从2018年7月开始,我和同事一起陆续完成了Greenplum 5的版本测试和公司十几套Greenplum生产集群的升级工作。在这一年多的升级工作中使我真真实实的对Greenplum数据库的使用和运行以及上层应用、平台有了一个更加深入的学习和了解,虽然辛苦但是收获颇丰。因此借此文梳理下Greenplum 5的升级过程,希望能够加深自己的一些认知,也希望对大家能有所帮助。
公司从2013年引进Greenplum数据库到现在,已有7个年头。从最开始的基于Greenplum 4.2版本的24节点的小集群,到如今基于Greenplum 5.17版本的最大集群达到了近200个节点的大集群,Greenplum数据库技术在公司经历了较为漫长的发展使用历程。我几乎全程参与了这个发展历程。
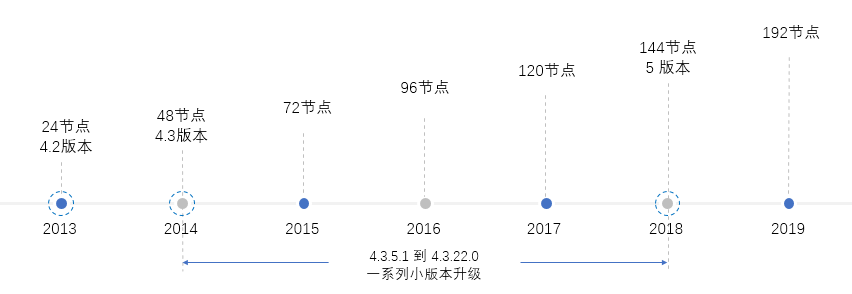
2018年之前,公司使用的Greenplum版本还是4.3.22.0。Greenplum 4.X版本在公司运行了6年,支撑了大量的大数据应用的运行。但是这个版本有几个缺陷,对数据库的安全、高效运行造成了较大的影响:
- 硬件故障导致primary和mirror上元数据(heap表)同时损坏
- analyze运行效率低下
- 资源隔离机制不完善,用户资源竞争严重
为了能够解决上面说了几个问题,我们在18年7月同Greenplum原厂工程师一起,开始了Greenplum 5.X版本的升级测试工作。
一、升级前的验证测试
升级前的具体测试内容如下:
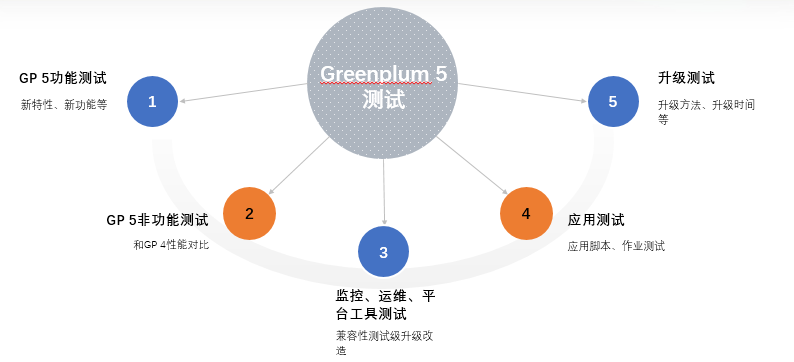
1.功能测试
完成Greenplum 5.X版本新特性、新功能的测试,包括PXF、RESOUCE GROUP等。
2.非功能测试
主要包括稳定是测试以及和Greenplum 4的性能对比测试。
3.监控、运维、平台工具测试
测试Greenplum 5对现有工具的兼容性,以及进行相应的升级改造。
4.应用测试
验证应用作业、脚本能够在Greenplum 5上稳定高效运行。
5.升级测试
验证升级方法的可靠性、效率等,为下一步的生产环境升级提供数据支撑。
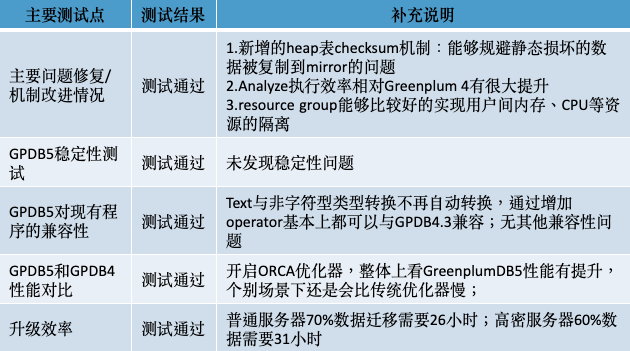
我们花了两个月的时间完成Greenplum 5版本的功能测试、非功能测试以及升级测试,验证了Greenplum生产环境升级到5版本的可行性,简要测试结果如下:
我们将公司两套应用测试环境(2+72和2+32)升级到了Greenplum 5版本,进行进一步的应用案例测试,以确保届时生产环境升级的安全。
整个测试前前后后持续了大概3个月时间,中间也遇到了各种问题,这里就不一一列举,总算最后都得到了解决。Greenplum 5的最终的上线版本也从5.9.0到5.10.0到5.10.1再到5.15.0最终确定为5.17.0。
二、升级过程
