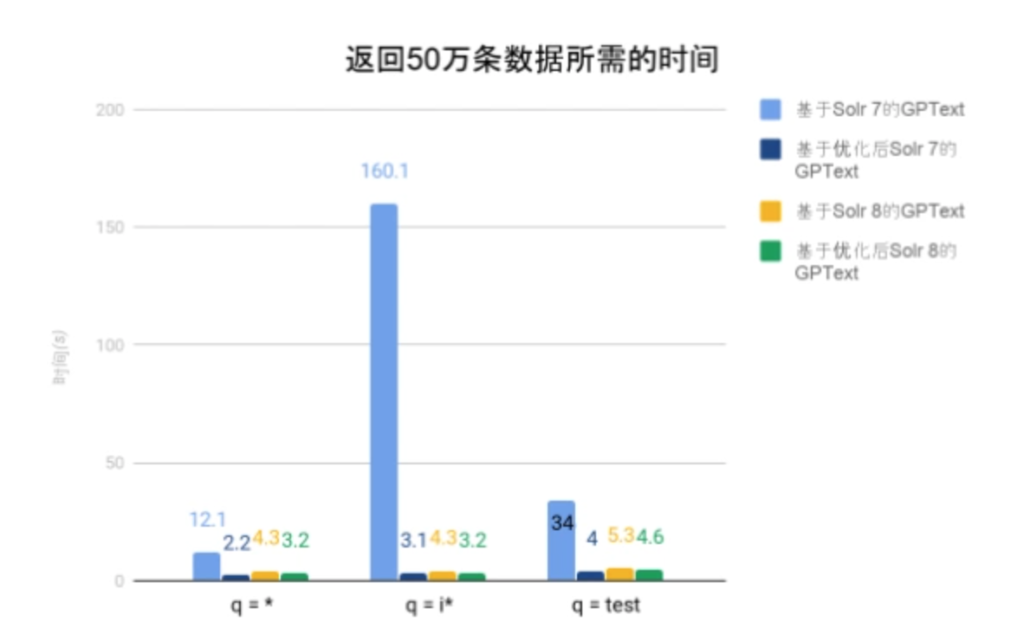
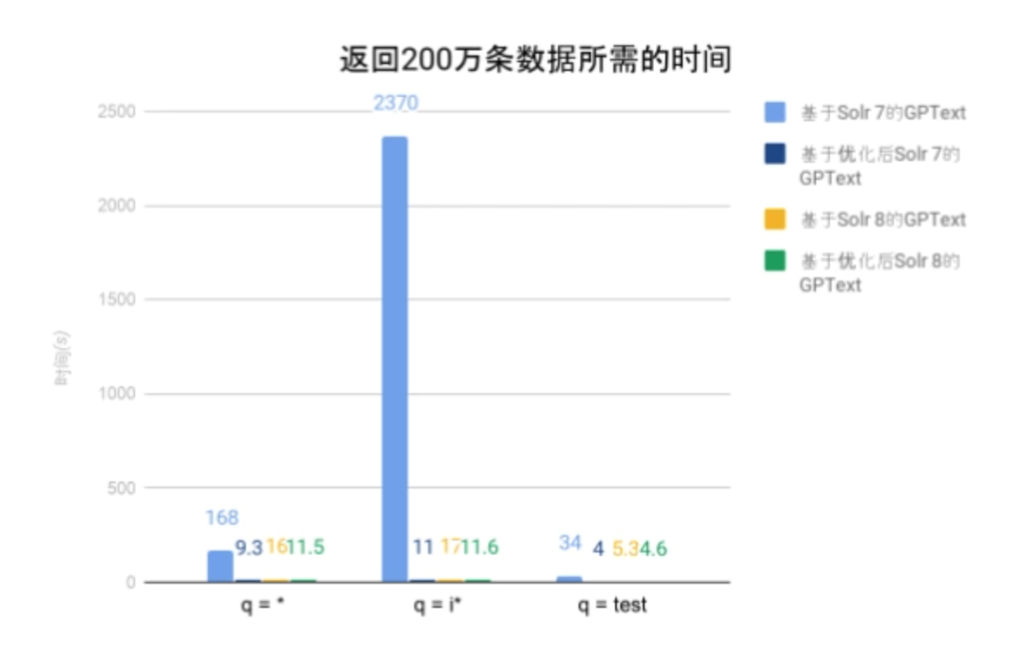
图表中的时间为gptext.search运行所需的时间。由以上两实验可以看出随着返回记录的增加,基于优化后Solr 7的GPText,基于Solr 8的GPText以及基于优化后的Solr 8的GPText所需的时间基本呈线性增长(返回4倍记录,需要的时间为原来的4倍)。而基于Solr 7的GPText所需的时间则急剧上升。这符合我们上文提到的DocValues的读取原理。由实验数据可知,本文提出的优化算法,在返回大量文档的情况下对Solr 7的性能有大幅提升。对Solr 8的性能亦有可观的提升效果。
由于返回的文档数量较多,覆盖了每一个block,因此优化后的Solr 7性能要高于优化后的Solr 8性能。因为在Solr 7中,读取下一个block只需从当前位置往下读取;而在Solr 8中,读取下一个block的需要回到文件头,从文件头中读取下一个block的位置信息,再跳到下一个block,这不仅增加了I/O数量,还会导致磁头大范围的物理移动。