前面我们介绍了Greenplum 5.X版本的测试步骤和测试结果,验证了Greenplum 5.X版本在我们生产环境运行的可行性,下面就可以开始进行正式的生产环境升级。生产环境升级,我们一般分成4个步骤:
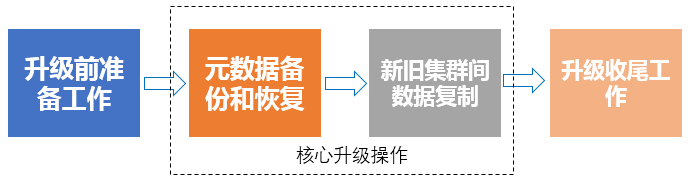
- 升级前准备工作
- Greenplum 4旧集群元数据备份和Greenplum 5新新集群元数据恢复
- Greenplum 4旧集群和Greenplum 5新集群间数据复制
- 升级后收尾保障工作
这里需要说明一下,因为Greenplum 5.X版本和Greenplum 4.X版本在元数据格式、用户数据存储格式等方面存在差异,无法采用数据库update的方式直接升级。我们需要采用新建一套Greenplum 5集群,再将旧集群数据复制到新集群的方式进行升级。
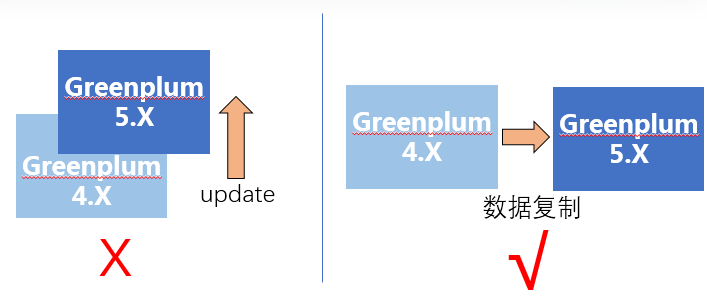
升级前准备工作
下面我们开始详细介绍升级前准备工作的内容,主要包括如下几点:
- 数据库运行状态信息收集
- 和应用沟通确认停机窗口
- 编写实施控制表和相关脚本并测试
- 生产环境硬件、软件环境检查及修复
1. 数据库运行状态信息收集
需要收集的信息包括:
- 服务器磁盘空间使用率、
- 数据库表数量、
- 视图数量、
- 索引数量comments等其他对象数。
通过收集和分析这些数据,我们能够对具体的升级方式以及升级所需要的时间作出判断:
- 如果数据节点服务器空间使用率低于45%,可以采用原地新建一套Greenplum 5.X版本集群的方式进行升级;如果数据节点服务器空间使用率高于45%,则建议采用在新服务器上新建一套Greenplum 5.X版本集群的方式进行升级。
- 数据节点服务器空间使用率越高,数据库表数量越多,元数据备份和恢复以及数据复制时间越长;反之则时间越短。
元数据备份和恢复所需时间案例:
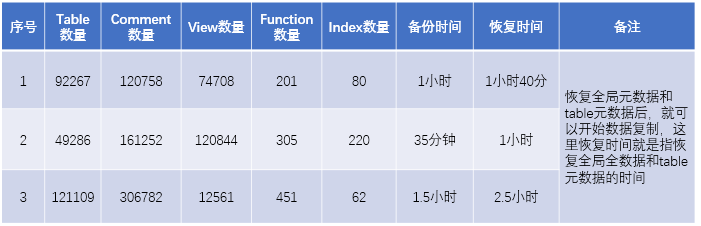
数据复制所需时间案例:
在公司生产环境下(每个raid卡8块,1.2TB或900GB的万转SAS磁盘,做RAID 5),分别采用官方工具gpcopy和公司研发的工具dbtool(这个后面会再详细说明)。


2. 和应用沟通确认停机窗口
通过集群运行状态信息的收集,我们就可以估算出待升级集群的升级所需时间数据。然后可以拿着这个数据,和应用沟通具体升级时间安排、停机窗口等
- 每个集群应用情况不同,但一般都会将升级时间放在晚上,特别是周五晚上,停机时间从24小时到48小时不等
- 前面所说,升级后部分应用可能存在无法正常运行的可能。如果这种情况发生,则有可能需要应用人员配合对应用脚本进行更改调整,遇到复杂的作业,可能还需要多方讨论确定调整方案。因此,需要通知相关应用人员,在升级前后随时待命介入。
3. 编写实施控制表和自动化脚本
生产环境的变更操作,是一件很严肃而且具有一定风险的事情。因此,我们需要编写详细可行的变更实施控制表。在进行变更时,严格按照实施控制表的步骤一步一步执行下去,防止误操作、漏操作对生产环境安全稳定运行造成的破坏。
当然,有时实施控制表的编写是一件很费时费力的工作。对于经常进行的变更,可以通过VBA进行实施控制表模板编写。编写完后,通过参数录入一键生成控制表,省时省心。
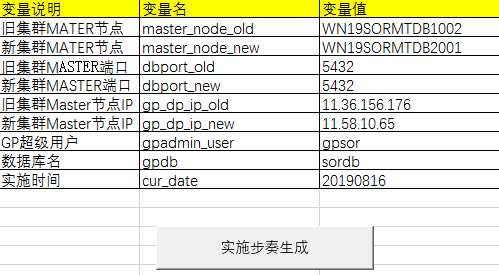
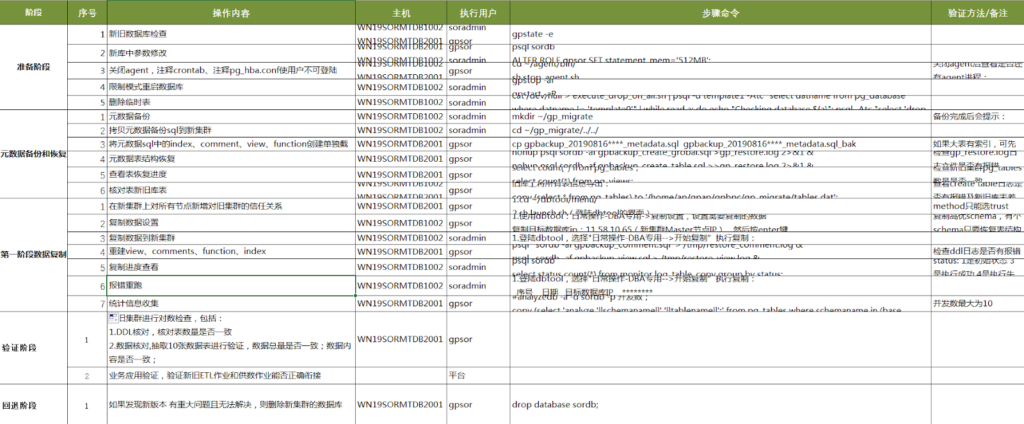
另外,自动化脚本的编写也同样重要。将所有需要用到的命令,事先准备好并脚本化,能够大大减少工作量,同时也是能够降低人工误操作的概率。在后面的元数据备份部门,我们会介绍下一个用于元数据备份文件拆分,多文件并行运行从而提供元数据恢复速率的简单脚本:metadata_seperate.sh
4. 生产环境硬件、软件环境检查及修复
准备工作的最后一项,也是非常决定升级操作能够顺利进行的一项:生产环境硬件、软件环境检查。
硬件环境检查
我们在数据复制过程中,曾遇到过多次硬件故障(磁盘、主板、CPU、网络等)问题,对数据复制效率造成了很大的影响:
- 磁盘或网络故障,导致数据复制效率低下
- 服务器自动重启,正在复制作业全部需要重跑
同时,服务器硬件的故障更换、RAID的恢复等操作又要耗费大量时间,这期间会造成数据库负载的严重倾斜,进一步降低了复制效率。
因此,数据复制前的硬件环境检查,是一件非常有必要而重要的事情。
进行硬件环境检查,可以参考如下几个方法:
- 通过gpcheckperf命令,检查所有服务器的硬件读写、网络I/O是否正常
- 借助gpssh工具,在所有服务器上检查/var/log/messages、/var/log/mcelog等日志是否存在报错;运行dmesg、lspci等命令看是否存在报错
- 借助专业的磁盘、RAID卡工具(LSI卡的megacli、惠普的ssacli、浪潮的arcconf等)
软件环境检查
软件环境检查,主要是检查数据库是否存在元数据问题。
$ nohup $GPHOME/bin/lib/gpcheckcat -v -B 48 -g
~/gpcheckcat_fix_script -p 5432 XXXdb > ~/gpcheckcat.log &
我们曾经遇到过,由于以前集群故障导致个别本该已经删除的表在一些实例上还有残留,进程导致元数据备份失败的问题。因此,在元数据备份前,进行一次详细的元数据检查是很有必要的。
根据集群的大小、对象数的不同,每次元数据检查一般在30分钟到2小时之间。如果检查出元数据有问题,则还需要针对问题进行修复,修复完后再进行一次元数据检查(只检查之前有问题的项)。因此,我们一般会在数据复制的前一天晚上,申请一次4到6小时的停机窗口,进行一次完整的元数据检查和修复。
(未完待续)
作者简介
陈晓新,建信金融科技有限责任公司厦门事业群,Greenplum数据库DBA,负责建行GP集群规划、搭建、运维、优化和技术研究等工作。