此外,需要说明的是,在“q = test”的查询中,由于匹配的文档数较少,因此在“返回50万条数据”的实验中就已经返回了所有匹配的文档(备注5)。所以,“返回200万条数据”的实验结果与“返回50万条数据”的实验结果一致。
备注4:Solr作为全文检索引擎,在典型的用例中并不会返回如此多的数据(默认返回的文档数为10),因此通常情况下,DocValues的获取不会成为瓶颈。但GPText的典型用例有所不同,返回几十万条数据是经常出现的。
备注5:实验中“返回50万/200万条数据”指的是每个shard返回的文档数为50万/200万。实验中使用gptext.search同时向Solr的所有shard发送请求,要求每个shard返回50万/200万个匹配的文档数。由于有24个shard,因此总共返回的文档数为1200万/4800万。
瓶颈分析
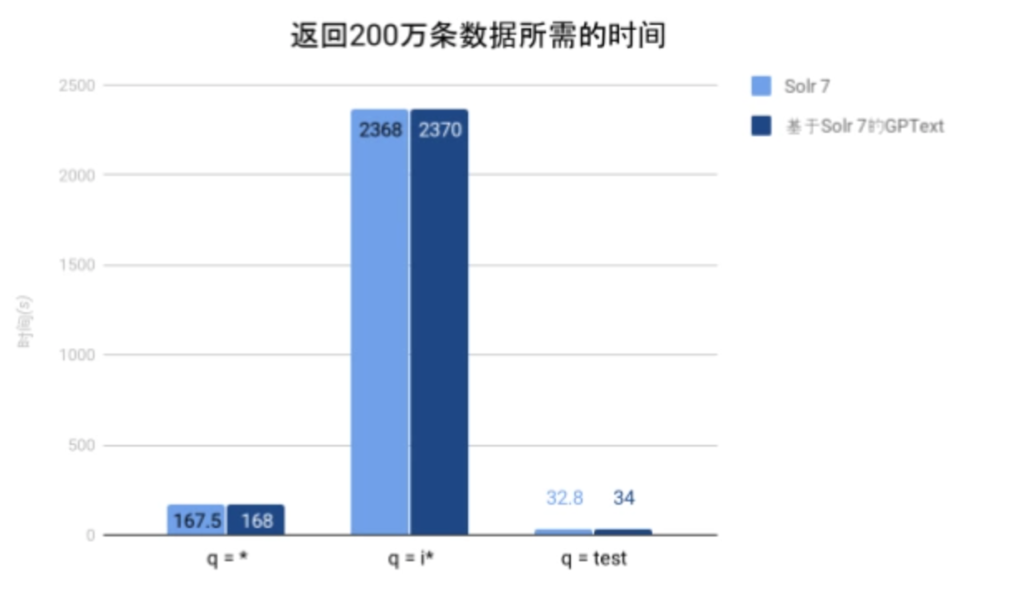
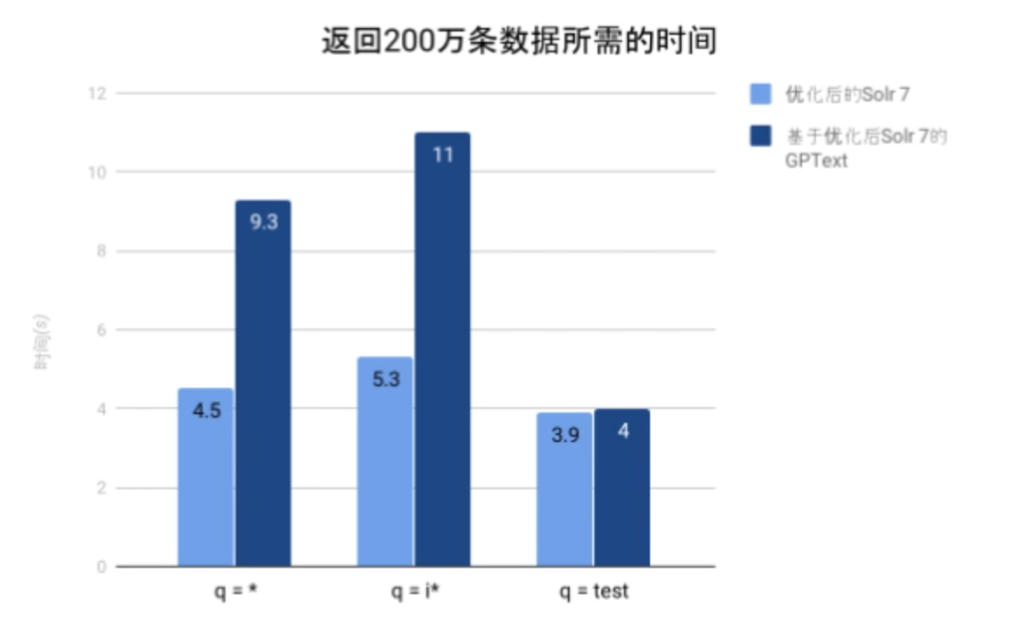
上个实验是基于GPText去获取数据的。而本实验比较了基于GPText获取数据和直接使用Solr获取数据所需的时间。
GPText是从Solr中流式获取数据,并将这些数据流式在GPDB上进行转化输出的。换句话说,获取数据和对数据进行转化是并行发生的。由上两图可知,由于我们对Solr 7的优化,在返回大量数据的情况下,GPText的瓶颈已从Solr变为GPDB端的数据转化,即此时Solr返回数据的速度已经超过了GPDB数据转化速度。由于“q = test”这个查询在相近时间内返回的文档数大大减少,因此在GPDB端进行转化的工作量较小,数据转化未成为瓶颈。
GC优化(备注6)
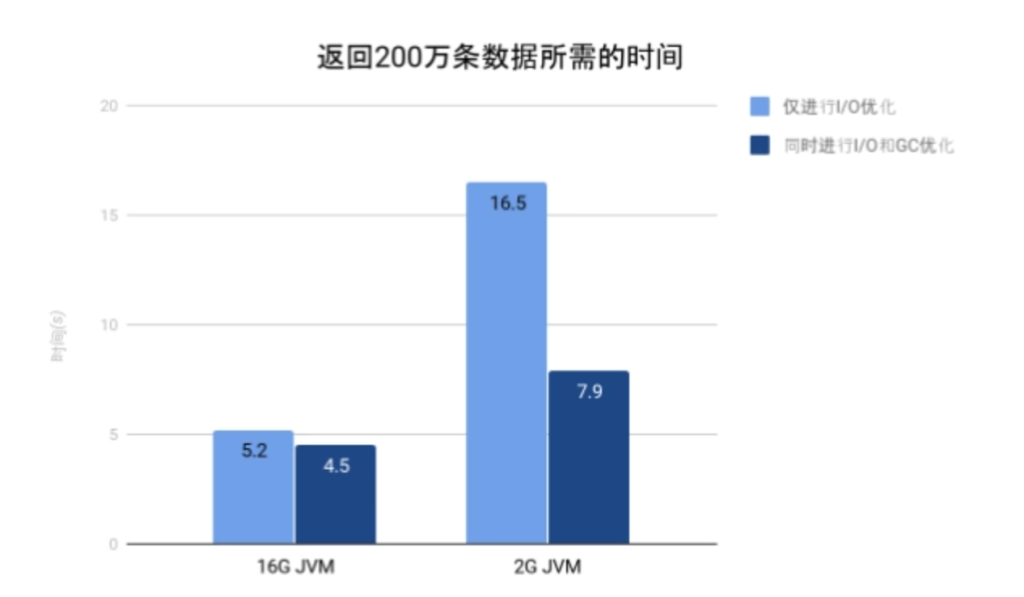
为了防止GPDB成为瓶颈而对实验结果产生影响,本实验使用优化后的Solr 7直接获取数据(未使用GPText),使用的查询为“q = *”。由本实验可知,在JVM内存不足时,对GC进行的优化能极大提升性能。
备注6:除了本次实验,所有实验中“优化”均为同时对“I/O”和“GC”进行优化。
缓存影响
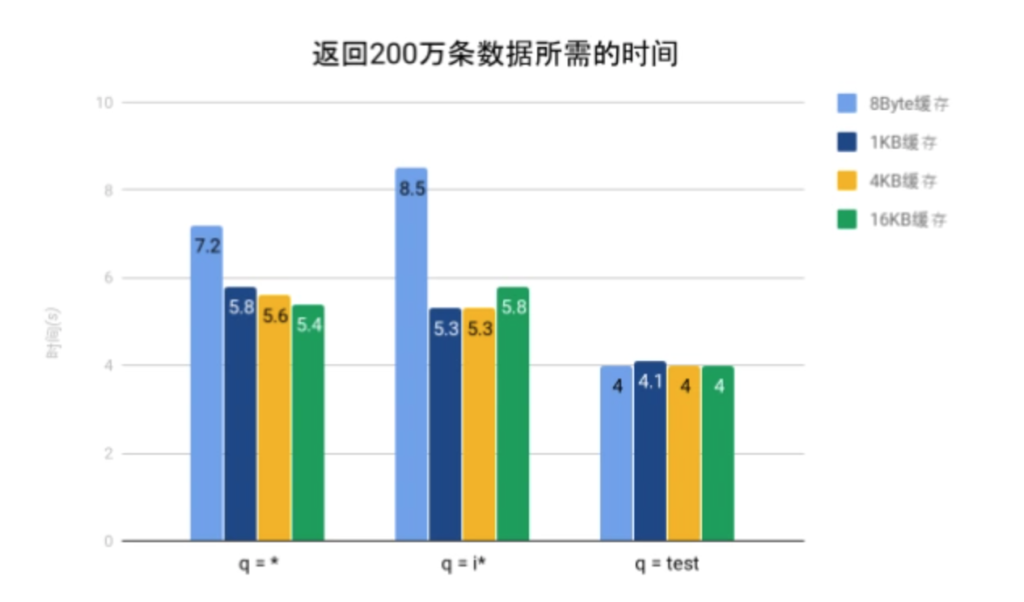
上文中提到过我们对I/O的优化会提高磁盘缓存的命中率,而缓存大小亦会影响命中率。因此我们设计了一个实验以验证缓存大小是否对性能有影响。为了防止GPDB成为瓶颈影响而实验结果,本实验使用优化后的Solr 8直接获取数据(未使用GPText)。
由实验结果可知,当缓存小于1KB时,性能有较大的下降;当缓存大于1KB时,增大缓存对性能并没有较大影响。因此Solr将缓存大小设置为1KB是比较合理的。
需要说明的是,在“q = test”的查询中,由于命中的文档分布较为稀疏,因此缓存命中率几乎为0,所以此时缓存大小对性能影响可以忽略不计。
总结
本文向大家介绍了Solr DocValues的概念,并从减少I/O和GC两个方面提出了优化读取DocValues效率的方法。该方法应用在Solr 7中可以大幅提高读取DocValues的效率,使得GPText在典型应用场景的响应时间大幅降低;应用在Solr 8中亦可使GPText获得可观的性能提升(备注7)。
备注7:截至目前(2020年10月),最新版GPText使用的Solr版本为7.4.0。本文中“基于Solr 8的GPText”、“基于优化后Solr 7的GPText”、“基于优化后Solr 8的GPText”均为笔者自己编译安装的开发版。文中提到的优化方法将会很快正式应用到新版GPText中,敬请期待。
作者简介
林少坤 Greenplum资深研发工程师
17年毕业后加入Greenplum团队,对技术始终保持热情,目前是Greenplum全文检索组件GPText的核心研发之一。

